Mergoo: Efficiently Build Your Own MoE LLM







Leeroo Team: Majid Yazdani, Alireza Mohammadshahi, Arshad Shaikh
We've recently developed mergoo, a library for easily merging multiple LLM experts, and efficiently train the merged LLM. Now, you can efficiently integrate the knowledge of different generic or domain-based LLM experts.
🚀 In mergoo, you can:
- Easily merge multiple open-source LLMs
- Apply many merging methods: Mixture-of-Experts, Mixture-of-Adapters, and Layer-wise merging
- Efficiently train a MoE without starting from scratch
- Compatible with Hugging Face 🤗 Models and Trainers

Content
Introduction
mergoo has been designed to build a reliable and transparent pipeline for merging the knowledge of various LLM experts, whether they are generic or domain-specific. It incorporates a range of integration techniques such as mixture-of-experts, mixture-of-adapters, and layer-wise merging, offering flexibility to LLM builders. Once the merged LLM is built, you can further fine-tune it for your specific use cases, using Hugging Face 🤗 Trainers such as SFTrainer, PEFT, Trainer, and more.
In the following sections, we outline two examples demonstrating how to build a merged LLM from fully fine-tuned LLMs using MoE, and how to create a mixture-of-adapter LLM from LoRA fine-tuned experts.
Mixture of Fully Fine-tuned LLMs
Following Branch-Train-Mix, Domain-specific LLM experts can be integrated by bringing together their feedforward parameters as experts in Mixture-of-Expert (MoE) layers and averaging the remaining parameters. MoE layers can be later fine-tuned to learn token-level routing.
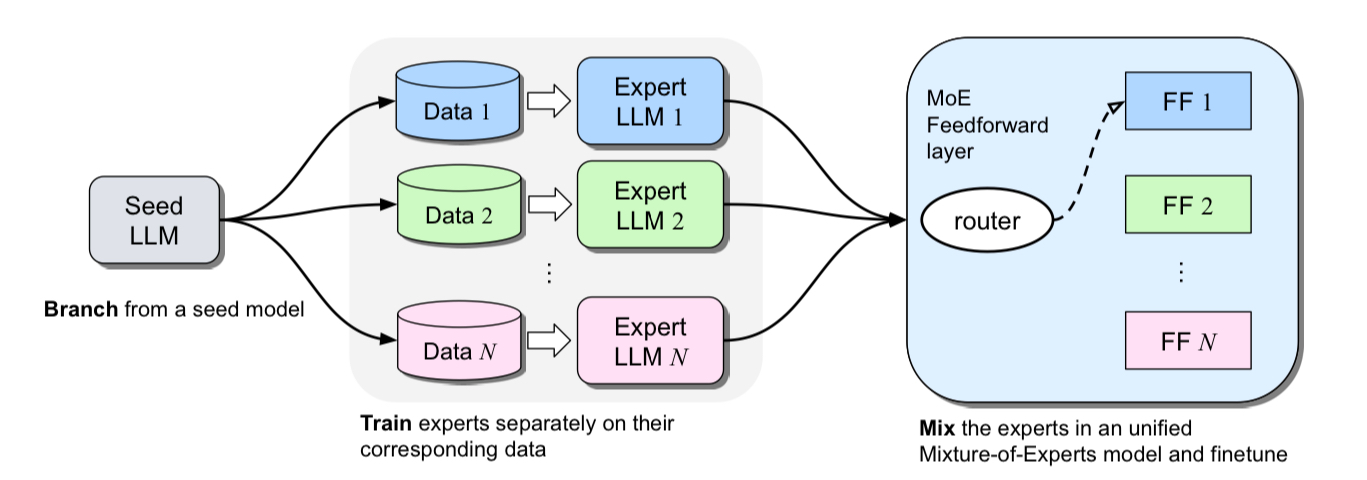
As a sample, we integrate the following domain-specific LLM experts:
- Base Model: meta-llama/Llama-2-7b-hf
- Code Expert: codellama/CodeLlama-7b-Python-hf
- WikiChat Expert: stanford-oval/Llama-2-7b-WikiChat-fused
Specifiy the config for merging:
config = \
{
"model_type": "llama",
"num_experts_per_tok": 2,
"experts":[
{
"expert_name" : "base_expert",
"model_id" : "meta-llama/Llama-2-7b-hf"
},
{
"expert_name" : "expert_1",
"model_id" : "codellama/CodeLlama-7b-Python-hf"
},
{
"expert_name" : "expert_2",
"model_id" : "stanford-oval/Llama-2-7b-WikiChat-fused"
}
],
"router_layers":[
"gate_proj",
"up_proj",
"down_proj"
],
}
Then, build the checkpoint of the merged expert, and save it:
import torch
from mergoo.compose_experts import ComposeExperts
model_id = "mergoo_llama_code_wikichat"
expertmerger = ComposeExperts(config, torch_dtype=torch.float16)
expertmerger.compose()
expertmerger.save_checkpoint(model_id)
In the following, the checkpoint of merged LLM is loaded, then further fine-tuned on Python Code Instruction dataset:
from mergoo.models.modeling_llama import LlamaForCausalLM
import torch
import datasets
import random
from trl import SFTTrainer
from transformers import TrainingArguments
# load the composed checkkpoint
model = LlamaForCausalLM.from_pretrained(
"mergoo_llama_code_wikichat",
device_map="auto",
torch_dtype=torch.bfloat16,
)# 'gate' / router layers are untrained hence loaded warning would appeare for them
# load the train dataset
dataset = datasets.load_dataset("iamtarun/python_code_instructions_18k_alpaca")['train']
dataset = dataset['prompt']
random.shuffle(dataset)
train_dataset = datasets.Dataset.from_dict(dict(prompt=dataset[:-1000]))
eval_dataset = datasets.Dataset.from_dict(dict(prompt=dataset[-1000:]))
# specify training arguments
trainer_args = TrainingArguments(
output_dir= "checkpoints/llama_moe",
per_device_train_batch_size = 1,
per_device_eval_batch_size = 1,
learning_rate= 1e-5,
save_total_limit=1,
num_train_epochs=1,
eval_steps= 5000,
logging_strategy="steps",
logging_steps= 25,
gradient_accumulation_steps=4,
bf16=True
)
trainer = SFTTrainer(
model,
args= trainer_args,
train_dataset= train_dataset,
eval_dataset= eval_dataset,
dataset_text_field="prompt",
)
# start training
trainer.train()
Then you can push the code to Huggingface Hub (please do!):
model.push_to_hub("mergoo_llama_code_wikichat_trained")
mergoo also supports mistral,bert, and phi3 based experts.
Mixture of Adapters
mergoo facilitates the merging of multiple adapters (LoRA) into a unified MoE-style architecture. This is achieved by applying gating and routing layers on top of fine-tuned LoRAs.
To build a mixture-of-adapters LLM:
- Collect a pool of fine-tuned adapters (LoRA) with the same base model
- Apply mergoo to create a MoE-style merged expert
- Fine-tune the merged expert on your downstream task
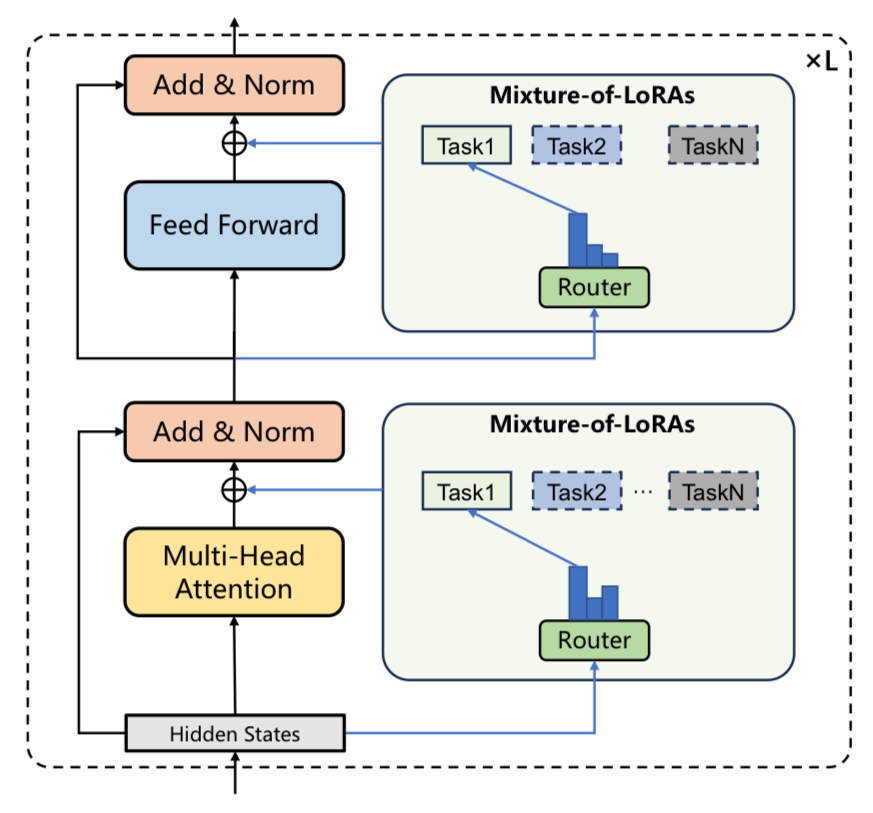
For instance, the following experts can be merged for the customer support domain:
Specify the config, and build the merged checkpoint, as:
import torch
from mergoo.compose_experts import ComposeExperts
model_id = "mergoo_customer_suppoer_moe_lora"
config = {
"model_type": "mistral",
"num_experts_per_tok": 2,
"base_model": "mistralai/Mistral-7B-v0.1",
"experts": [
{
"expert_name": "adapter_1",
"model_id": "predibase/customer_support"
},
{
"expert_name": "adapter_2",
"model_id": "predibase/customer_support_accounts"
},
{
"expert_name": "adapter_3",
"model_id": "predibase/customer_support_orders"
}
],
}
expertmerger = ComposeExperts(config, torch_dtype=torch.bfloat16)
expertmerger.compose()
expertmerger.save_checkpoint(model_id)
Note: when candidate experts for merging are fine-tuned with LoRA, expert_name starts with adapter_.
You can further fine-tune the merged expert as defined in Mixture of Fully Fine-tuned LLMs section.
Conclusion
mergoo can be used to reliably and transparently integrate the knowledge of multiple experts. It supports several intergation techniques including mixture-of-expert, mixture-of-adapters (MoE-LoRA), and layer-wise merging. The merged LLM can be further fine-tuned on the downstream task to provide a reliable expert.
Learn More
🔍 To a deeper dive into mergoo, please check our repository.
🌍 In Leeroo, our vision is to democratize AI for individuals everywhere, and open-sourcing is the foundational step toward realizing this vision. Join Leeroo, where we can work together to make this vision a reality!
Linkedin, Discord, X, Website.





