Announcing Finance Commons and the Bad Data Toolbox: Pioneering Open Data and Advanced Document Processing







We are excited to announce the simultaneous release of Finance Commons, the largest collection of financial documents in open data made of 17 billion tokens, and the “Bad Data Toolbox”, our first suite of language models excelling at processing challenging documents and optimizing their use in LLMops.
How we stopped caring and started training on bad data
In the last year, the use of generative AI in regulated, information-intensive domains has been widely desired but rarely as successful as one would have hoped. Badly structured or formatted data is often the main culprit. Until now Language models have been mostly trained on web-based data, increasingly filtered for quality and text cleanliness. Applied LLM systems, like RAG, have repeatedly struggled with the integration of PDF sources. Nested tables, multi-column structures, OCR errors, broken text flows and mixed visual and textual information pose significant challenges for retrieval and LLM comprehension.
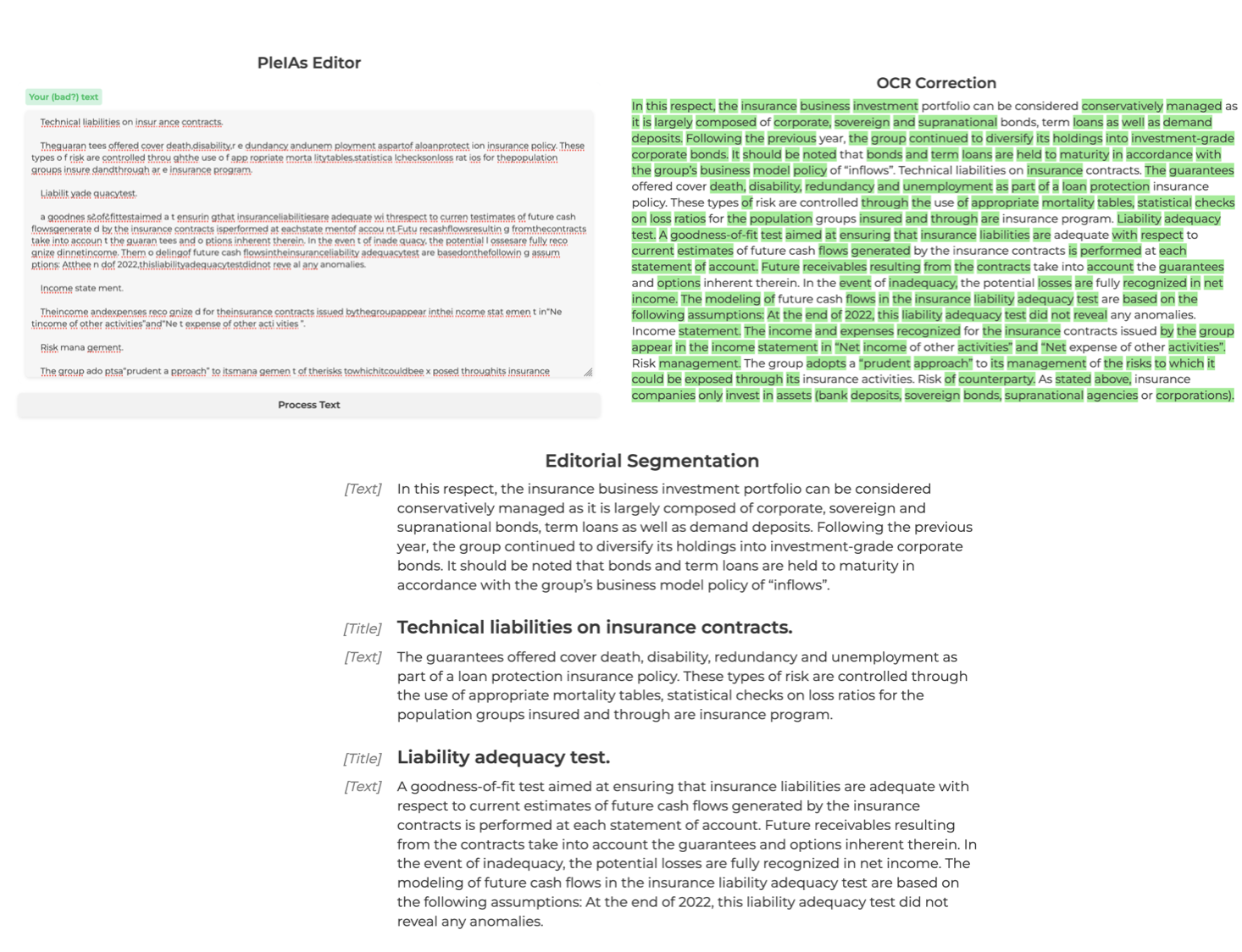
Going against the current consensus on quality data, we have voluntarily trained our new series of model on bad data including imperfect OCR, broken texts with mangled words and ambiguous structure. Our overall philosophy is that organizations should have to work to prepare their content for LLMops and other AI applications. If AI is as good as claimed to automate processes, AI should take care of itself.

Our Bad Data Toolbox features multiple models trained with unprecedented robustness over bad data. Preliminary results show that language models can be be used "as is" on many documents without little if any pre-processing. We release three models on "frontier" tasks, unexplored until now despite their prevalence in corporate setting and their newfound relevance for LLMops applications:
- OCronos: a decoder model for OCR correction
- Segmentext: an encoder model for text segmentation.
- Bibtexer: an encoder model for structured bibliographic extraction
We additionally publish two spaces with the generous compute support from HuggingFace:
- PleIAs-Editor, an integrated pipeline to make bad text usable for RAG and other advanced retrieval application.
- Reversed-Zotero, an automated conversion tool of unstructured bibliographies into BibTex data that can be opened in Zotero.
Future releases will also focus on the generation of bad data, as the creation of synthetic data closer to sources actually used in production is proving critical for the development of robust LLM and embedding models.
A real life resource for Document AI: Finance Commons Dataset
To address the challenges of bringing Document AI research closer to the challenges met in production, we are introducing Finance Commons:
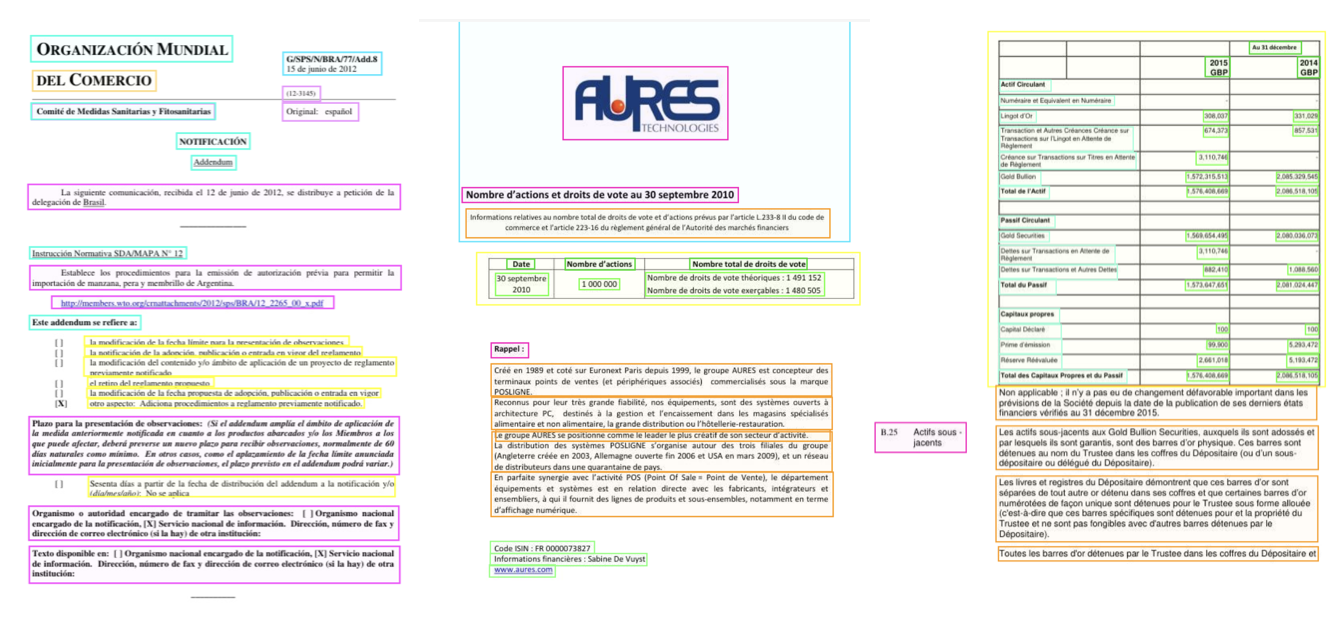
- Multimodal: This dataset is one of the largest and most diverse open sets of multimodal documents, encompassing 1.25 million original PDF documents from the AMF and WTO, produced by a wide range of corporate actors. The documents include a wide coverage of in-house layouts and formats produced by industrial and economic sectors.
- Wide time coverage until 2024: It currently includes all annual financial statements and reports submitted until 2024 the Securities and Exchange Commission (SEC) and the French Authority for Financial Market (AMF), as well as historical archives of the World Trade Association (WTO) and EU tenders submitted to the TED platform. We plan to expand the coverage to other countries and institutions over the coming months.
- Open Data: All theses documents have been made accessible on open data platforms and can be used to support open research.
- Support for Next-Gen Models: The dataset aims to support the next generation of multimodal document models by providing varied layouts and challenges.

The complete FInance Commons dataset can be explored on the dedicated space on HuggingFace.
| Dataset | # Documents | # Words (in B) |
|---|---|---|
| WTO | 642,627 | 1.68 |
| SEC | 245,211 | 7.25 |
| AMF | 610,989 | 4.7 |
| GATT | 60,182 | 0.1 |
| EU Tenders | 224,049 | 0.3 |
Will we solve PDF parsing before AGI?
We have recently seen an acceleration of research and innovation in document processing in AI, with a new generation of visual language models showing unprecedented performance for text segmentation (Florence), retrieval (ColPali), and overall document understanding (Surya).
Our release of Finance Commons and the Bad Data Toolbox aims to support these efforts and provide companies with fully open, qualitative, and expert data. This initiative is part of PleIAs' global commitment to creating large open training datasets for AI research. In March 2024, we coordinated the release of Common Corpus, the largest open pretraining dataset comprising 500 billion words from public domain collections. We believe that open datasets are critical to supporting open research in AI, ensuring reproducible and collaborative work, and enhancing public acceptability of new technology, especially in regulated contexts.





