LLM Data Engineering 3——Data Collection Magic: Acquiring Top Training Data




This article is part of the DataTager team's 100,000-word summary series on large model data, titled "From Data to AGI: Unlocking the Secrets of Large Model Intelligence." Below is the link to access the article synchronously:
https://huggingface.co/blog/JessyTsu1/data-collect-zh
https://datatager.com/blog/data_collect
https://zhuanlan.zhihu.com/p/700613165
More than a year after the advent of ChatGPT, people have gradually understood the operational logic of large models and are actively exploring their application scenarios. We firmly believe that the field of large models is data-centric, not model-centric. Therefore, in the exploration of the era of large models, we have accumulated a wealth of experience and insights about data, which we have compiled into the series "From Data to AGI: Unlocking the Secrets of Large Language Models." Based on these experiences, we have also developed the product DataTager, which will be launched soon.
The role of data in large models is indisputable. Collecting data reasonably and choosing which data to collect are very important topics. Next, we will explore several major data collection methods in detail, analyzing their advantages, disadvantages, and practical applications.
I. Web Crawling
When we find suitable data on a website, the first thought is to download all of it to our local system for model training, hence the use of web crawlers.
Concepts and Principles
- Web crawlers are automated programs that systematically browse and extract data from the internet. They simulate user behavior to access web pages and retrieve the necessary information.
Advantages
- Large-scale data acquisition: Web crawlers can obtain massive amounts of data from numerous websites, providing rich corpora for model training.
- High-frequency updates: Crawlers can regularly fetch the latest data, ensuring the timeliness and freshness of the data.
Traditional Tools
- Scrapy: A powerful Python web crawling framework suitable for large-scale crawling projects.
- Features: Modular design, supports multi-threading, and has strong scraping and processing capabilities.
- Use Cases: Suitable for extracting large amounts of data from websites, such as e-commerce platforms and news portals.
pip install scrapy
cat > myspider.py <<EOF
import scrapy
class BlogSpider(scrapy.Spider):
name = 'blogspider'
start_urls = ['https://www.zyte.com/blog/']
def parse(self, response):
for title in response.css('.oxy-post-title'):
yield {'title': title.css('::text').get()}
for next_page in response.css('a.next'):
yield response.follow(next_page, self.parse)
EOF
scrapy runspider myspider.py
Beautiful Soup: A Python library for parsing HTML and XML documents, suitable for small-scale data scraping.
- Features: Easy to learn and use, can quickly parse and process HTML content.
- Use Cases: Suitable for websites with simple structures and smaller data volumes.
Selenium: A tool for automating web browsing, capable of handling dynamically loaded web page content.
- Features: Supports JavaScript rendering, can simulate user actions.
- Use Cases: Suitable for websites that need to handle dynamic content, such as pages with real-time data updates.
New AI Crawlers
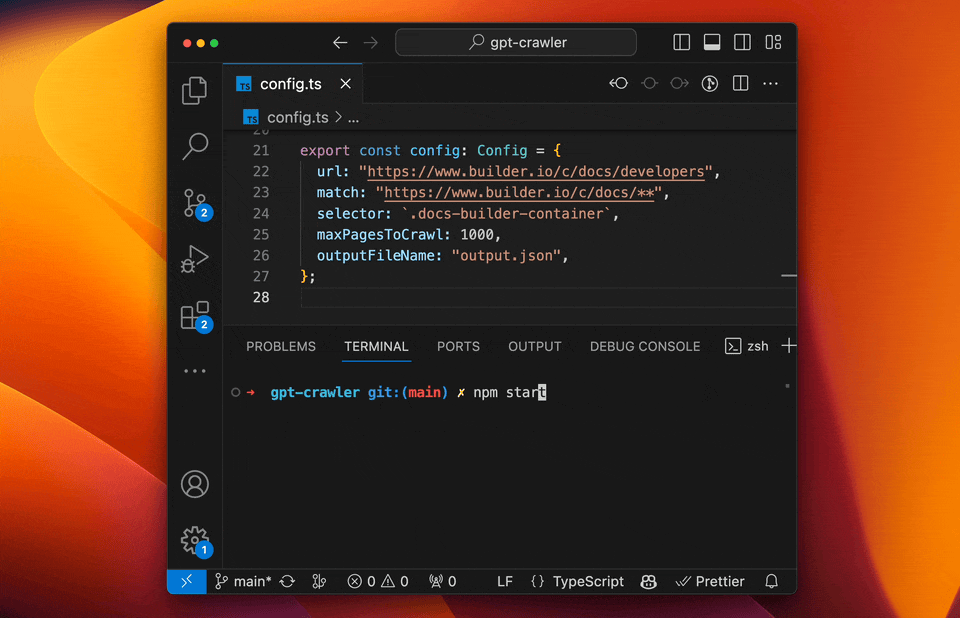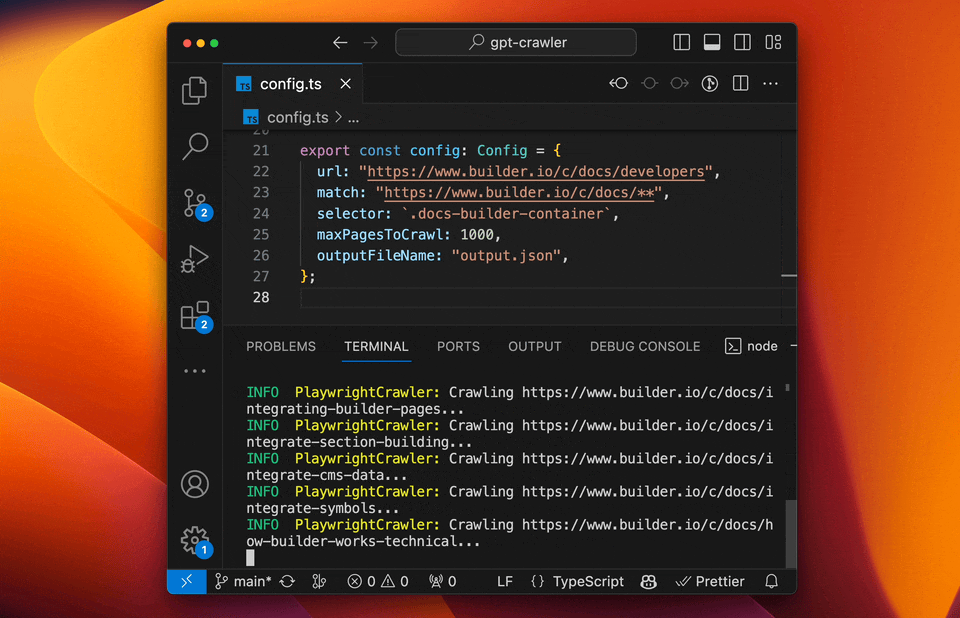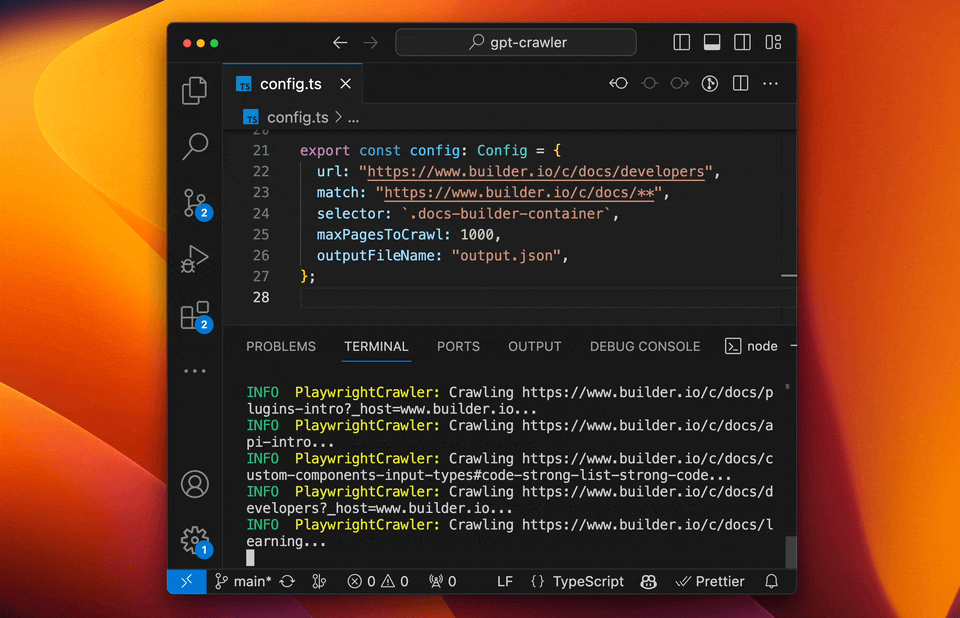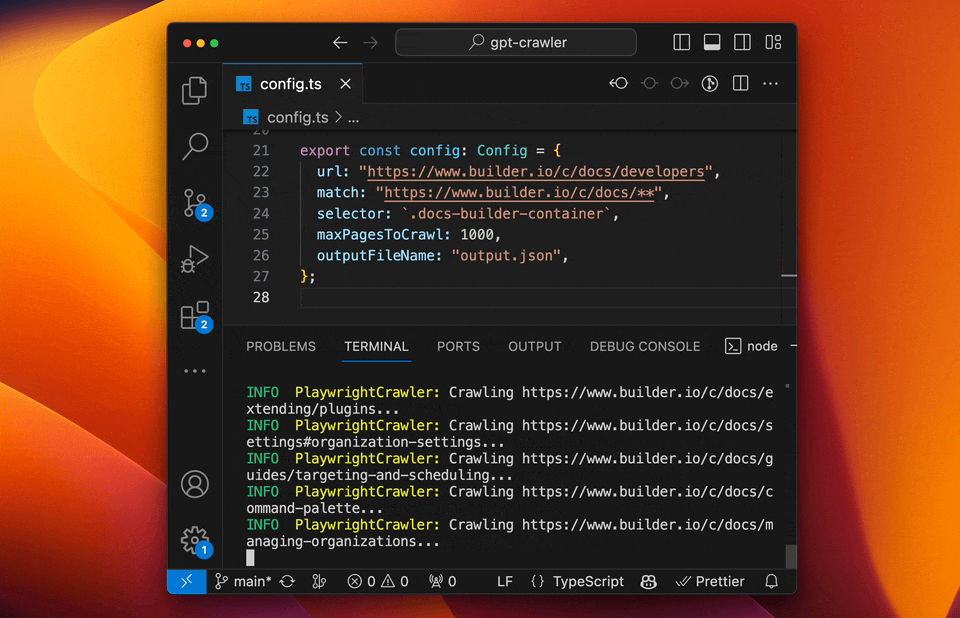
- GPT-Crawler (BuilderIO): A crawler tool that integrates the capabilities of GPT-3, capable of understanding and processing complex web structures.
- Features: Strong natural language processing capabilities, high automation, and context understanding.
- Use Cases: Suitable for websites with complex structures and those requiring deep understanding.
- Example: Using GPT-Crawler to scrape technology blogs, automatically categorizing and summarizing content.
- Scrapegraph-AI (VinciGit00): Utilizes graph neural networks for data extraction, suitable for complex data integration.
- Features: Handles complex relational data, efficiently integrates data from multiple sources.
- Use Cases: Suitable for websites needing to extract relational information from multiple data sources.
- Example: Using Scrapegraph-AI to scrape social network data, analyzing user relationships and interactions.

- MarkdownDown: Specializes in generating structured Markdown files from web content, facilitating data organization and usage.
- Features: Generates structured documents, easy to edit and share.
- Use Cases: Suitable for websites that need to convert web content into readable documents.
- Example: Using MarkdownDown to scrape technical documentation websites, converting content into Markdown files for internal use.

- Jina Reader: Uses AI technology to extract and summarize key information from web pages, enhancing the efficiency and accuracy of data collection.
- Features: Automated information extraction, intelligent summarization.
- Use Cases: Suitable for websites that need to quickly gather and summarize information.
- Example: Using Jina Reader to scrape financial news websites, extracting and summarizing market dynamics.

| Category | Scrapy | Beautiful Soup | Selenium | GPT-Crawler | Scrapegraph-AI | MarkdownDown | Jina Reader |
|---|---|---|---|---|---|---|---|
| Concepts and Principles | A powerful Python web crawling framework suitable for large-scale crawling projects. | A Python library for parsing HTML and XML documents, suitable for small-scale data scraping. | A tool for automating web browsing, capable of handling dynamically loaded web page content. | A crawler tool combining GPT-3 capabilities, capable of understanding and processing complex web structures. | Utilizes graph neural networks for data extraction, suitable for complex data integration. | Specializes in generating structured Markdown files from web content, facilitating data organization and usage. | Uses AI technology to extract and summarize key information from web pages, enhancing the efficiency and accuracy of data collection. |
| Advantages | Modular design, supports multi-threading, strong scraping and processing capabilities. | Easy to learn and use, quickly parses and handles HTML content. | Supports JavaScript rendering, can simulate user actions. | Strong natural language processing capabilities, high automation, and context understanding. | Handles complex relational data, efficiently integrates data from multiple sources. | Generates structured documents, easy to edit and share. | Automated information extraction, intelligent summarization. |
| Disadvantages | Requires writing extensive code, not beginner-friendly. | Low efficiency in processing large-scale data, does not support asynchronous operations. | Slow and resource-intensive. | May require more computational resources and preliminary configuration. | Technically complex, high initial learning cost. | Only suitable for extracting data in specific formats. | Depends on the accuracy and performance of AI models. |
| Use Cases | Large-scale data scraping, e.g., e-commerce, news portals. | Websites with simple structures and smaller data volumes. | Dynamic content websites, e.g., pages with real-time data updates. | Websites with complex structures and those requiring deep understanding. | Data extraction and integration from multiple sources. | Websites that need to convert web content into readable documents. | Websites that need to quickly gather and summarize information. |
| Actual Examples | Using Scrapy to scrape Amazon product data to analyze market trends. | Using Beautiful Soup to scrape blog post content for text analysis. | Using Selenium to scrape dynamically loaded news websites to obtain the latest news articles. | Using GPT-Crawler to scrape technology blogs, automatically categorizing and summarizing content. | Using Scrapegraph-AI to scrape social network data, analyzing user relationships and interactions. | Using MarkdownDown to scrape technical documentation websites, converting content into Markdown files for internal use. | Using Jina Reader to scrape financial news websites, extracting and summarizing market dynamics. |
Traditional Crawlers vs. New AI Crawlers
| Category | Traditional Crawling Tools | New AI Crawling Tools |
|---|---|---|
| Understanding | Dependent on predefined rules and structures, handling complex web pages may be difficult. Advantage: Efficiently handles simple web pages. Disadvantage: Limited ability to handle complex or dynamic content, requires manual configuration. |
Utilizes NLP and graph neural networks to better understand complex web structures. Advantage: Strong understanding, can automatically adjust scraping strategies. Disadvantage: May require more computational resources and preliminary configuration. |
| Flexibility | Requires manual coding to handle different types of web pages, low flexibility. Advantage: High execution efficiency after specific task optimization. Disadvantage: Difficult to adapt to new types of websites or structural changes. |
High adaptability, can automatically adjust scraping strategies based on web content. Advantage: Flexibly handles different websites and content structures. Disadvantage: Initial setup and training time can be lengthy. |
| Efficiency | High efficiency in processing large-scale data, but requires extensive upfront configuration. Advantage: Efficiently handles data with known structures. Disadvantage: Large amount of upfront configuration work, difficult to cope with structural changes. |
Intelligent analysis and automated processes enhance data scraping efficiency and accuracy. Advantage: High degree of automation, reduces manual intervention. Disadvantage: Requires more resources during operation. |
| Usability | Requires writing and maintaining extensive code, steep learning curve. Advantage: Rich technical documentation and community support. Disadvantage: Not beginner-friendly, requires upfront configuration and ongoing maintenance. |
Provides user-friendly interfaces and automated features, lowering the barrier to entry. Advantage: Easy to start, reduces coding requirements. Disadvantage: Needs to understand complex AI models and configurations. |
| Cost | Open-source tools are usually free, but require extensive development and maintenance resources. Advantage: Low usage costs. Disadvantage: High hidden costs (such as development time and maintenance). |
May require payment for use or subscription services, especially for commercial solutions. Advantage: Lowers development and maintenance costs. Disadvantage: High initial investment. |
| Suitability | Suitable for websites with known structures and rules, especially static web pages. Advantage: Efficiently scrapes stable-structure websites. Disadvantage: Poor adaptability to dynamic or frequently changing websites. |
Suitable for complex structures and dynamic content websites, automatically adapts and adjusts scraping strategies. Advantage: Applicable to various types of websites. Disadvantage: May be overly complex for simple structure websites. |
| Legal and Ethical | Manual compliance with data privacy laws and website scraping rules is necessary. Advantage: Clear legal boundaries. Disadvantage: Requires extensive manual checking and adjustment. |
Built-in compliance checks and privacy protection features, automatically adhering to legal and ethical standards. Advantage: Reduces legal risks and ethical issues. Disadvantage: Dependent on tool compliance. |
Legal and Ethical Considerations
a. Data Privacy Issues
When conducting data scraping, data privacy is a critical factor to consider. With increasing global attention on data privacy, various countries have introduced related laws and regulations, such as the General Data Protection Regulation (GDPR) in the EU and the California Consumer Privacy Act (CCPA) in the USA. These regulations aim to protect user privacy by preventing unauthorized collection and use of personal data.
- Compliance with Privacy Regulations: When scraping data, it is essential to comply with the privacy regulations of the respective country or region. For example, avoid collecting data that contains Personal Identifiable Information (PII) or obtain explicit consent from users when necessary.
- Data Anonymization and De-identification: Anonymize and de-identify collected data to protect user privacy. Ensure that no personal information can be traced back to an individual during data processing and storage.
b. Adherence to the robots.txt Protocol
robots.txt is a text file used to tell search engines and other crawlers which pages can be scraped and which cannot. Website administrators define crawler access rules by placing a robots.txt file in the root directory of their websites.
- Read and Follow the robots.txt File: Before scraping data, crawlers should first read the target website's robots.txt file and adhere to the defined scraping rules. This not only helps to avoid burdening the target site but also respects the wishes of website administrators.
- Load Management: Set the crawling frequency reasonably to avoid overloading the target website's server. Use the delay settings feature in the crawler framework to control the scraping speed and minimize the impact on the website.
c. How to Avoid Other AI Companies' Crawlers
The website https://darkvisitors.com/ lists the User Agents used by major AI companies' crawlers and tells you how to block these crawlers in your robots.txt file.
Practical Use
Five years ago, when I was with Sina and Sohu, we had a department for a massive distributed crawler system, which covered virtually all issues a crawler might encounter. Thus, I also have extensive experience in this field, which I share here to inspire others.
The core of a crawler is to simulate all human actions and then automate them.
1. How to Build a Universal AI Crawler
(The code for this section can be viewed here: https://github.com/PandaVT/DataTager/blob/main/blog_code/ai_crawler.py)
There's a principle in code engineering: abstraction.
Why talk about abstraction?
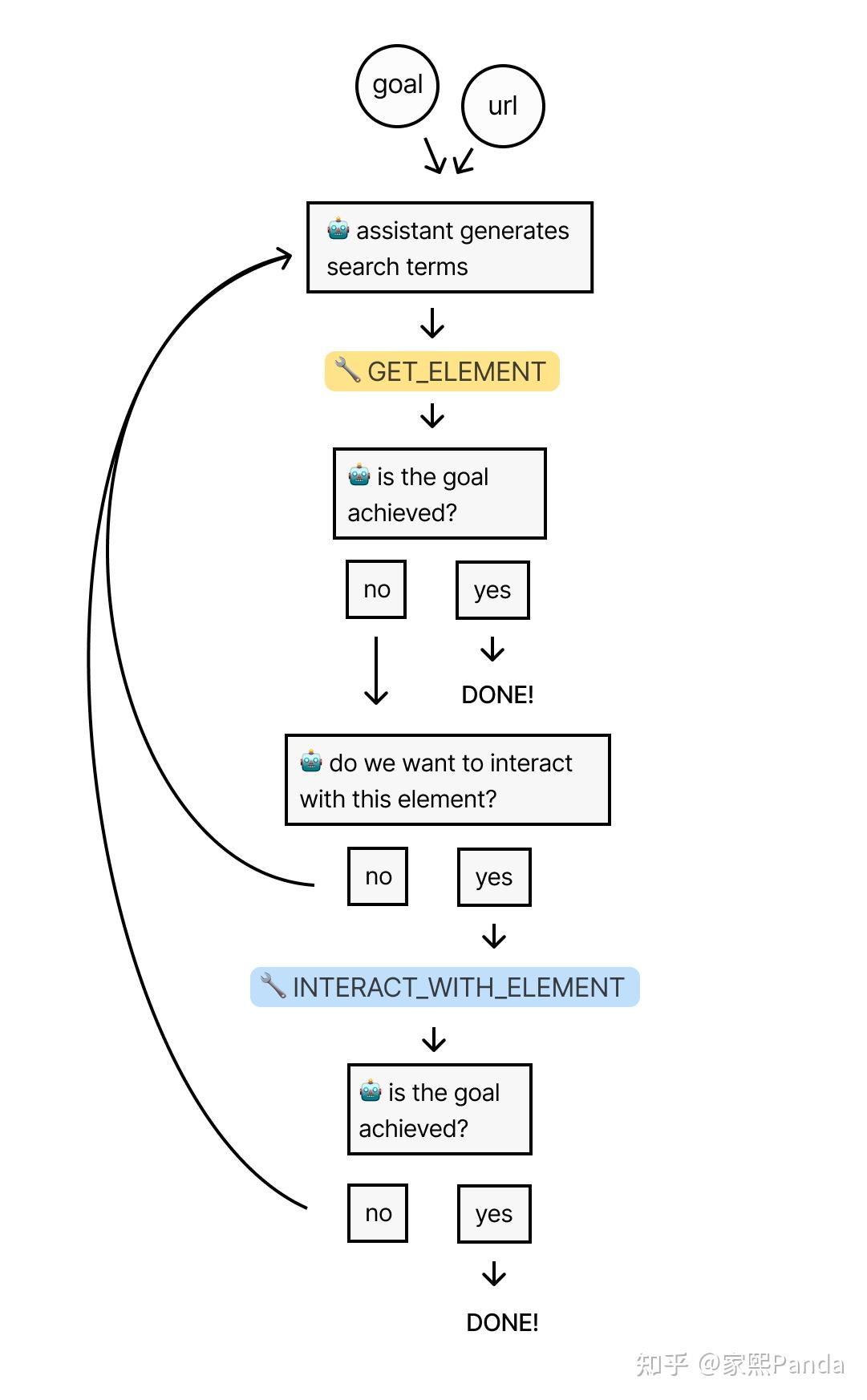
Building a universal AI crawler seems like a grand and technically challenging task, which can feel overwhelming. So, we can start by setting aside the perceived difficulty of the concept and consider the following problem-solving logic:
a.What should be the input and output of this problem?
After some thought, it's clear:
input: target website URL, content to scrape
output: file containing the scraped content
This preliminary definition helps us consider:
b.Can we get the output directly from the input?
It sounds challenging because there isn't a straightforward method to directly convert this input into output, and there are several other complex steps in between. The next question is:
c.What are the steps in between, and what are the input and output for each step?
From here, we can outline a clear logic chain:
step1: fetch_html.py
input: target website URL
output: HTML content of the target website
step2: parse_content.py
input: HTML content of the target website + content to scrape
output: Specific data parsed (such as text, images, etc.)
step3: process_data.py
input: Specific data parsed (such as text, images, etc.)
output: Further processing of the data, such as text cleaning, format standardization, etc.
step4: save_data.py
input: Processed data
output: Saved file
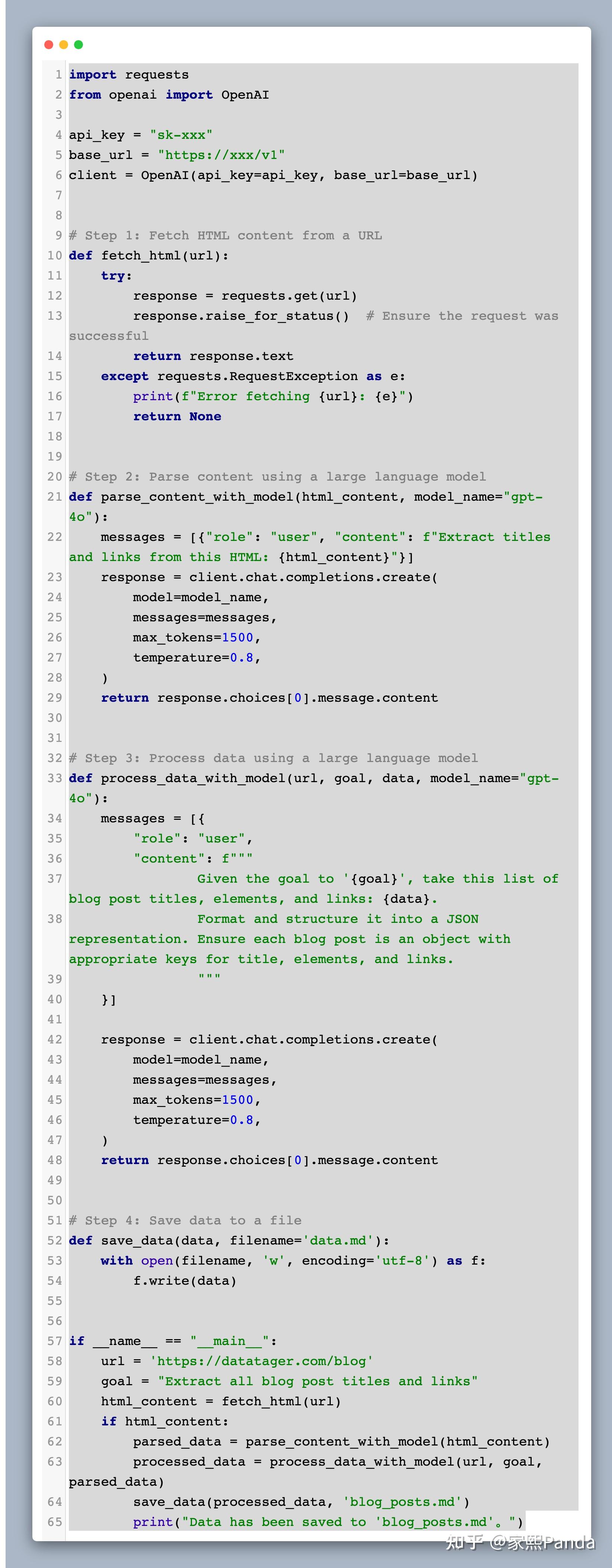
Taking https://datatager.com/blog as an example, how were steps 1-4 executed?
Step 1: fetch_html.py
First, we need a function that can fetch HTML content from a given URL.
import requests
def fetch_html(url):
try:
response = requests.get(url)
response.raise_for_status()
return response.text
except requests.RequestException as e:
print(f"Error fetching {url}: {e}")
return None
Step 2: parse_content.py
Next, parse the HTML content to find all blog article titles and links.
from bs4 import BeautifulSoup
def parse_content(html_content):
soup = BeautifulSoup(html_content, 'html.parser')
articles = soup.find_all('h2', class_='entry-title') # Assume titles are within <h2 class="entry-title"> tags
data = []
for article in articles:
title = article.find('a').get_text() # Extract the text of the title
link = article.find('a')['href'] # Extract the link
data.append({'title': title, 'link': link})
return data
Step 3: process_data.py
This step could be used to further process the data, such as simplifying or formatting. In this example, we might not need complex processing.
def clean_text(text):
# Simple text cleaning logic
cleaned_text = text.replace('\n', ' ').strip()
return cleaned_text
def process_data(data):
return [clean_text(text) for text in data]
Step 4: save_data.py
Finally, we need a function to save the data to a file.
import json
def save_data(data, filename='data.json'):
with open(filename, 'w', encoding='utf-8') as f:
json.dump(data, f, indent=4, ensure_ascii=False)
Main Function
Finally, we can combine these steps to run the complete crawler.
if name == "__main__":
url = 'https://datatager.com/blog'
html_content = fetch_html(url)
if html_content:
parsed_data = parse_content(html_content)
processed_data = process_data(parsed_data)
save_data(processed_data, 'blog_posts.json')
print("Data has been saved to 'blog_posts.json'。")
What can AI enhance?
So when we scrape https://datatager.com/blog, essentially, we are storing the website's HTML and then parsing it to extract the content we want.
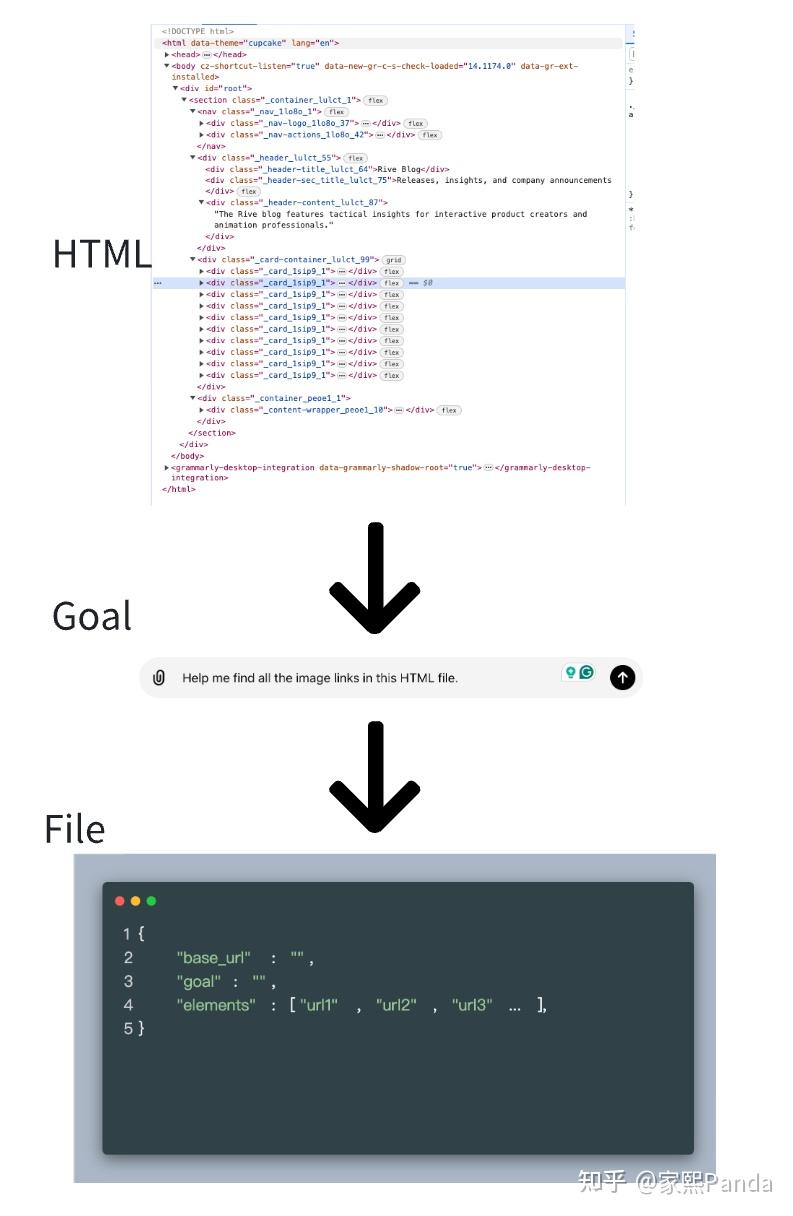
Previously, in step 2, we used XPath, CSS selectors, and regular expressions to extract desired elements from HTML.
In step 3, data processing involved simple replace functions, regular expressions, or basic models like BERT or word2vec.
Both of these steps essentially involve tasks related to language understanding, and now we can leverage the natural and powerful language understanding abilities of LLMs to accomplish these tasks.
Of course, there are many details missing here, and a practical, operational project would require much more. However, the above three-step abstraction method can effectively solve complex logical engineering problems. This also forms the prototype of a general AI crawler.
Here is the basic code for this section, which can already run and achieve decent results. Those interested can expand upon this code prototype: https://github.com/PandaVT/DataTager/blob/main/blog_code/ai_crawler.py
2. Traditional Crawlers and Scrapy Usage (Example from a School Database)
PS: Since the first part already detailed the crawler process, the following sections will only briefly introduce them.
For detailed code, please visit: https://github.com/JessyTsu1/Primary_students
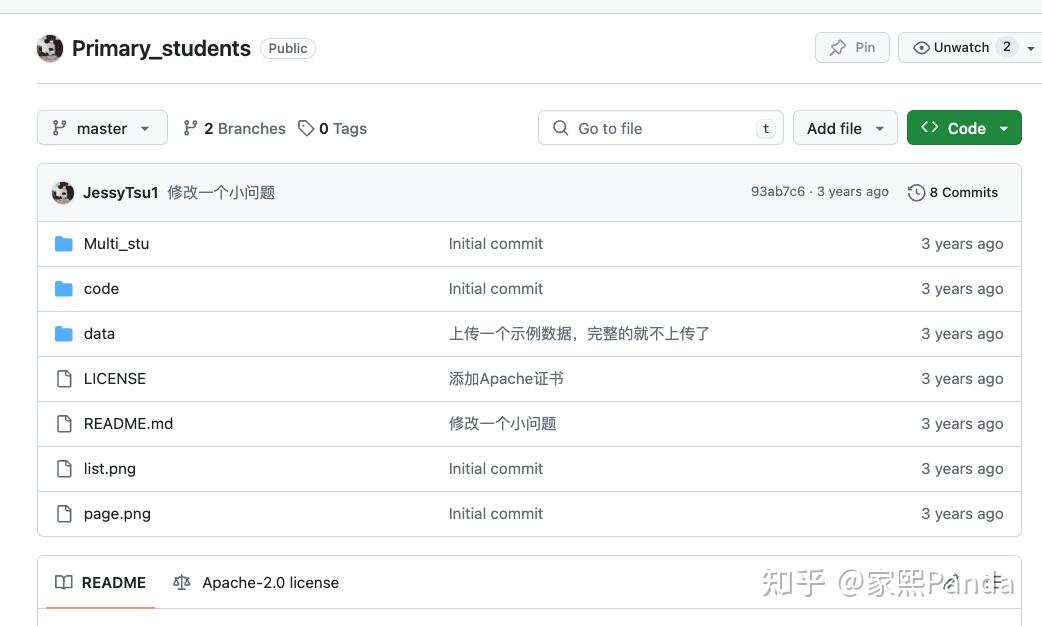
Code Structure
codefolder: Contains preliminary and simple analysis code.datafolder: Contains the final data and processing scripts.Multi_stufolder: Uses Scrapy for crawling.
Briefly Write a Crawler to Understand the Requirements and Approach
- Detail page URL: https://school.wjszx.com.cn/senior/list.html
- URL for each page: https://school.wjszx.com.cn/senior/introduce-2.html
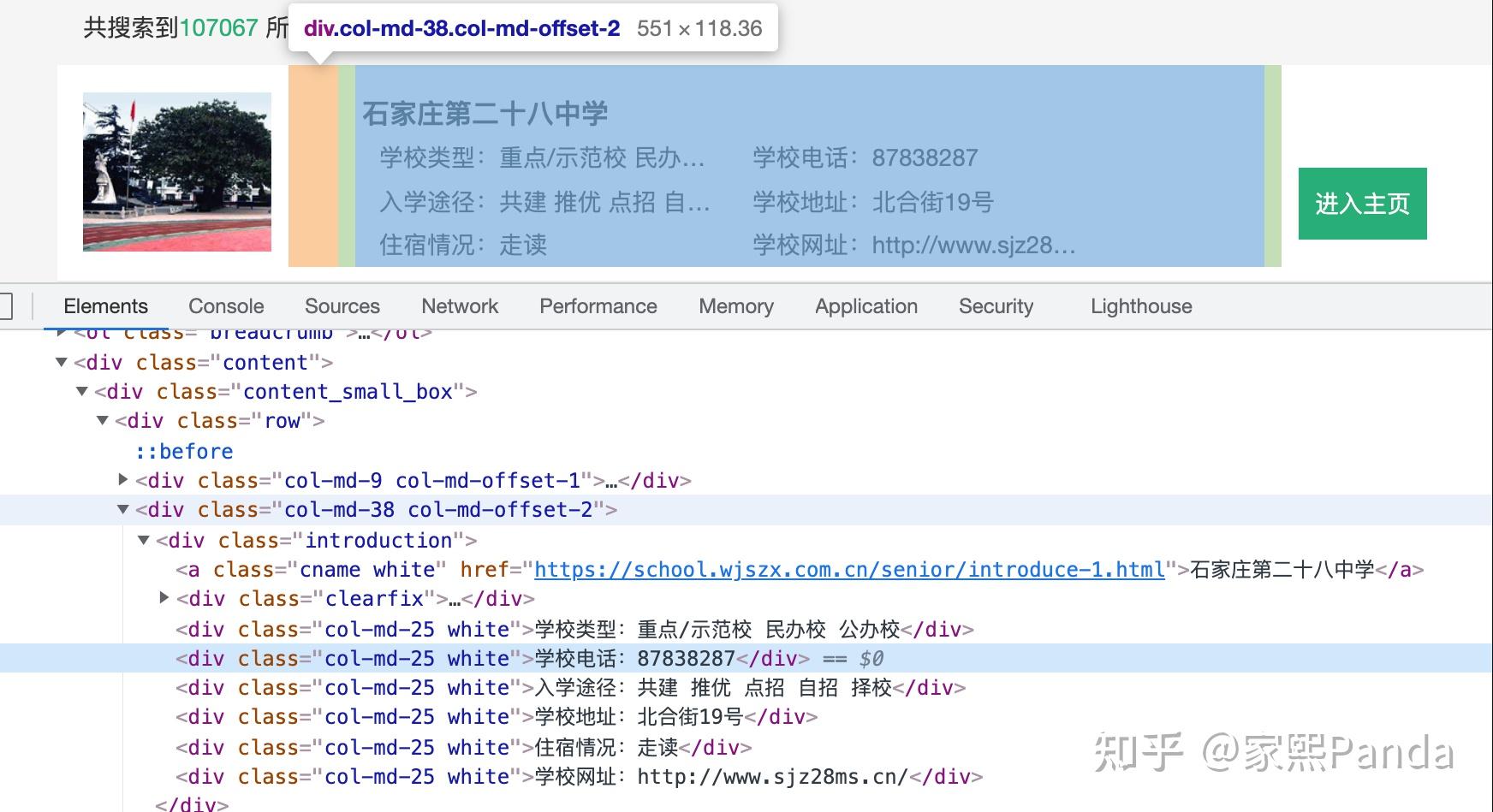
- Code of the directory page, where each tag is not titled, which might lead to errors later, so it's not advisable to use directory scraping.
- Structure of the detail page: The design is quite rudimentary... each field's title is directly assigned as a variable, so it's sufficient to directly scrape the title name, without needing to process the fields further.
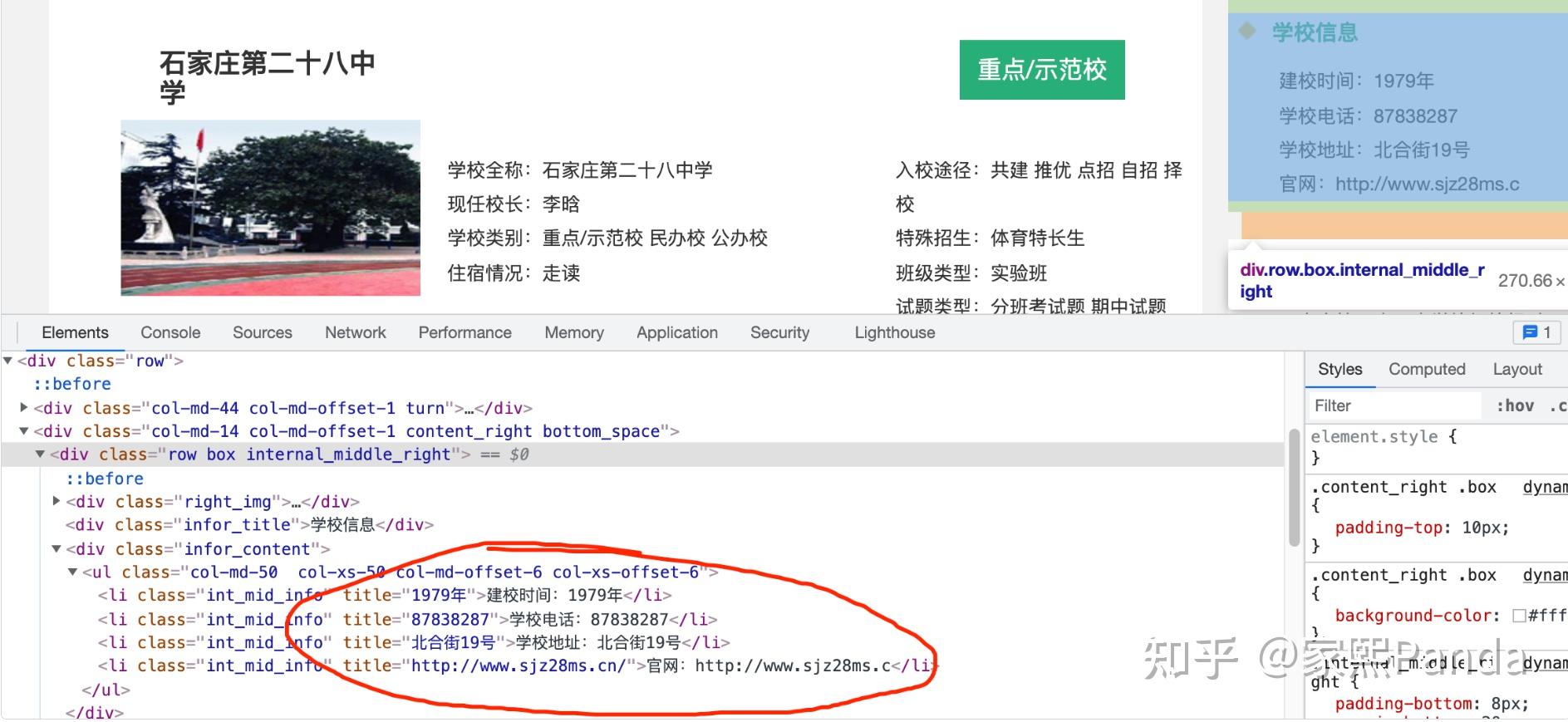
Based on the code analysis above, we might encounter the following issues:
- Encoding issues that may prevent URL retrieval.
- The directly scraped data should be in dictionary type; remove [] to transform it into fields.
- Fields with no information might cause bugs.
First, attempt a simple scrape and time it to see if brute-force scraping is feasible:
for i in range(10000)
url = “https://school.wjszx.com.cn/senior/introduce-{}.html”.format(i)
spider(url)
class spider(url):
## spider
return name, phone, address, url(or return info)
class saving(info):
# Open an existing Excel file
# Open a sheet
# In a for loop, store a field in a row for a fixed column
# Close Excel
Analysis and Improvement
- Since opening, storing in, and closing Excel after scraping each page involves I/O-intensive operations, using multithreading could speed up the process.
- Because of Python's GIL, multithreading can be cumbersome. Moreover, in this case where I/O is not prone to blocking, using coroutines could be faster.
- Remember to disguise the headers when accessing. For large data volumes, write several headers and select randomly. Similarly, use an IP pool for IPs.
- Given the simplicity of the target website, it's assumed there aren't many anti-scraping mechanisms. Hiding the header and scraping at night should minimize issues.
Want to be faster? Use the Scrapy crawling framework
Here's a simple usage introduction:
After installing with pip, in the same directory:
scrapy startproject stu
This will create a Scrapy project directory, with a folder called spiders where you write the crawlers.
yield is roughly equivalent to return.
Several settings in settings.py:
FEED_EXPORT_ENCODING = 'utf-8' ## Change to utf-8
ROBOTSTXT_OBEY = True
CONCURRENT_REQUESTS = 100
CONCURRENT_REQUESTS_PER_DOMAIN = 100
CONCURRENT_REQUESTS_PER_IP = 100
#DOWNLOAD_DELAY = 3 ## Set download delays for more advanced websites, to counteract scraping defenses
COOKIES_ENABLED = False
Start crawling:
scrapy crawl stu
Start crawling and save the results as stu.json:
scrapy crawl stu -o stu.json
3. Google Scholar Crawler and a Video Crawler Demo Version:
https://github.com/JessyTsu1/google_scholar_spider
https://github.com/JessyTsu1/DouYinSpider
4. Data Collection on E-commerce Platforms
Data collection on e-commerce platforms is a typical application scenario. By scraping product information and user reviews, market analysis and consumer behavior studies can be conducted.
- Tool choice: Use Scrapy or GPT-Crawler to scrape product information.
- Data to scrape: Includes product names, prices, descriptions, user reviews, etc.
- Data usage: Analyze market trends, understand competitors' pricing strategies, study consumer purchasing behaviors and preferences, and provide decision support for businesses.
- Possible case: An e-commerce company uses Scrapy to scrape product information from multiple competitor websites, combines it with internal sales data for market analysis, adjusts its pricing strategies, and enhances market competitiveness.
5. Data Scraping from News Websites
Data scraping from news websites is primarily for obtaining the latest news content, training news classification models, or generating models.
- Tool choice: Use Selenium or Jina Reader to obtain the latest news.
- Data to scrape: News titles, body text, publication time, authors, etc.
- Data usage: Train news classification models, automatically generate news summaries, and conduct sentiment analysis.
- Possible case: A media company uses Jina Reader to scrape real-time news from multiple news websites, automatically generates daily news summaries, and publishes them on their website, increasing user stickiness and traffic.
6. Data Analysis on Social Networks
Data analysis on social networks involves scraping and analyzing user relationships and interactions to provide insights into social behavior.
- Tool choice: Use Scrapegraph-AI to scrape data from social networks.
- Data to scrape: User relationships, interaction frequency, post content, likes, and comment data, etc.
- Data usage: Identify key opinion leaders (KOLs) within social networks, study user interaction patterns, and devise social marketing strategies.
- Possible case: A market research firm uses Scrapegraph-AI to scrape user interaction data from social platforms, analyzes the influence and fan interaction of key opinion leaders, and devises precise social marketing strategies for clients, enhancing brand exposure and user engagement.
These practical examples demonstrate how different crawling tools are operated and their effects in various application scenarios, helping to better understand how to select and use crawling tools for effective data collection.
II. Public Datasets
In scientific research, researchers often cannot directly obtain data through web scraping for various reasons, and the field typically has fixed benchmark datasets available for researchers to optimize towards specific targets. In this context, open datasets become a crucial resource for researchers to use and benchmark against.
Public datasets are one of the important sources of data for training large language models, originating from various research institutions, government agencies, and open-source communities. When selecting and evaluating public datasets, it's essential to consider the quality, size, and diversity of the datasets to ensure effective model training.
Sources and Types
Public datasets can be obtained from several types of sources:
Research Institutions: Many universities and research institutes release a vast amount of high-quality research datasets, typically used for academic research and experiments. For instance, institutions like Stanford University and MIT often release datasets in the fields of machine learning and artificial intelligence.
Government Agencies: Government departments offer a wide array of public datasets covering areas such as the economy, society, and the environment, which can be utilized for various analyses and studies. For example, the US government's Data.gov portal provides a rich resource of public data.
Open Source Communities: Open source communities and projects contribute a large number of datasets, which are usually maintained and updated collaboratively by developers and researchers. Examples include GitHub, ModelScope, and HuggingFace.
Evaluation and Selection Criteria
When choosing public datasets, the following criteria are key considerations:
- Dataset Quality: The accuracy and completeness of the data are primary indicators of dataset quality. High-quality datasets should undergo rigorous data cleaning and validation to ensure reliability.
- Dataset Size: The size of the dataset impacts the effectiveness of model training. Larger datasets typically provide more training samples, thus improving the model's generalization ability.
- Dataset Diversity: Diversity is crucial to ensure the model can handle different scenarios and tasks. A diverse dataset should include various types of data samples, covering a wide range of possible inputs.
Common Platforms and Resources
Here are some commonly used platforms and resources for public datasets:
- Kaggle: Kaggle is a data science competition platform that offers a multitude of high-quality public datasets. Users can find datasets commonly used in machine learning and data science projects on Kaggle and participate in community discussions and competitions.
- UCI Machine Learning Repository: The UCI Machine Learning Repository is a well-established resource containing a diverse range of machine learning datasets suitable for training and testing various algorithms and models.
- Google Dataset Search: Google Dataset Search is a tool specifically for searching public datasets, allowing users to easily find and access a wide variety of public datasets covering extensive fields and application scenarios.
Practical Use Cases
The application of public datasets in specific projects can significantly enhance the efficiency and effectiveness of data collection and model training. Here are some practical use cases:
Natural Language Processing Tasks: In natural language processing (NLP) tasks, text datasets from Kaggle can be used to train language models. For example, using the Quora Question Pairs dataset to train a question-answering system that improves answer accuracy by identifying and categorizing similar questions.
Computer Vision Tasks: In the field of computer vision, image datasets from the UCI Machine Learning Repository can be used to train image classification or object detection models. For instance, training an image classification model using the CIFAR-10 dataset to identify and categorize everyday objects.
- Socio-Economic Analysis: Public datasets provided by government agencies can be used for socio-economic analysis and research. For example, using census data from Data.gov for analysis and forecasting of socio-economic conditions to assist governments and businesses in decision-making and policy formulation.
These practical examples demonstrate the widespread application and importance of public datasets in various projects. Proper selection and use of public datasets can effectively enhance the training outcomes and application value of models.
Large Language Model Pre-training Datasets
During the pre-training phase, LLMs learn a broad range of knowledge from vast amounts of unlabeled text data, then store this knowledge in their model parameters. This endows LLMs with a certain level of language understanding and generation capability.
Text from web pages, academic materials, books, and texts from various fields such as legal documents, annual financial reports, medical textbooks, etc., are sources for pre-training corpora.
We typically categorize pre-training datasets into two types: general datasets and domain-specific datasets.
- General Pre-training Datasets typically include text content from the internet, such as news, social media, encyclopedias, etc. They aim to provide general language knowledge and data resources for NLP tasks.
- Domain-specific Pre-training Datasets are intended to provide LLMs with specialized knowledge, such as legal documents, textbooks from various disciplines, etc.
It's noteworthy that incorporating math and code data into pre-training significantly enhances the model's reasoning capabilities.
Book Data
Books are a rich source of unannotated pre-training data. If considering using books as pre-training data, it inevitably requires researching book classifications, allowing us to easily select relevant book data to strengthen the model's capabilities in specific domains.
Refer to the article by Teacher Ruan Yifeng: https://www.ruanyifeng.com/blog/2007/01/classification.html
Books can be classified as follows:
1. Chinese Library Classification (Fourth Edition) (CLC)
A Marxism, Leninism, Mao Zedong Thought, Deng Xiaoping Theory B Philosophy, Religion C Social Sciences General D Politics, Law F Economics G Culture, Science, Education, Sports H Language, Writing I Literature J Art K History, Geography N General Natural Sciences O Mathematical Sciences and Chemistry Q Biological Sciences R Medicine, Health S Agricultural Sciences T Industrial Technology U Transportation V Aviation, Aerospace X Environmental Science, Safety Science Z Comprehensive Books
2. Library of Congress Classification (LCC)
A - GENERAL WORKS B - PHILOSOPHY. PSYCHOLOGY. RELIGION C - AUXILIARY SCIENCES OF HISTORY D - HISTORY (GENERAL) AND HISTORY OF EUROPE E - HISTORY: AMERICA F - HISTORY: AMERICA G - GEOGRAPHY. ANTHROPOLOGY. RECREATION H - SOCIAL SCIENCES J - POLITICAL SCIENCE K - LAW L - EDUCATION M - MUSIC AND BOOKS ON MUSIC N - FINE ARTS P - LANGUAGE AND LITERATURE Q - SCIENCE R - MEDICINE S - AGRICULTURE T - TECHNOLOGY U - MILITARY SCIENCE V - NAVAL SCIENCE Z - BIBLIOGRAPHY. LIBRARY SCIENCE. INFORMATION RESOURCES (GENERAL)
3. Dewey Decimal Classification (DDC)
000 Generalities 100 Philosophy & psychology 200 Religion 300 Social sciences 400 Language 500 Natural sciences & mathematics 600 Technology (Applied sciences) 700 The arts 800 Literature & rhetoric 900 Geography & history
Academic and Internet Resources
- arXiv10: A collection of preprints in fields such as physics, mathematics, computer science, biology, and quantitative finance. This not only provides high-quality academic knowledge but also enables the model to master the LATEX format of papers.
- S2ORC (Lo et al., 2020) covers academic papers in English across all disciplines. It features extensive metadata, abstracts, reference lists, and structured full texts.
- WikiText: This dataset, based on Wikipedia, is designed specifically for language modeling tasks. The WikiText dataset contains high-quality article texts used for testing language modeling algorithms.
- Common Crawl: A vast web dataset that captures over two billion web pages each month. It is used to train some of the largest language models, such as OpenAI's GPT series, and supports various other NLP tasks.
- BookCorpus: Contains texts collected from unpublished books, widely used in natural language processing research. It helps models understand longer textual dependencies.
- Pushshift.io Reddit Dataset: Provided by Pushshift, this dataset is used for various NLP research, including pre-training of language models. It contains a vast amount of posts and comments from Reddit.
- PubMed Central: Plays a role in the open access of nearly five million biomedical publications.
- The Pile: Developed by EleutherAI, a large dataset for training language models that includes various data sources like GitHub, PubMed, ArXiv, and more. This dataset aims to provide diverse and extensive texts for training language models.
- MNBVC: A large-scale Chinese corpus from the Liyushe community. Comparable to the 40T data used for training ChatGPT, it currently has 33,065GB (as of May 30, 2024).
Large Language Model Fine-Tuning Datasets
Instruction fine-tuning datasets are used to further fine-tune pre-trained large language models (LLMs), enabling the model to better understand and follow human instructions. This process helps bridge the gap between the LLMs' next token prediction goal and the objective of following human instructions, thereby enhancing the capabilities and controllability of LLMs.
SFT datasets can be categorized into two types according to the type of instruction: QA Consultation datasets and Agent Subtask datasets.
QA Consultation Datasets:
These datasets do not have specific instructions but require the model to respond in a consultative manner, defined as QA Consultation datasets, such as:
{
"instruction": "",
"input": "I got hit by a car when I went out today, what should I do?",
"output": """I'm very sorry to hear that, and I hope you weren't seriously injured. Here are some steps you might need to consider:
Seek medical help: Even if you feel that the injuries are not severe, sometimes internal injuries may not be immediately apparent. It's best to go to a hospital or clinic for a comprehensive examination.
Call the police: If you haven't already, you should contact the local police immediately so they can come to the scene and make a record. This is very important for any possible claims or legal procedures later.
Document evidence: If possible, take photos to document the accident scene, vehicles, injuries, etc. If there are witnesses, try to get their contact information.
Contact your insurance company: Notify your insurance company about the accident as soon as possible and follow their guidance for the next steps.
Legal consultation: Consider consulting a lawyer to understand your rights and possible compensation.
I hope you recover quickly, and if you need further help or information, let me know anytime!"""
}
These datasets do not require the model to complete specific tasks, but only to learn the logic and style of the output. It's worth mentioning that training the model on a large amount of domain-specific advisory datasets, such as medical consultation, will make the model's responses feature characteristics of the medical model.
Agent Sub-task Datasets
Datasets that involve predefined task types through specific instructions, allowing the model to learn the expressions of respective tasks, are defined as agent sub-task datasets. Examples include:
{
"instruction": "You are an experienced multilingual translator, please translate the following text into ancient Chinese poetry, ensuring faithfulness, expressiveness, and elegance",
"input": "Of course I still love you",
"output":"纵使万里云舒,吾心犹存"
},
//Tips: from Elon Musk, SpaceX
{
"instruction": "Please ask further questions regarding the following legal issue to obtain more relevant information:",
"input": "My father married my stepmother and they had a son. When my father fell ill, he left all his property to his son. My stepmother says that since we both cared for the elderly together, how can she protect her rights?",
"output": "1. Do you have any written or verbal agreements with your father and stepmother regarding the distribution of property and the care of the elderly?\n2. Do you have evidence that you contributed to the care of the elderly, such as paying for medical expenses or providing daily support?\n3. Do you have any other evidence that suggests an unfair distribution of property by your father, such as a will or property transfer records?\n4. Have you communicated or negotiated with your stepmother to resolve this issue?\n5. Have you consulted a lawyer or other legal professional to understand your rights and possible ways to protect them?"
},
{
"instruction": "Identify the legal key terms from the following information:",
"input": "Liability determination for losses caused by unauthorized transactions on a stolen bank card",
"output": "Bank card disputes; counterfeit card transactions; liability allocation; civil litigation; contract;"
},
InstructGPT-sft (Ouyang et al., 2022) categorized part of the dataset into ten categories, including Generation, Open-ended QA, Brainstorming, Chat, Rewrite, Summarization, Classification, Other, Closed-ended QA, and Extraction.
BELLE train 3.5M CN (BELLE Group, 2023) built on this foundation by adding categories such as Role-playing, Math, Translation, Coding, and Harmless, while removing the Chat and Other categories.
Firefly (Yang, 2023) further refined the instruction categories, covering 23 categories. For example, subcategories like Story Generation and Lyrics Generation fall under the original "Generation" category. Considering the current classification status and focusing solely on single-turn dialogue instructions, instructions are broadly divided into 15 categories: Reasoning, Math, Brainstorming, Closed-ended QA, Open-ended QA, Coding, Extraction, Generation, Rewrite, Summarization, Translation, Role-playing, Social Norms, and Others.
Observing the above task categories, we can draw an interesting conclusion: the key to training domain-specific large models is to refine the agent sub-task dataset as much as possible, then choose a general-purpose model with decent capabilities along with domain-specific fine-tuning (SFT) datasets to create a domain-specific large model that appears capable of solving all problems within that domain.
DataTager is a product designed to address the creation of SFT datasets.
III. Partner Data
In the data collection process, collaborating with partners is a highly effective way to obtain high-quality, customized data. Such collaborations can provide highly relevant samples for specific projects, ensuring data quality and reliability.
Benefits of Collaboration
Collaborating with partners for data collection offers several key benefits:
- Customized Data: Partners can provide data sets tailored to specific needs. This data is often more aligned with the actual requirements of projects, improving the training and application effectiveness of models.
- Data Quality Assurance: Partners typically possess professional data collection and processing capabilities, providing high-quality data that has been rigorously verified and cleaned. This reduces data noise and errors, enhancing model accuracy and reliability.
Criteria for Choosing Partners
When selecting partners, consider the following criteria to ensure smooth cooperation and achieve the expected outcomes:
- Reputation: Choose partners with a good reputation, who are more likely to ensure data quality and reliable cooperation.
- Data Relevance: The data provided by partners should be highly relevant to the project requirements.
- Technical Capability: The technical ability of partners in data collection, processing, and management is crucial.
Case Analysis
Here are some successful examples of partner data collection, along with challenges encountered and solutions:
- Specific instances of successful collaborations:
- In the healthcare sector, research institutions collaborate with large hospitals to access patient data for training disease prediction models. Through collaboration, these institutions obtain real medical data, significantly improving model prediction accuracy.
- In e-commerce, platforms collaborate with suppliers to share product sales data and user behavior data. Through this collaboration, e-commerce platforms better understand market demands and user preferences, optimizing product recommendations and marketing strategies.
- Challenges faced and solutions:
- Data Privacy and Security: Data privacy and security are paramount during collaboration. To address this issue, data anonymization and encryption techniques are used to ensure sensitive information is not disclosed. Additionally, a strict confidentiality agreement is signed by both parties, specifying responsibilities and obligations regarding data use and protection.
- Data Format and Compatibility: Data formats may vary among different partners, making data integration challenging. To overcome this, standardized data formats and interfaces are used to ensure compatibility and consistency during data collection and processing.
- Communication and Coordination: Maintaining good communication and coordination during the collaboration is crucial to ensure consistency in project goals and data requirements. Holding regular meetings and exchanges to address issues and challenges timely is essential for successful collaboration.
"Confidence"
The term "confidence" is quoted because it is a name I coined myself based on my experiences since starting my business. In fields such as law, healthcare, education, and finance, even if we aim to create consumer-oriented products that are useful to the general public, users may still have concerns after consultations regarding the endorsement of responses by well-known organizations and institutions. Endorsements from respected institutions like Union Hospital, Red Circle, Luo Xiang, or Magic Square can significantly boost user trust. I refer to this as "confidence."
- The necessity to enhance confidence: To increase user trust, it's essential to collaborate with these renowned institutions to gain their data and approval. Even for consumer products, due to the nature of the industry, we need to strive for "confidence." Therefore, we inevitably deal with large businesses (Big B) and government agencies (Big G).
By closely collaborating with partners, high-quality, customized data can be acquired, significantly enhancing the training outcomes and practical applications of models. Furthermore, partnerships with well-known institutions can increase user trust in products ("confidence"), laying a solid foundation for the success of consumer products in the market. When selecting partners and addressing challenges in the collaboration process, it's important to consider factors such as reputation, data relevance, and technical capability to ensure smooth cooperation.
IV. Crowdsourcing Platforms
Crowdsourcing platforms are an effective method of collecting and processing data through the power of the masses. In this model, tasks are assigned to a large number of online workers who complete the tasks and provide feedback. Crowdsourcing data collection has significant value in the training of large language models.
Concept and Working Principle
- Basic mode of crowdsourcing data collection: Crowdsourcing platforms break down large-scale data collection tasks into smaller tasks, which are then assigned to numerous online workers. After completing the tasks, the workers submit the data, and the platform aggregates and verifies it. This mode not only enables rapid collection of extensive data but also covers diverse data sources.
Advantages and Disadvantages
- Advantages:
- Data Diversity: Crowdsourcing platforms can collect data from workers globally, ensuring diversity and broad coverage.
- Rapid Collection: Through crowdsourcing, large amounts of data can be collected quickly, especially suitable for projects that require rapid acquisition of extensive data.
- Disadvantages:
- Data Quality Control: Due to the varied backgrounds and capabilities of workers on crowdsourcing platforms, data quality can be inconsistent. Effective quality control mechanisms are necessary to ensure data accuracy and consistency.
- Management and Coordination: Managing and coordinating tasks among a large number of workers requires extra effort. Clear task standards and verification processes need to be established.
| Crowdsourcing Platforms | |
|---|---|
| Advantages | Data Diversity: Can collect data from workers worldwide, ensuring diversity and broad coverage. Rapid Collection: Can complete large data collection tasks quickly. |
| Disadvantages | Data Quality Control: Data quality may vary due to the diverse backgrounds and capabilities of workers. Management and Coordination: Managing and coordinating a large number of workers' tasks requires extra effort. |
Popular Platforms
Here are some commonly used crowdsourcing platforms, which have extensive experience and broad applications in data collection and processing:
- Amazon Mechanical Turk: MTurk is a widely used crowdsourcing platform that offers various types of data collection and processing tasks. Users can publish tasks on MTurk to obtain data from global workers.

Figure Eight (formerly CrowdFlower): Figure Eight is a professional crowdsourcing platform that offers services such as data labeling, cleaning, and verification, widely used in machine learning and artificial intelligence projects.
Appen: Appen is a well-known crowdsourcing platform that specializes in providing high-quality data collection and labeling services, particularly excelling in language data and image data processing.
Practical Use Cases
Crowdsourcing platforms are extensively used in the training of large language models, and here are some actual use cases:
- Text Annotation: In the training process of large language models, a substantial amount of annotated text data is needed. Using Amazon Mechanical Turk, researchers can publish tasks like text classification and sentiment analysis to quickly obtain a large volume of annotated text data. This data is used to train and evaluate large language models.
- Dialogue Data Collection: Large language models require rich dialogue data to train dialogue generation capabilities. Through Figure Eight, businesses can publish tasks for dialogue data collection, obtaining diverse dialogue data for training dialogue models.
- Language Data Collection: To enhance the multilingual processing capabilities of large language models, it's necessary to collect text data in various languages. Appen's multilingual data collection service can help gather text samples from different regions and languages, supporting the training and optimization of multilingual models.
Crowdsourcing platforms provide robust support for data collection and annotation in the training of large language models. By effectively utilizing these platforms, diverse, high-quality data can be efficiently acquired, providing a solid foundation for the training of large language models. Additionally, the rapid response and large-scale data processing capabilities of crowdsourcing platforms meet the high data demands of large language model training.
V. Data Storage Formats
During the data collection and processing stages, selecting the appropriate data storage format is crucial to ensure data availability and processing efficiency. Common data storage formats include JSON, JSONL, CSV, and XML. Other formats like Parquet, Avro, and HDF5 are also used, each with its own advantages and disadvantages.
Common Formats
- JSON: JavaScript Object Notation, a lightweight data interchange format, easy to read and write.
- JSONL: JSON Lines, each line a JSON object, suitable for processing large datasets line by line.
- CSV: Comma-Separated Values, a plain text format used for storing tabular data.
- XML: eXtensible Markup Language, a widely used extensible markup language for data exchange and storage.
- Parquet: A columnar storage format suited for big data processing, particularly within the Apache Hadoop ecosystem.
- Avro: A row-based storage format that supports data serialization and schema evolution, suitable for data streaming and big data processing.
- HDF5: Hierarchical Data Format, a format used for storing and managing large-scale data, widely used in scientific computing and machine learning.
Comparison of Advantages and Disadvantages
| Format | Readability | Parsing Efficiency | Storage Space | Other Features |
|---|---|---|---|---|
| JSON | Easy to read and write, clear structure | Moderate parsing speed | Larger than CSV, but smaller than XML | Easy to use, widely supported |
| JSONL | Easy to process line by line | Fast parsing speed | Moderate | Suitable for large-scale data processing |
| CSV | Simple and easy to read, but lacks structural info | Fast parsing speed | Smallest | Easy to handle, widely used |
| XML | Good readability, but verbose | Slow parsing speed | Largest, includes a lot of tag information | Strong self-descriptiveness, supports complex structures |
| Parquet | Poor readability | Fast parsing speed, suitable for columnar reading | High compression efficiency, occupies less space | Columnar storage, suitable for big data analysis |
| Avro | Average readability | Fast parsing speed | High compression efficiency, occupies less space | Supports data schema evolution, suitable for stream processing |
| HDF5 | Poor readability | Fast parsing speed | Efficient storage of large-scale data | Supports complex data structures and multidimensional arrays |
Practical Usage Recommendations
When choosing a data storage format, it is necessary to weigh based on the specific use case and requirements. Here are some practical usage recommendations:
- JSON: Suitable for structured data, especially scenarios requiring nested and complex data structures. Commonly used for API data exchange and configuration files.
- Example: Used for storing user settings and application configurations, offering clear data structure, easy to parse and modify.
- JSONL: Ideal for large-scale data processing, especially for datasets that require line-by-line reading and handling. Commonly used for log files and data stream processing.
- Example: Used for storing large-scale log data, with each JSON object per line, facilitating quick parsing and processing.
- CSV: Appropriate for simple tabular data, especially scenarios that require efficient storage and rapid access. Commonly used for data analysis and report generation.
- Example: Used for storing and processing large datasets like sales records and user data, offering fast parsing and minimal space usage.
- XML: Suitable for data requiring high readability and self-description, commonly used for document formats and data exchange standards.
- Example: Used for document storage and configuration files, offering clear data structure but slower parsing speed and larger file size.
- Parquet: Appropriate for big data processing, especially scenarios requiring columnar storage and efficient compression. Commonly used in data warehouses and big data analytics.
- Example: Used in Hadoop and Spark environments for efficient data storage and analysis.
- Avro: Suitable for scenarios requiring data serialization and schema evolution, commonly used for data streaming and big data processing.
- Example: Used in Kafka and Hadoop for data exchange and storage, supporting efficient data stream processing.
- HDF5: Suitable for scientific computing and machine learning involving large-scale data storage and management, supporting complex data structures and multidimensional arrays.
- Example: Used for storing and processing scientific data, such as astronomical observations and machine learning training data.
By wisely choosing data storage formats, data processing efficiency can be significantly enhanced, ensuring data readability and maintainability. Selecting the most appropriate data format based on specific application scenarios and requirements helps improve overall data management and utilization.
VI. Considerations for Data Collection
During data collection, it's crucial to pay close attention to data privacy and compliance, while also ensuring data quality and consistency. Here are some key considerations.
Data Privacy and Compliance
During data collection and processing, it is mandatory to comply with relevant data privacy regulations to ensure the legality and protection of user privacy.
- GDPR (General Data Protection Regulation): The European Union's regulation requires explicit user consent and ensures the security and privacy of data pertaining to EU residents.
- CCPA (California Consumer Privacy Act): Protects the personal data privacy of California residents, giving consumers more control and rights to information.
- Other relevant regulations: Privacy protection laws may vary by country and region and must be adhered to accordingly.
Data Cleaning and Preprocessing
Data cleaning and preprocessing are crucial steps to ensure data quality, removing noise and errors, and enhancing data accuracy and consistency.
- Data Cleaning: Includes removing duplicate data, correcting erroneous data, and filling missing values. Various data cleaning tools and techniques can be used, such as Pandas, OpenRefine, etc.
- Example: Using the Pandas library to clean data in a CSV file, removing duplicate rows, correcting format errors, and filling missing values to ensure data integrity and accuracy.
- Data Preprocessing: Includes standardization, normalization, feature extraction, etc. Preprocessed data is better suited for model training and analysis.
- Example: Standardizing data before training machine learning models, scaling all features to the same range to prevent large differences in feature values from impacting model performance.
Deduplication and Standardization
Deduplication and standardization are important steps in data collection to avoid redundancy and inconsistency.
- Deduplication: By checking and removing duplicate data, data redundancy is reduced, enhancing data processing efficiency and model training outcomes.
- Example: In user data collection, by checking user IDs and other unique identifiers, duplicate user records are removed, ensuring each user's data is unique.
- Standardization: Converting data into a uniform format to ensure consistency and comparability. Standardization includes format conversion, unit conversion, etc.
- Example: During the integration of multi-source data, standardizing all date formats to the ISO 8601 standard ensures consistency across different data sources.
By adhering to data privacy regulations, performing effective data cleaning and preprocessing, and conducting deduplication and standardization, data quality and consistency can be significantly enhanced, laying a solid foundation for subsequent data analysis and model training.
VII. Data Storage and Management
Cloud Storage vs. Local Storage
- Cloud Storage: Offered by third-party service providers (e.g., AWS, Google Cloud, Microsoft Azure). Cloud storage features high scalability and flexibility, suitable for large-scale data storage and processing.
- Advantages: Scalable, high availability, no need for hardware maintenance.
- Disadvantages: Costs increase with storage volume and usage frequency, security depends on third-party service providers.
- Example: Using Amazon S3 for storing large-scale training data, leveraging its robust data management and distribution capabilities to support training of large language models.
- Local Storage: Data storage through devices maintained by businesses or individuals (e.g., NAS, SAN).
- Advantages: Full control over data and hardware, no concerns about external service interruptions.
- Disadvantages: Limited scalability, requires maintenance and management.
- Example: A research institution uses local storage devices to store sensitive research data, ensuring data security and privacy.
Distributed Databases
- Distributed Databases: Database systems used for storing and managing large-scale data, distributed across multiple nodes to provide high performance and availability.
- Advantages: High scalability, reliability, supports large-scale concurrent access.
- Disadvantages: Complex deployment and management, data consistency and latency need optimization.
- Example: Using Apache Cassandra to store and manage distributed data, supporting large-scale real-time data processing and analysis.
Best Practices
Data Labeling and Metadata Management
- Data Labeling: Classifying and tagging data for easier retrieval and management.
- Example: Managing labels for data used in training large language models, tagging data sources, categories, and use scenarios for easy retrieval and use.
- Metadata Management: Managing data about data, including source, creation time, format, etc., to ensure data integrity and traceability.
- Example: Establishing a metadata management system to record detailed information about each dataset, ensuring data is managed throughout its lifecycle.
Data Version Control
- Data Version Control: Managing versions of data, recording the history of changes to ensure traceability and consistency.
- Example: Using DVC (Data Version Control) tools to manage versions of training data, recording each data update and change, ensuring consistency in the data used during model training.
References:
https://x.com/vikingmute/status/1737296571354743268
https://timconnors.co/posts/ai-scraper
https://zhuanlan.zhihu.com/p/692683234
https://zhuanlan.zhihu.com/p/669816705
https://zhuanlan.zhihu.com/p/693096151
For starting a proxy pool using Redis: https://github.com/Python3WebSpider/ProxyPool
https://blog.csdn.net/gyt15663668337/article/details/86345690
A simple introduction to Scrapy: https://vip.fxxkpython.com/?p=5038