Is Prompt Caching the new RAG?


recently, Anthropic, the company behind Claude, has announced a remarkable new feature called Prompt Caching. This breakthrough development makes the processing of lengthy documents more affordable than ever before, and it has the potential to revolutionize how we handle vast amounts of static information in AI conversations!
Let's delve into the exciting implications this has for AI applications.
What is Prompt Caching?
Prompt Caching involves storing the system prompt --- the static part of the conversation. This system prompt can include substantial content such as entire books, long research papers, or large codebases. Here's how it works:
- The system prompt is cached on the first request, incurring a one-time cost.
- Subsequent user queries only process the dynamic user input against this cached context.
- This approach dramatically speeds up interactions and reduces costs for repeated queries.
Key Points About Prompt Caching
- System Prompt vs. User Input: The system prompt (static, cached) is separate from the user's input (dynamic, varies with each query).
- Initial Caching Cost: The first time you cache the system prompt, it costs approximately 25% more than standard input pricing.
- Subsequent Query Savings: After caching, processing new queries against the cached context costs only about 10% of the usual input pricing.
- Time Limitation: The cache lasts for 5 minutes. After this period, the system prompt needs to be cached again if you want to continue using it.
Examples
I made a Gradio app on HuggingFace with a simple chat interface that uses the new caching API.
In this example, I uploaded a comprehensive manual from a Github Repo (LLAMFactory) and asked some questions.
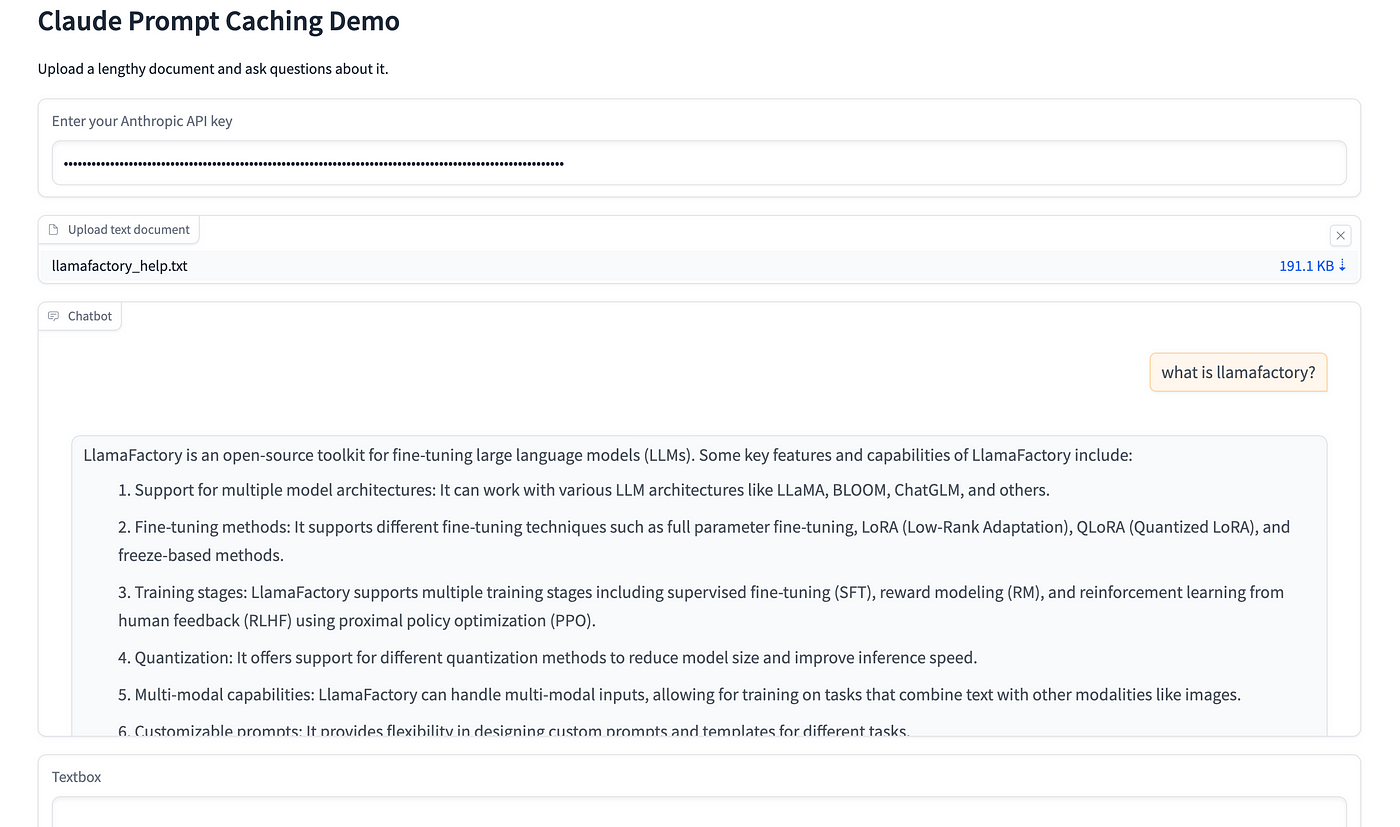
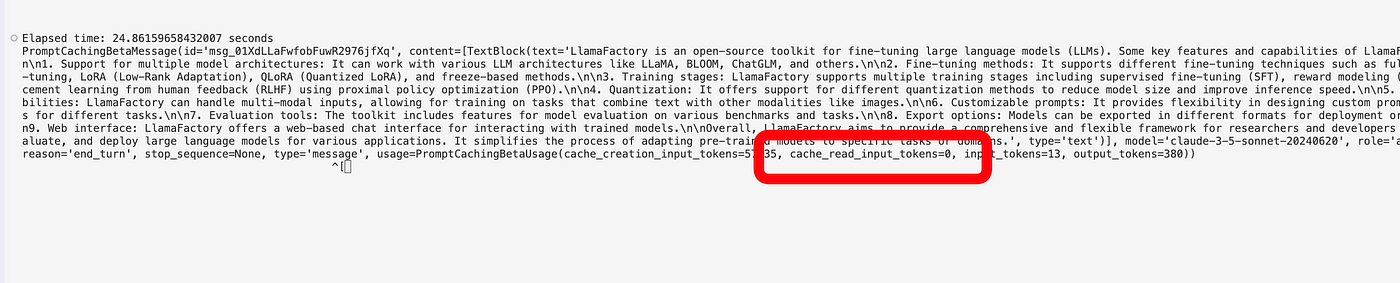
The system prompt is cached after the first question, so the cache is still zero.
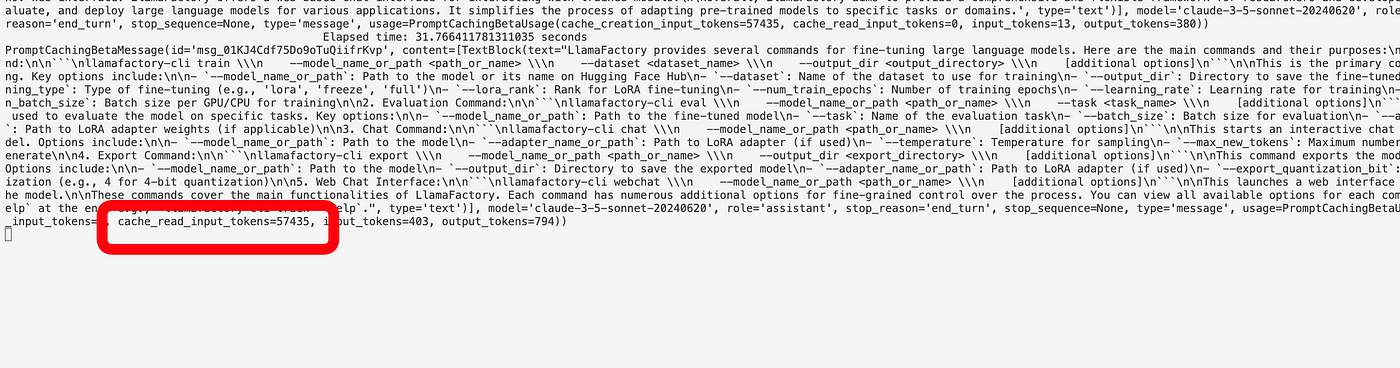
After that, the cached version is used, and the response is much faster and cheaper (10% of the usual cost for input tokens).
Possible Use Cases for Prompt Caching
- Document Analysis: Cache entire books or long documents. Users can ask multiple questions about the content without reprocessing the whole text each time.
- Code Review: Store large codebases in the cache. Developers can query about different parts of the code quickly and cheaply.
- Research Assistance: Cache comprehensive research papers or datasets. Researchers can explore various aspects of the data without repeated processing costs.
- Legal Document Processing: Store entire legal codes or case law databases. Lawyers can quickly query for relevant information at a fraction of the usual cost.
- Educational Tools: Cache textbooks or course materials. Students can ask numerous questions about the content, making interactive learning more feasible and affordable.
Please note that there are some limitations to keep in mind with prompt caching. The cache only remains valid for 5 minutes, and it's not yet compatible with all Claude models.
Conclusion
Prompt Caching is a major step forward in making AI interactions more efficient and cost-effective, particularly in applications dealing with large, static datasets. By dramatically cutting the time and cost of subsequent queries, it unlocks new possibilities for AI-driven analysis, learning, and information processing across various industries.