Robust ASR Error Correction with Conservative Data Filtering


Overview
- This paper introduces a novel approach to Automatic Speech Recognition (ASR) error correction using conservative data filtering.
- The method focuses on training data quality by filtering out examples that might lead to incorrect corrections.
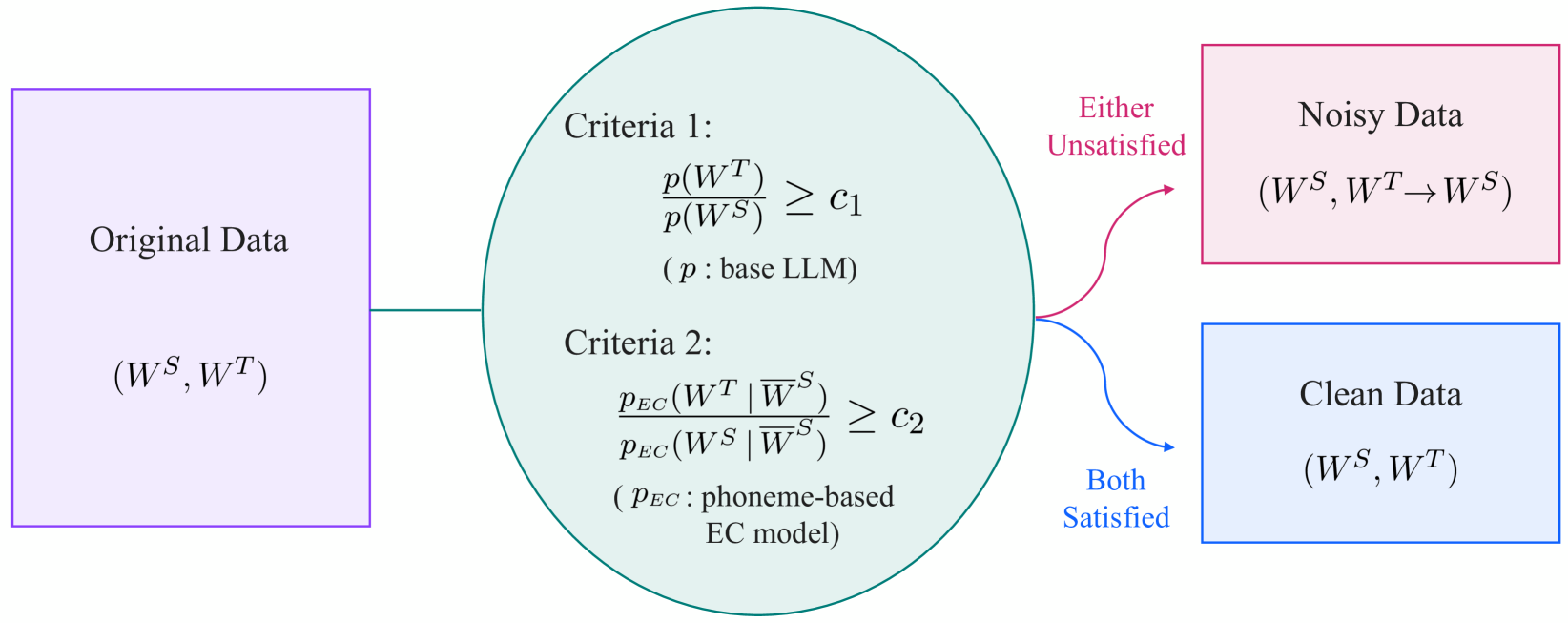
- Two filtering criteria are proposed: ensuring corrections improve linguistic acceptability and maintaining semantic similarity between the original and corrected text.
- Experiments demonstrate improved performance on ASR error correction tasks, particularly in robustness to noisy data.
Plain English Explanation
This paper improves ASR error correction by carefully selecting training data, leading to more accurate and reliable corrections.
ASR systems, while increasingly sophisticated, still make errors. Correcting these errors is crucial for many applications, from transcription services to voice assistants. However, current correction methods can sometimes introduce new errors or worsen existing ones, especially when the ASR output is very noisy. This is often due to issues with the training data used to teach the correction models. Imagine trying to learn grammar from a textbook full of mistakes – you might end up learning the wrong rules! Similarly, if an ASR error correction model is trained on data where the "corrections" are actually worse than the original errors, it won't be very effective. The existing approaches like the one in Error Correction by Paying Attention to Both often struggle in noisy environments.
This research addresses this problem by introducing a more cautious approach to training data selection. The idea is to filter the training data, keeping only the examples where the corrections genuinely improve the text. This is done by applying two main criteria: 1) Does the correction make the sentence grammatically more correct? 2) Does the correction preserve the original meaning of the sentence? By focusing on these two aspects, the model learns from high-quality examples and avoids being misled by bad corrections. This results in a more robust and reliable error correction system, even when the initial ASR output is full of errors. This conservative approach can complement efforts towards improving the underlying ASR models, such as those exploring Conformer-based Speech Recognition for Extreme Edge Computing. Furthermore, it could be beneficial in scenarios where the ASR system needs to continually learn new languages and the training data quality varies.
Key Findings
- Conservative data filtering significantly improves the performance of ASR error correction models, particularly in noisy conditions.
- The proposed method enhances the robustness of the correction system by focusing on linguistically and semantically sound training examples.
- Experiments show improvements in various evaluation metrics, indicating a reduction in both minor and major errors. These results align with the current understanding of the relationship between Accuracy, Training Data, and Model Outputs in Generative AI.
Technical Explanation
The paper proposes a novel filtering mechanism for training data used in ASR error correction. The core idea is to select only those training examples where the corrected sentence is both linguistically more acceptable and semantically similar to the original sentence. This addresses the problem of noisy training data, where incorrect corrections can negatively impact the model's performance. The first criterion, linguistic acceptability, is measured using language models that assess the grammatical correctness and fluency of a sentence. The second criterion, semantic similarity, is evaluated using sentence embedding techniques. This measures how well the meaning is preserved between the original and corrected sentences. This process ensures that the model learns from high-quality examples, leading to more accurate and reliable corrections. The experiments are conducted on standard ASR error correction datasets. The results demonstrate significant improvements across various evaluation metrics, particularly in scenarios with high error rates in the original ASR output. The conservative filtering approach is shown to be more effective than traditional methods, particularly in challenging, noisy environments.
Implications for the Field: This research contributes to the ongoing efforts in improving ASR error correction by addressing the crucial aspect of training data quality. The proposed method has the potential to lead to more robust and reliable ASR systems, which can have a wide range of applications in speech-based technologies.
Critical Analysis
While the paper presents a promising approach, there are some areas for further exploration. The reliance on language models and sentence embeddings for filtering introduces potential biases and limitations. The effectiveness of these tools might vary across different languages and domains. Additionally, the filtering process might inadvertently remove valuable training examples, especially in cases where the original sentence is highly ungrammatical but still conveys the intended meaning. Further research could investigate more sophisticated filtering strategies that account for these nuances. Another potential limitation lies in the computational cost of applying the filtering criteria, especially for large datasets. Exploring more efficient filtering methods could enhance the practicality of the approach. The focus on linguistic acceptability and semantic similarity, while crucial, might not fully capture the complexities of human language. Future work could investigate incorporating other factors, such as pragmatic considerations and contextual information, to further refine the filtering process.
The paper Robust ASR Error Correction with Conservative Data Filtering primarily focuses on correcting errors at the sentence level. However, errors in ASR often occur at the word or sub-word level. Investigating how this filtering approach can be adapted to handle these finer-grained errors would be beneficial. Finally, the paper's evaluation focuses on standard benchmark datasets. It would be valuable to assess the effectiveness of the method on real-world ASR data, which often presents greater variability and noise.
Conclusion
This research presents a valuable contribution to the field of ASR error correction by highlighting the importance of training data quality. The proposed conservative filtering method offers a promising approach to enhancing the robustness and reliability of ASR systems in noisy environments. While further research is needed to address certain limitations, the core idea of selectively filtering training data based on linguistic and semantic criteria holds significant potential for improving the accuracy and overall performance of ASR error correction technologies. This can lead to more seamless and effective integration of speech-based interfaces in various applications, impacting how we interact with technology in our daily lives.