

upload model
Browse files- LICENSE +53 -0
- NOTICE +52 -0
- assets/cli_demo.gif +0 -0
- assets/logo.jpg +0 -0
- assets/wechat.png +0 -0
- cache_autogptq_cuda_256.cpp +198 -0
- cache_autogptq_cuda_kernel_256.cu +1708 -0
- config.json +49 -0
- configuration_qwen.py +71 -0
- cpp_kernels.py +55 -0
- generation_config.json +11 -0
- model-00001-of-00005.safetensors +3 -0
- model-00002-of-00005.safetensors +3 -0
- model-00003-of-00005.safetensors +3 -0
- model-00004-of-00005.safetensors +3 -0
- model-00005-of-00005.safetensors +3 -0
- model.safetensors.index.json +874 -0
- modeling_qwen.py +1416 -0
- quantize_config.json +11 -0
- qwen.tiktoken +0 -0
- qwen_generation_utils.py +416 -0
- tokenization_qwen.py +276 -0
- tokenizer_config.json +10 -0
LICENSE
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Tongyi Qianwen LICENSE AGREEMENT
|
| 2 |
+
|
| 3 |
+
Tongyi Qianwen Release Date: August 3, 2023
|
| 4 |
+
|
| 5 |
+
By clicking to agree or by using or distributing any portion or element of the Tongyi Qianwen Materials, you will be deemed to have recognized and accepted the content of this Agreement, which is effective immediately.
|
| 6 |
+
|
| 7 |
+
1. Definitions
|
| 8 |
+
a. This Tongyi Qianwen LICENSE AGREEMENT (this "Agreement") shall mean the terms and conditions for use, reproduction, distribution and modification of the Materials as defined by this Agreement.
|
| 9 |
+
b. "We"(or "Us") shall mean Alibaba Cloud.
|
| 10 |
+
c. "You" (or "Your") shall mean a natural person or legal entity exercising the rights granted by this Agreement and/or using the Materials for any purpose and in any field of use.
|
| 11 |
+
d. "Third Parties" shall mean individuals or legal entities that are not under common control with Us or You.
|
| 12 |
+
e. "Tongyi Qianwen" shall mean the large language models (including Qwen model and Qwen-Chat model), and software and algorithms, consisting of trained model weights, parameters (including optimizer states), machine-learning model code, inference-enabling code, training-enabling code, fine-tuning enabling code and other elements of the foregoing distributed by Us.
|
| 13 |
+
f. "Materials" shall mean, collectively, Alibaba Cloud's proprietary Tongyi Qianwen and Documentation (and any portion thereof) made available under this Agreement.
|
| 14 |
+
g. "Source" form shall mean the preferred form for making modifications, including but not limited to model source code, documentation source, and configuration files.
|
| 15 |
+
h. "Object" form shall mean any form resulting from mechanical transformation or translation of a Source form, including but not limited to compiled object code, generated documentation,
|
| 16 |
+
and conversions to other media types.
|
| 17 |
+
|
| 18 |
+
2. Grant of Rights
|
| 19 |
+
You are granted a non-exclusive, worldwide, non-transferable and royalty-free limited license under Alibaba Cloud's intellectual property or other rights owned by Us embodied in the Materials to use, reproduce, distribute, copy, create derivative works of, and make modifications to the Materials.
|
| 20 |
+
|
| 21 |
+
3. Redistribution
|
| 22 |
+
You may reproduce and distribute copies of the Materials or derivative works thereof in any medium, with or without modifications, and in Source or Object form, provided that You meet the following conditions:
|
| 23 |
+
a. You shall give any other recipients of the Materials or derivative works a copy of this Agreement;
|
| 24 |
+
b. You shall cause any modified files to carry prominent notices stating that You changed the files;
|
| 25 |
+
c. You shall retain in all copies of the Materials that You distribute the following attribution notices within a "Notice" text file distributed as a part of such copies: "Tongyi Qianwen is licensed under the Tongyi Qianwen LICENSE AGREEMENT, Copyright (c) Alibaba Cloud. All Rights Reserved."; and
|
| 26 |
+
d. You may add Your own copyright statement to Your modifications and may provide additional or different license terms and conditions for use, reproduction, or distribution of Your modifications, or for any such derivative works as a whole, provided Your use, reproduction, and distribution of the work otherwise complies with the terms and conditions of this Agreement.
|
| 27 |
+
|
| 28 |
+
4. Restrictions
|
| 29 |
+
If you are commercially using the Materials, and your product or service has more than 100 million monthly active users, You shall request a license from Us. You cannot exercise your rights under this Agreement without our express authorization.
|
| 30 |
+
|
| 31 |
+
5. Rules of use
|
| 32 |
+
a. The Materials may be subject to export controls or restrictions in China, the United States or other countries or regions. You shall comply with applicable laws and regulations in your use of the Materials.
|
| 33 |
+
b. You can not use the Materials or any output therefrom to improve any other large language model (excluding Tongyi Qianwen or derivative works thereof).
|
| 34 |
+
|
| 35 |
+
6. Intellectual Property
|
| 36 |
+
a. We retain ownership of all intellectual property rights in and to the Materials and derivatives made by or for Us. Conditioned upon compliance with the terms and conditions of this Agreement, with respect to any derivative works and modifications of the Materials that are made by you, you are and will be the owner of such derivative works and modifications.
|
| 37 |
+
b. No trademark license is granted to use the trade names, trademarks, service marks, or product names of Us, except as required to fulfill notice requirements under this Agreement or as required for reasonable and customary use in describing and redistributing the Materials.
|
| 38 |
+
c. If you commence a lawsuit or other proceedings (including a cross-claim or counterclaim in a lawsuit) against Us or any entity alleging that the Materials or any output therefrom, or any part of the foregoing, infringe any intellectual property or other right owned or licensable by you, then all licences granted to you under this Agreement shall terminate as of the date such lawsuit or other proceeding is commenced or brought.
|
| 39 |
+
|
| 40 |
+
7. Disclaimer of Warranty and Limitation of Liability
|
| 41 |
+
|
| 42 |
+
a. We are not obligated to support, update, provide training for, or develop any further version of the Tongyi Qianwen Materials or to grant any license thereto.
|
| 43 |
+
b. THE MATERIALS ARE PROVIDED "AS IS" WITHOUT ANY EXPRESS OR IMPLIED WARRANTY OF ANY KIND INCLUDING WARRANTIES OF MERCHANTABILITY, NONINFRINGEMENT, OR FITNESS FOR A PARTICULAR PURPOSE. WE MAKE NO WARRANTY AND ASSUME NO RESPONSIBILITY FOR THE SAFETY OR STABILITY OF THE MATERIALS AND ANY OUTPUT THEREFROM.
|
| 44 |
+
c. IN NO EVENT SHALL WE BE LIABLE TO YOU FOR ANY DAMAGES, INCLUDING, BUT NOT LIMITED TO ANY DIRECT, OR INDIRECT, SPECIAL OR CONSEQUENTIAL DAMAGES ARISING FROM YOUR USE OR INABILITY TO USE THE MATERIALS OR ANY OUTPUT OF IT, NO MATTER HOW IT’S CAUSED.
|
| 45 |
+
d. You will defend, indemnify and hold harmless Us from and against any claim by any third party arising out of or related to your use or distribution of the Materials.
|
| 46 |
+
|
| 47 |
+
8. Survival and Termination.
|
| 48 |
+
a. The term of this Agreement shall commence upon your acceptance of this Agreement or access to the Materials and will continue in full force and effect until terminated in accordance with the terms and conditions herein.
|
| 49 |
+
b. We may terminate this Agreement if you breach any of the terms or conditions of this Agreement. Upon termination of this Agreement, you must delete and cease use of the Materials. Sections 7 and 9 shall survive the termination of this Agreement.
|
| 50 |
+
|
| 51 |
+
9. Governing Law and Jurisdiction.
|
| 52 |
+
a. This Agreement and any dispute arising out of or relating to it will be governed by the laws of China, without regard to conflict of law principles, and the UN Convention on Contracts for the International Sale of Goods does not apply to this Agreement.
|
| 53 |
+
b. The People's Courts in Hangzhou City shall have exclusive jurisdiction over any dispute arising out of this Agreement.
|
NOTICE
ADDED
|
@@ -0,0 +1,52 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
------------- LICENSE FOR NVIDIA Megatron-LM code --------------
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
|
| 4 |
+
|
| 5 |
+
Redistribution and use in source and binary forms, with or without
|
| 6 |
+
modification, are permitted provided that the following conditions
|
| 7 |
+
are met:
|
| 8 |
+
* Redistributions of source code must retain the above copyright
|
| 9 |
+
notice, this list of conditions and the following disclaimer.
|
| 10 |
+
* Redistributions in binary form must reproduce the above copyright
|
| 11 |
+
notice, this list of conditions and the following disclaimer in the
|
| 12 |
+
documentation and/or other materials provided with the distribution.
|
| 13 |
+
* Neither the name of NVIDIA CORPORATION nor the names of its
|
| 14 |
+
contributors may be used to endorse or promote products derived
|
| 15 |
+
from this software without specific prior written permission.
|
| 16 |
+
|
| 17 |
+
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS ``AS IS'' AND ANY
|
| 18 |
+
EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
|
| 19 |
+
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
|
| 20 |
+
PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR
|
| 21 |
+
CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL,
|
| 22 |
+
EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO,
|
| 23 |
+
PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR
|
| 24 |
+
PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY
|
| 25 |
+
OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
|
| 26 |
+
(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
|
| 27 |
+
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
------------- LICENSE FOR OpenAI tiktoken code --------------
|
| 31 |
+
|
| 32 |
+
MIT License
|
| 33 |
+
|
| 34 |
+
Copyright (c) 2022 OpenAI, Shantanu Jain
|
| 35 |
+
|
| 36 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 37 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 38 |
+
in the Software without restriction, including without limitation the rights
|
| 39 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 40 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 41 |
+
furnished to do so, subject to the following conditions:
|
| 42 |
+
|
| 43 |
+
The above copyright notice and this permission notice shall be included in all
|
| 44 |
+
copies or substantial portions of the Software.
|
| 45 |
+
|
| 46 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 47 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 48 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 49 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 50 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 51 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 52 |
+
SOFTWARE.
|
assets/cli_demo.gif
ADDED
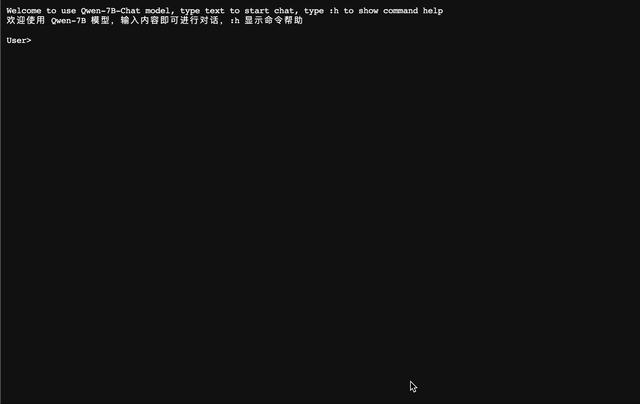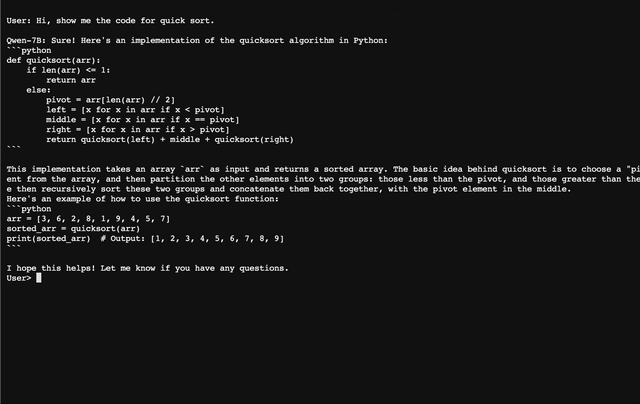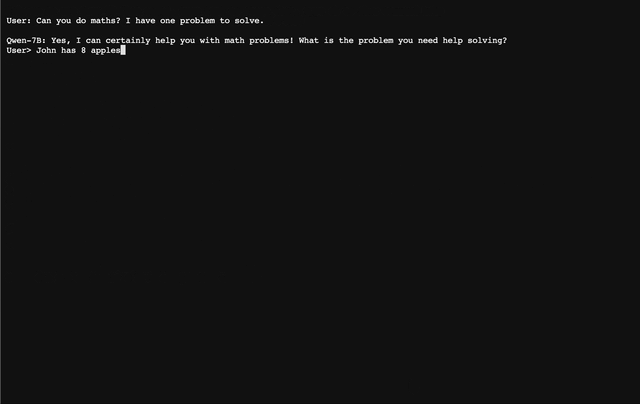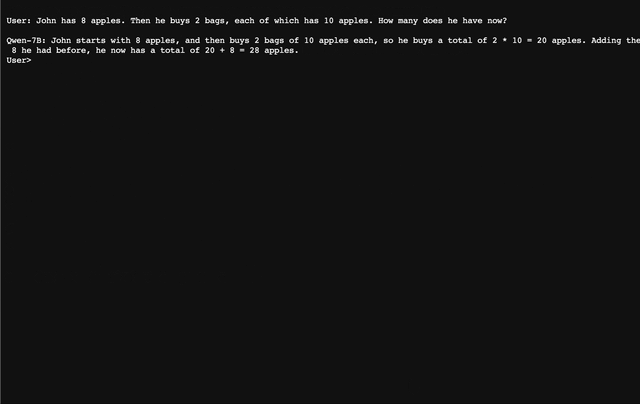
|
assets/logo.jpg
ADDED
|
|
assets/wechat.png
ADDED

|
cache_autogptq_cuda_256.cpp
ADDED
|
@@ -0,0 +1,198 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#include <torch/all.h>
|
| 2 |
+
#include <torch/python.h>
|
| 3 |
+
#include <c10/cuda/CUDAGuard.h>
|
| 4 |
+
|
| 5 |
+
// adapted from https://github.com/PanQiWei/AutoGPTQ/blob/main/autogptq_extension/cuda_256/autogptq_cuda_256.cpp
|
| 6 |
+
void vecquant8matmul_cuda(
|
| 7 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 8 |
+
torch::Tensor scales, torch::Tensor zeros,
|
| 9 |
+
torch::Tensor g_idx
|
| 10 |
+
);
|
| 11 |
+
|
| 12 |
+
void vecquant8matmul(
|
| 13 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 14 |
+
torch::Tensor scales, torch::Tensor zeros,
|
| 15 |
+
torch::Tensor g_idx
|
| 16 |
+
) {
|
| 17 |
+
const at::cuda::OptionalCUDAGuard device_guard(device_of(vec));
|
| 18 |
+
vecquant8matmul_cuda(vec, mat, mul, scales, zeros, g_idx);
|
| 19 |
+
}
|
| 20 |
+
|
| 21 |
+
void vecquant8matmul_batched_cuda(
|
| 22 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 23 |
+
torch::Tensor scales, torch::Tensor zeros
|
| 24 |
+
);
|
| 25 |
+
|
| 26 |
+
void vecquant8matmul_batched(
|
| 27 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 28 |
+
torch::Tensor scales, torch::Tensor zeros
|
| 29 |
+
) {
|
| 30 |
+
const at::cuda::OptionalCUDAGuard device_guard(device_of(vec));
|
| 31 |
+
vecquant8matmul_batched_cuda(vec, mat, mul, scales, zeros);
|
| 32 |
+
}
|
| 33 |
+
|
| 34 |
+
void vecquant8matmul_batched_column_compression_cuda(
|
| 35 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 36 |
+
torch::Tensor scales, torch::Tensor zeros
|
| 37 |
+
);
|
| 38 |
+
|
| 39 |
+
void vecquant8matmul_batched_column_compression(
|
| 40 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 41 |
+
torch::Tensor scales, torch::Tensor zeros
|
| 42 |
+
) {
|
| 43 |
+
const at::cuda::OptionalCUDAGuard device_guard(device_of(vec));
|
| 44 |
+
vecquant8matmul_batched_column_compression_cuda(vec, mat, mul, scales, zeros);
|
| 45 |
+
}
|
| 46 |
+
|
| 47 |
+
void vecquant4matmul_batched_cuda(
|
| 48 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 49 |
+
torch::Tensor scales, torch::Tensor zeros
|
| 50 |
+
);
|
| 51 |
+
|
| 52 |
+
void vecquant4matmul_batched(
|
| 53 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 54 |
+
torch::Tensor scales, torch::Tensor zeros
|
| 55 |
+
) {
|
| 56 |
+
const at::cuda::OptionalCUDAGuard device_guard(device_of(vec));
|
| 57 |
+
vecquant4matmul_batched_cuda(vec, mat, mul, scales, zeros);
|
| 58 |
+
}
|
| 59 |
+
|
| 60 |
+
void vecquant4matmul_batched_column_compression_cuda(
|
| 61 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 62 |
+
torch::Tensor scales, torch::Tensor zeros
|
| 63 |
+
);
|
| 64 |
+
|
| 65 |
+
void vecquant4matmul_batched_column_compression(
|
| 66 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 67 |
+
torch::Tensor scales, torch::Tensor zeros
|
| 68 |
+
) {
|
| 69 |
+
const at::cuda::OptionalCUDAGuard device_guard(device_of(vec));
|
| 70 |
+
vecquant4matmul_batched_column_compression_cuda(vec, mat, mul, scales, zeros);
|
| 71 |
+
}
|
| 72 |
+
|
| 73 |
+
void vecquant8matmul_batched_old_cuda(
|
| 74 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 75 |
+
torch::Tensor scales, torch::Tensor zeros
|
| 76 |
+
);
|
| 77 |
+
|
| 78 |
+
void vecquant8matmul_batched_old(
|
| 79 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 80 |
+
torch::Tensor scales, torch::Tensor zeros
|
| 81 |
+
) {
|
| 82 |
+
const at::cuda::OptionalCUDAGuard device_guard(device_of(vec));
|
| 83 |
+
vecquant8matmul_batched_old_cuda(vec, mat, mul, scales, zeros);
|
| 84 |
+
}
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
void vecquant4matmul_batched_old_cuda(
|
| 88 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 89 |
+
torch::Tensor scales, torch::Tensor zeros
|
| 90 |
+
);
|
| 91 |
+
|
| 92 |
+
void vecquant4matmul_batched_old(
|
| 93 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 94 |
+
torch::Tensor scales, torch::Tensor zeros
|
| 95 |
+
) {
|
| 96 |
+
const at::cuda::OptionalCUDAGuard device_guard(device_of(vec));
|
| 97 |
+
vecquant4matmul_batched_old_cuda(vec, mat, mul, scales, zeros);
|
| 98 |
+
}
|
| 99 |
+
|
| 100 |
+
void vecquant8matmul_batched_column_compression_old_cuda(
|
| 101 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 102 |
+
torch::Tensor scales, torch::Tensor zeros
|
| 103 |
+
);
|
| 104 |
+
|
| 105 |
+
void vecquant8matmul_batched_column_compression_old(
|
| 106 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 107 |
+
torch::Tensor scales, torch::Tensor zeros
|
| 108 |
+
) {
|
| 109 |
+
const at::cuda::OptionalCUDAGuard device_guard(device_of(vec));
|
| 110 |
+
vecquant8matmul_batched_column_compression_old_cuda(vec, mat, mul, scales, zeros);
|
| 111 |
+
}
|
| 112 |
+
|
| 113 |
+
void vecquant4matmul_batched_column_compression_old_cuda(
|
| 114 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 115 |
+
torch::Tensor scales, torch::Tensor zeros
|
| 116 |
+
);
|
| 117 |
+
|
| 118 |
+
void vecquant4matmul_batched_column_compression_old(
|
| 119 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 120 |
+
torch::Tensor scales, torch::Tensor zeros
|
| 121 |
+
) {
|
| 122 |
+
const at::cuda::OptionalCUDAGuard device_guard(device_of(vec));
|
| 123 |
+
vecquant4matmul_batched_column_compression_old_cuda(vec, mat, mul, scales, zeros);
|
| 124 |
+
}
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
void vecquant8matmul_batched_faster_cuda(
|
| 129 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 130 |
+
torch::Tensor scales, torch::Tensor zeros
|
| 131 |
+
);
|
| 132 |
+
|
| 133 |
+
void vecquant8matmul_batched_faster(
|
| 134 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 135 |
+
torch::Tensor scales, torch::Tensor zeros
|
| 136 |
+
) {
|
| 137 |
+
const at::cuda::OptionalCUDAGuard device_guard(device_of(vec));
|
| 138 |
+
vecquant8matmul_batched_faster_cuda(vec, mat, mul, scales, zeros);
|
| 139 |
+
}
|
| 140 |
+
|
| 141 |
+
|
| 142 |
+
void vecquant8matmul_batched_faster_old_cuda(
|
| 143 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 144 |
+
torch::Tensor scales, torch::Tensor zeros
|
| 145 |
+
);
|
| 146 |
+
|
| 147 |
+
void vecquant8matmul_batched_faster_old(
|
| 148 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 149 |
+
torch::Tensor scales, torch::Tensor zeros
|
| 150 |
+
) {
|
| 151 |
+
const at::cuda::OptionalCUDAGuard device_guard(device_of(vec));
|
| 152 |
+
vecquant8matmul_batched_faster_old_cuda(vec, mat, mul, scales, zeros);
|
| 153 |
+
}
|
| 154 |
+
|
| 155 |
+
void vecquant8matmul_batched_column_compression_faster_cuda(
|
| 156 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 157 |
+
torch::Tensor scales, torch::Tensor zeros
|
| 158 |
+
);
|
| 159 |
+
|
| 160 |
+
void vecquant8matmul_batched_column_compression_faster(
|
| 161 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 162 |
+
torch::Tensor scales, torch::Tensor zeros
|
| 163 |
+
) {
|
| 164 |
+
const at::cuda::OptionalCUDAGuard device_guard(device_of(vec));
|
| 165 |
+
vecquant8matmul_batched_column_compression_faster_cuda(vec, mat, mul, scales, zeros);
|
| 166 |
+
}
|
| 167 |
+
|
| 168 |
+
|
| 169 |
+
void vecquant8matmul_batched_column_compression_faster_old_cuda(
|
| 170 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 171 |
+
torch::Tensor scales, torch::Tensor zeros
|
| 172 |
+
);
|
| 173 |
+
|
| 174 |
+
void vecquant8matmul_batched_column_compression_faster_old(
|
| 175 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 176 |
+
torch::Tensor scales, torch::Tensor zeros
|
| 177 |
+
) {
|
| 178 |
+
const at::cuda::OptionalCUDAGuard device_guard(device_of(vec));
|
| 179 |
+
vecquant8matmul_batched_column_compression_faster_old_cuda(vec, mat, mul, scales, zeros);
|
| 180 |
+
}
|
| 181 |
+
|
| 182 |
+
|
| 183 |
+
|
| 184 |
+
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
|
| 185 |
+
m.def("vecquant8matmul", &vecquant8matmul, "Vector 8-bit Quantized Matrix Multiplication (CUDA) (desc_act)");
|
| 186 |
+
m.def("vecquant8matmul_batched", &vecquant8matmul_batched, "Vector 8-bit Batched Quantized Matrix Multiplication (CUDA) (desc_act)");
|
| 187 |
+
m.def("vecquant8matmul_batched_old", &vecquant8matmul_batched_old, "Vector 8-bit old Batched Quantized Matrix Multiplication (CUDA) (desc_act)");
|
| 188 |
+
m.def("vecquant8matmul_batched_faster", &vecquant8matmul_batched_faster, "Vector 8-bit old Batched Quantized Matrix Multiplication (CUDA) (desc_act)");
|
| 189 |
+
m.def("vecquant8matmul_batched_faster_old", &vecquant8matmul_batched_faster_old, "Vector 8-bit old Batched Quantized Matrix Multiplication (CUDA) (desc_act)");
|
| 190 |
+
m.def("vecquant4matmul_batched_old", &vecquant4matmul_batched_old, "Vector 4-bit old Batched Quantized Matrix Multiplication (CUDA) (desc_act)");
|
| 191 |
+
m.def("vecquant8matmul_batched_column_compression", &vecquant8matmul_batched_column_compression, "Vector 8-bit Batched Quantized Matrix Multiplication (CUDA) with weight's column compressed (desc_act)");
|
| 192 |
+
m.def("vecquant8matmul_batched_column_compression_old", &vecquant8matmul_batched_column_compression_old, "Vector old 8-bit Batched Quantized Matrix Multiplication (CUDA) with weight's column compressed (desc_act)");
|
| 193 |
+
m.def("vecquant8matmul_batched_column_compression_faster", &vecquant8matmul_batched_column_compression_faster, "Vector old 8-bit Batched Quantized Matrix Multiplication (CUDA) with weight's column compressed (desc_act)");
|
| 194 |
+
m.def("vecquant8matmul_batched_column_compression_faster_old", &vecquant8matmul_batched_column_compression_faster_old, "Vector old 8-bit Batched Quantized Matrix Multiplication (CUDA) with weight's column compressed (desc_act)");
|
| 195 |
+
m.def("vecquant4matmul_batched_column_compression_old", &vecquant4matmul_batched_column_compression_old, "Vector old 4-bit Batched Quantized Matrix Multiplication (CUDA) with weight's column compressed (desc_act)");
|
| 196 |
+
m.def("vecquant4matmul_batched", &vecquant4matmul_batched, "Vector 4-bit Batched Quantized Matrix Multiplication (CUDA) (desc_act)");
|
| 197 |
+
m.def("vecquant4matmul_batched_column_compression", &vecquant4matmul_batched_column_compression, "Vector 4-bit Batched Quantized Matrix Multiplication (CUDA) with weight's column compressed (desc_act)");
|
| 198 |
+
}
|
cache_autogptq_cuda_kernel_256.cu
ADDED
|
@@ -0,0 +1,1708 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#define _CRT_SECURE_NO_WARNINGS
|
| 2 |
+
#include <torch/all.h>
|
| 3 |
+
#include <torch/python.h>
|
| 4 |
+
#include <cuda.h>
|
| 5 |
+
#include <cuda_runtime.h>
|
| 6 |
+
#include <cuda_fp16.h>
|
| 7 |
+
#include <stdint.h>
|
| 8 |
+
|
| 9 |
+
#if (defined(__CUDA_ARCH__) && __CUDA_ARCH__ < 700) || defined(USE_ROCM)
|
| 10 |
+
// adapted from https://github.com/PanQiWei/AutoGPTQ/blob/main/autogptq_extension/cuda_256/autogptq_cuda_kernel_256.cu
|
| 11 |
+
__device__ __forceinline__ void atomicAdd(c10::Half* address, c10::Half val) {
|
| 12 |
+
unsigned int *address_as_ui = reinterpret_cast<unsigned int *>(reinterpret_cast<char *>(address) - (reinterpret_cast<size_t>(address) & 2));
|
| 13 |
+
unsigned int old = *address_as_ui;
|
| 14 |
+
unsigned int assumed;
|
| 15 |
+
|
| 16 |
+
do {
|
| 17 |
+
assumed = old;
|
| 18 |
+
unsigned short hsum = reinterpret_cast<size_t>(address) & 2 ? (old >> 16) : (old & 0xffff);
|
| 19 |
+
hsum += val;
|
| 20 |
+
old = reinterpret_cast<size_t>(address) & 2
|
| 21 |
+
? (old & 0xffff) | (hsum << 16)
|
| 22 |
+
: (old & 0xffff0000) | hsum;
|
| 23 |
+
old = atomicCAS(address_as_ui, assumed, old);
|
| 24 |
+
|
| 25 |
+
// Note: uses integer comparison to avoid hang in case of NaN (since NaN != NaN)
|
| 26 |
+
} while (assumed != old);
|
| 27 |
+
}
|
| 28 |
+
__device__ __forceinline__ void atomicAdd(__half* address, c10::Half val) {
|
| 29 |
+
unsigned int * address_as_ui = (unsigned int *) ((char *)address - ((size_t)address & 2));
|
| 30 |
+
unsigned int old = *address_as_ui;
|
| 31 |
+
unsigned int assumed;
|
| 32 |
+
|
| 33 |
+
do {
|
| 34 |
+
assumed = old;
|
| 35 |
+
__half_raw hsum;
|
| 36 |
+
hsum.x = (size_t)address & 2 ? (old >> 16) : (old & 0xffff);
|
| 37 |
+
half tmpres = __hadd(hsum, val);
|
| 38 |
+
hsum = __half_raw(tmpres);
|
| 39 |
+
old = (size_t)address & 2 ? (old & 0xffff) | (hsum.x << 16) : (old & 0xffff0000) | hsum.x;
|
| 40 |
+
old = atomicCAS(address_as_ui, assumed, old);
|
| 41 |
+
} while (assumed != old);
|
| 42 |
+
}
|
| 43 |
+
#endif
|
| 44 |
+
|
| 45 |
+
template <typename scalar_t>
|
| 46 |
+
__global__ void VecQuant8MatMulKernel(
|
| 47 |
+
const scalar_t* __restrict__ vec,
|
| 48 |
+
const int* __restrict__ mat,
|
| 49 |
+
scalar_t* __restrict__ mul,
|
| 50 |
+
const scalar_t* __restrict__ scales,
|
| 51 |
+
const int* __restrict__ zeros,
|
| 52 |
+
const int* __restrict__ g_idx,
|
| 53 |
+
int batch,
|
| 54 |
+
int vec_height,
|
| 55 |
+
int height,
|
| 56 |
+
int width,
|
| 57 |
+
int zero_width
|
| 58 |
+
);
|
| 59 |
+
|
| 60 |
+
template <typename scalar_t>
|
| 61 |
+
__global__ void VecQuant8BatchMatMulColumnCompressionKernel(
|
| 62 |
+
const scalar_t* __restrict__ vec,
|
| 63 |
+
const int* __restrict__ mat,
|
| 64 |
+
scalar_t* __restrict__ mul,
|
| 65 |
+
const scalar_t* __restrict__ scales,
|
| 66 |
+
const int* __restrict__ zeros,
|
| 67 |
+
int batch,
|
| 68 |
+
int heads,
|
| 69 |
+
int vec_row,
|
| 70 |
+
int height,
|
| 71 |
+
int width
|
| 72 |
+
);
|
| 73 |
+
|
| 74 |
+
template <typename scalar_t>
|
| 75 |
+
__global__ void VecQuant4BatchMatMulColumnCompressionKernel(
|
| 76 |
+
const scalar_t* __restrict__ vec,
|
| 77 |
+
const int* __restrict__ mat,
|
| 78 |
+
scalar_t* __restrict__ mul,
|
| 79 |
+
const scalar_t* __restrict__ scales,
|
| 80 |
+
const int* __restrict__ zeros,
|
| 81 |
+
int batch,
|
| 82 |
+
int heads,
|
| 83 |
+
int vec_row,
|
| 84 |
+
int height,
|
| 85 |
+
int width
|
| 86 |
+
);
|
| 87 |
+
|
| 88 |
+
template <typename scalar_t>
|
| 89 |
+
__global__ void VecQuant8BatchMatMulKernel(
|
| 90 |
+
const scalar_t* __restrict__ vec,
|
| 91 |
+
const int* __restrict__ mat,
|
| 92 |
+
scalar_t* __restrict__ mul,
|
| 93 |
+
const scalar_t* __restrict__ scales,
|
| 94 |
+
const int* __restrict__ zeros,
|
| 95 |
+
int batch,
|
| 96 |
+
int heads,
|
| 97 |
+
int vec_row,
|
| 98 |
+
int vec_height,
|
| 99 |
+
int height,
|
| 100 |
+
int width,
|
| 101 |
+
int zero_width
|
| 102 |
+
);
|
| 103 |
+
|
| 104 |
+
template <typename scalar_t>
|
| 105 |
+
__global__ void VecQuant4BatchMatMulKernel(
|
| 106 |
+
const scalar_t* __restrict__ vec,
|
| 107 |
+
const int* __restrict__ mat,
|
| 108 |
+
scalar_t* __restrict__ mul,
|
| 109 |
+
const scalar_t* __restrict__ scales,
|
| 110 |
+
const int* __restrict__ zeros,
|
| 111 |
+
int batch,
|
| 112 |
+
int heads,
|
| 113 |
+
int vec_row,
|
| 114 |
+
int vec_height,
|
| 115 |
+
int height,
|
| 116 |
+
int width,
|
| 117 |
+
int zero_width
|
| 118 |
+
);
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
template <typename scalar_t>
|
| 123 |
+
__global__ void VecQuant8BatchMatMulKernel_old(
|
| 124 |
+
const scalar_t* __restrict__ vec,
|
| 125 |
+
const uint8_t* __restrict__ mat,
|
| 126 |
+
scalar_t* __restrict__ mul,
|
| 127 |
+
const scalar_t* __restrict__ scales,
|
| 128 |
+
const scalar_t* __restrict__ zeros,
|
| 129 |
+
int batch,
|
| 130 |
+
int heads,
|
| 131 |
+
int vec_row,
|
| 132 |
+
int vec_height,
|
| 133 |
+
int height,
|
| 134 |
+
int width,
|
| 135 |
+
int zero_width
|
| 136 |
+
);
|
| 137 |
+
|
| 138 |
+
__global__ void VecQuant8BatchMatMulKernel_faster(
|
| 139 |
+
const half* __restrict__ vec,
|
| 140 |
+
const uint8_t* __restrict__ mat,
|
| 141 |
+
half* __restrict__ mul,
|
| 142 |
+
const half* __restrict__ scales,
|
| 143 |
+
const half* __restrict__ zeros,
|
| 144 |
+
int batch,
|
| 145 |
+
int heads,
|
| 146 |
+
int vec_row,
|
| 147 |
+
int vec_height,
|
| 148 |
+
int height,
|
| 149 |
+
int width,
|
| 150 |
+
int zero_width
|
| 151 |
+
);
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
__global__ void VecQuant8BatchMatMulKernel_faster_old(
|
| 156 |
+
const half* __restrict__ vec,
|
| 157 |
+
const uint8_t* __restrict__ mat,
|
| 158 |
+
half* __restrict__ mul,
|
| 159 |
+
const half* __restrict__ scales,
|
| 160 |
+
const half* __restrict__ zeros,
|
| 161 |
+
int batch,
|
| 162 |
+
int heads,
|
| 163 |
+
int vec_row,
|
| 164 |
+
int vec_height,
|
| 165 |
+
int height,
|
| 166 |
+
int width
|
| 167 |
+
);
|
| 168 |
+
|
| 169 |
+
|
| 170 |
+
template <typename scalar_t>
|
| 171 |
+
__global__ void VecQuant4BatchMatMulKernel_old(
|
| 172 |
+
const scalar_t* __restrict__ vec,
|
| 173 |
+
const uint8_t* __restrict__ mat,
|
| 174 |
+
scalar_t* __restrict__ mul,
|
| 175 |
+
const scalar_t* __restrict__ scales,
|
| 176 |
+
const scalar_t* __restrict__ zeros,
|
| 177 |
+
int batch,
|
| 178 |
+
int heads,
|
| 179 |
+
int vec_row,
|
| 180 |
+
int vec_height,
|
| 181 |
+
int height,
|
| 182 |
+
int width,
|
| 183 |
+
int zero_width
|
| 184 |
+
);
|
| 185 |
+
|
| 186 |
+
|
| 187 |
+
template <typename scalar_t>
|
| 188 |
+
__global__ void VecQuant8BatchMatMulColumnCompressionKernel_old(
|
| 189 |
+
const scalar_t* __restrict__ vec,
|
| 190 |
+
const uint8_t* __restrict__ mat,
|
| 191 |
+
scalar_t* __restrict__ mul,
|
| 192 |
+
const scalar_t* __restrict__ scales,
|
| 193 |
+
const scalar_t* __restrict__ zeros,
|
| 194 |
+
int batch,
|
| 195 |
+
int heads,
|
| 196 |
+
int vec_row,
|
| 197 |
+
int height,
|
| 198 |
+
int width
|
| 199 |
+
);
|
| 200 |
+
|
| 201 |
+
__global__ void VecQuant8BatchMatMulColumnCompressionKernel_faster(
|
| 202 |
+
const half* __restrict__ vec,
|
| 203 |
+
const uint8_t* __restrict__ mat,
|
| 204 |
+
half* __restrict__ mul,
|
| 205 |
+
const half* __restrict__ scales,
|
| 206 |
+
const half* __restrict__ zeros,
|
| 207 |
+
int batch,
|
| 208 |
+
int heads,
|
| 209 |
+
int vec_row,
|
| 210 |
+
int height,
|
| 211 |
+
int width
|
| 212 |
+
);
|
| 213 |
+
|
| 214 |
+
__global__ void VecQuant8BatchMatMulColumnCompressionKernel_faster_old(
|
| 215 |
+
const half* __restrict__ vec,
|
| 216 |
+
const uint8_t* __restrict__ mat,
|
| 217 |
+
half* __restrict__ mul,
|
| 218 |
+
const half* __restrict__ scales,
|
| 219 |
+
const half* __restrict__ zeros,
|
| 220 |
+
int batch,
|
| 221 |
+
int heads,
|
| 222 |
+
int vec_row,
|
| 223 |
+
int height,
|
| 224 |
+
int width
|
| 225 |
+
);
|
| 226 |
+
|
| 227 |
+
|
| 228 |
+
template <typename scalar_t>
|
| 229 |
+
__global__ void VecQuant4BatchMatMulColumnCompressionKernel_old(
|
| 230 |
+
const scalar_t* __restrict__ vec,
|
| 231 |
+
const uint8_t* __restrict__ mat,
|
| 232 |
+
scalar_t* __restrict__ mul,
|
| 233 |
+
const scalar_t* __restrict__ scales,
|
| 234 |
+
const scalar_t* __restrict__ zeros,
|
| 235 |
+
int batch,
|
| 236 |
+
int heads,
|
| 237 |
+
int vec_row,
|
| 238 |
+
int height,
|
| 239 |
+
int width
|
| 240 |
+
);
|
| 241 |
+
|
| 242 |
+
|
| 243 |
+
__global__ void VecQuant8BatchMatMulKernel_faster(
|
| 244 |
+
const half* __restrict__ vec,
|
| 245 |
+
const uint8_t* __restrict__ mat,
|
| 246 |
+
half* __restrict__ mul,
|
| 247 |
+
const half* __restrict__ scales,
|
| 248 |
+
const half* __restrict__ zeros,
|
| 249 |
+
int batch,
|
| 250 |
+
int heads,
|
| 251 |
+
int vec_row,
|
| 252 |
+
int vec_height,
|
| 253 |
+
int height,
|
| 254 |
+
int width
|
| 255 |
+
);
|
| 256 |
+
|
| 257 |
+
|
| 258 |
+
__global__ void VecQuant8BatchMatMulColumnCompressionKernel_faster(
|
| 259 |
+
const half* __restrict__ vec,
|
| 260 |
+
const uint8_t* __restrict__ mat,
|
| 261 |
+
half* __restrict__ mul,
|
| 262 |
+
const half* __restrict__ scales,
|
| 263 |
+
const half* __restrict__ zeros,
|
| 264 |
+
int batch,
|
| 265 |
+
int heads,
|
| 266 |
+
int vec_row,
|
| 267 |
+
int height,
|
| 268 |
+
int width
|
| 269 |
+
);
|
| 270 |
+
|
| 271 |
+
const int BLOCKWIDTH = 128;
|
| 272 |
+
const int BLOCKHEIGHT8 = 32;
|
| 273 |
+
const int BLOCKHEIGHT4 = 16;
|
| 274 |
+
const int BLOCKHEIGHT_OLD4 = 128;
|
| 275 |
+
//const int BLOCKHEIGHT_OLD8 = 128;
|
| 276 |
+
|
| 277 |
+
__device__ inline unsigned int as_unsigned(int i) {
|
| 278 |
+
return *reinterpret_cast<unsigned int*>(&i);
|
| 279 |
+
}
|
| 280 |
+
|
| 281 |
+
__device__ inline int as_int(int i) {
|
| 282 |
+
return *reinterpret_cast<int*>(&i);
|
| 283 |
+
}
|
| 284 |
+
|
| 285 |
+
void vecquant8matmul_batched_column_compression_cuda(
|
| 286 |
+
torch::Tensor vec,
|
| 287 |
+
torch::Tensor mat,
|
| 288 |
+
torch::Tensor mul,
|
| 289 |
+
torch::Tensor scales,
|
| 290 |
+
torch::Tensor zeros
|
| 291 |
+
) {
|
| 292 |
+
int batch = vec.size(0);
|
| 293 |
+
int heads = vec.size(1);
|
| 294 |
+
int vec_row = vec.size(2);
|
| 295 |
+
int height = vec.size(3);
|
| 296 |
+
int width = mat.size(3) * 4;
|
| 297 |
+
|
| 298 |
+
dim3 blocks(
|
| 299 |
+
(height + BLOCKWIDTH - 1) / BLOCKWIDTH,
|
| 300 |
+
(width + BLOCKWIDTH - 1) / BLOCKWIDTH
|
| 301 |
+
);
|
| 302 |
+
dim3 threads(BLOCKWIDTH);
|
| 303 |
+
|
| 304 |
+
AT_DISPATCH_FLOATING_TYPES(
|
| 305 |
+
vec.type(), "vecquant8matmul_batched_cuda", ([&] {
|
| 306 |
+
VecQuant8BatchMatMulColumnCompressionKernel<<<blocks, threads>>>(
|
| 307 |
+
vec.data<scalar_t>(), mat.data<int>(), mul.data<scalar_t>(),
|
| 308 |
+
scales.data<scalar_t>(), zeros.data<int>(),
|
| 309 |
+
batch, heads, vec_row, height, width
|
| 310 |
+
);
|
| 311 |
+
})
|
| 312 |
+
);
|
| 313 |
+
|
| 314 |
+
}
|
| 315 |
+
|
| 316 |
+
template <typename scalar_t>
|
| 317 |
+
__global__ void VecQuant8BatchMatMulColumnCompressionKernel(
|
| 318 |
+
const scalar_t* __restrict__ vec,
|
| 319 |
+
const int* __restrict__ mat,
|
| 320 |
+
scalar_t* __restrict__ mul,
|
| 321 |
+
const scalar_t* __restrict__ scales,
|
| 322 |
+
const int* __restrict__ zeros,
|
| 323 |
+
int batch,
|
| 324 |
+
int heads,
|
| 325 |
+
int vec_row,
|
| 326 |
+
int height,
|
| 327 |
+
int width
|
| 328 |
+
) {
|
| 329 |
+
int weight_total = batch * heads * height * width / 4;
|
| 330 |
+
int input_total = batch * heads * vec_row * height;
|
| 331 |
+
int out_total = batch * heads * vec_row * width;
|
| 332 |
+
int tid = threadIdx.x;
|
| 333 |
+
// h is index of height with step being BLOCKWIDTH
|
| 334 |
+
int h = BLOCKWIDTH * blockIdx.x;
|
| 335 |
+
// w is index of width with step being 1
|
| 336 |
+
int w = BLOCKWIDTH * blockIdx.y + tid;
|
| 337 |
+
if (w >= width && tid >= height) {
|
| 338 |
+
return;
|
| 339 |
+
}
|
| 340 |
+
|
| 341 |
+
__shared__ scalar_t blockvec[BLOCKWIDTH];
|
| 342 |
+
int k;
|
| 343 |
+
scalar_t w_tmp;
|
| 344 |
+
|
| 345 |
+
float weight[BLOCKWIDTH];
|
| 346 |
+
|
| 347 |
+
for (int b = 0; b < batch; ++b){
|
| 348 |
+
for (int head = 0; head < heads; ++head){
|
| 349 |
+
int batch_shift = b * heads + head;
|
| 350 |
+
for (k = 0; k < BLOCKWIDTH && h + k < height; ++k){
|
| 351 |
+
int i_w = (w / 4);
|
| 352 |
+
int w_bit = (w % 4) * 8;
|
| 353 |
+
|
| 354 |
+
int w_index = (batch_shift * height + h + k) * width / 4 + i_w;
|
| 355 |
+
if (w_index >= weight_total || w >= width) {
|
| 356 |
+
weight[k] = 0;
|
| 357 |
+
} else {
|
| 358 |
+
scalar_t scale = scales[batch_shift * height + h + k];
|
| 359 |
+
scalar_t zero = zeros[batch_shift * height + h + k];
|
| 360 |
+
w_tmp = ((as_unsigned(mat[w_index]) >> w_bit) & 0xFF);
|
| 361 |
+
weight[k] = scale * (w_tmp - zero);
|
| 362 |
+
}
|
| 363 |
+
}
|
| 364 |
+
|
| 365 |
+
scalar_t res;
|
| 366 |
+
for (int vr = 0; vr < vec_row; ++vr){
|
| 367 |
+
res = 0;
|
| 368 |
+
int vec_index = (batch_shift * vec_row + vr) * height + blockIdx.x * BLOCKWIDTH + tid;
|
| 369 |
+
if (vec_index < input_total) {
|
| 370 |
+
blockvec[tid] = vec[vec_index];
|
| 371 |
+
} else {
|
| 372 |
+
blockvec[tid] = 0;
|
| 373 |
+
}
|
| 374 |
+
|
| 375 |
+
__syncthreads();
|
| 376 |
+
for (k = 0; k < BLOCKWIDTH && h + k < height; ++k){
|
| 377 |
+
// res is the dot product of BLOCKWIDTH elements (part of width)
|
| 378 |
+
res += weight[k] * blockvec[k];
|
| 379 |
+
}
|
| 380 |
+
// add res to the final result, final matrix shape: (batch, vec_row, width)
|
| 381 |
+
int out_index = (batch_shift * vec_row + vr) * width + w;
|
| 382 |
+
if (out_index < out_total) {
|
| 383 |
+
atomicAdd(&mul[out_index], res);
|
| 384 |
+
}
|
| 385 |
+
__syncthreads();
|
| 386 |
+
}
|
| 387 |
+
}
|
| 388 |
+
}
|
| 389 |
+
}
|
| 390 |
+
|
| 391 |
+
void vecquant8matmul_batched_cuda(
|
| 392 |
+
torch::Tensor vec,
|
| 393 |
+
torch::Tensor mat,
|
| 394 |
+
torch::Tensor mul,
|
| 395 |
+
torch::Tensor scales,
|
| 396 |
+
torch::Tensor zeros
|
| 397 |
+
) {
|
| 398 |
+
int batch = vec.size(0);
|
| 399 |
+
int heads = vec.size(1);
|
| 400 |
+
int vec_row = vec.size(2);
|
| 401 |
+
int vec_height = vec.size(3);
|
| 402 |
+
int height = mat.size(2);
|
| 403 |
+
int width = mat.size(3);
|
| 404 |
+
int zero_width = zeros.size(2);
|
| 405 |
+
|
| 406 |
+
dim3 blocks(
|
| 407 |
+
(height + BLOCKHEIGHT8 - 1) / BLOCKHEIGHT8,
|
| 408 |
+
(width + BLOCKWIDTH - 1) / BLOCKWIDTH
|
| 409 |
+
);
|
| 410 |
+
dim3 threads(BLOCKWIDTH);
|
| 411 |
+
|
| 412 |
+
AT_DISPATCH_FLOATING_TYPES(
|
| 413 |
+
vec.type(), "vecquant8matmul_batched_cuda", ([&] {
|
| 414 |
+
VecQuant8BatchMatMulKernel<<<blocks, threads>>>(
|
| 415 |
+
vec.data<scalar_t>(), mat.data<int>(), mul.data<scalar_t>(),
|
| 416 |
+
scales.data<scalar_t>(), zeros.data<int>(),
|
| 417 |
+
batch, heads, vec_row, vec_height, height, width, zero_width
|
| 418 |
+
);
|
| 419 |
+
})
|
| 420 |
+
);
|
| 421 |
+
|
| 422 |
+
}
|
| 423 |
+
|
| 424 |
+
template <typename scalar_t>
|
| 425 |
+
__global__ void VecQuant8BatchMatMulKernel(
|
| 426 |
+
const scalar_t* __restrict__ vec,
|
| 427 |
+
const int* __restrict__ mat,
|
| 428 |
+
scalar_t* __restrict__ mul,
|
| 429 |
+
const scalar_t* __restrict__ scales,
|
| 430 |
+
const int* __restrict__ zeros,
|
| 431 |
+
int batch,
|
| 432 |
+
int heads,
|
| 433 |
+
int vec_row,
|
| 434 |
+
int vec_height,
|
| 435 |
+
int height,
|
| 436 |
+
int width,
|
| 437 |
+
int zero_width
|
| 438 |
+
) {
|
| 439 |
+
int weight_total = batch * heads * height * width;
|
| 440 |
+
int input_total = batch * heads * vec_row * vec_height;
|
| 441 |
+
int out_total = batch * heads * vec_row * width;
|
| 442 |
+
int tid = threadIdx.x;
|
| 443 |
+
// h is index of height with step being BLOCKHEIGHT8
|
| 444 |
+
int h = BLOCKHEIGHT8 * blockIdx.x;
|
| 445 |
+
// w is index of width with step being 1
|
| 446 |
+
int w = BLOCKWIDTH * blockIdx.y + tid;
|
| 447 |
+
if (w >= width && tid >= vec_height) {
|
| 448 |
+
return;
|
| 449 |
+
}
|
| 450 |
+
|
| 451 |
+
__shared__ scalar_t blockvec[BLOCKWIDTH];
|
| 452 |
+
// i is index of mat of block first row
|
| 453 |
+
int i = width * h + w;
|
| 454 |
+
// if (i >= width * height) {
|
| 455 |
+
// return;
|
| 456 |
+
// }
|
| 457 |
+
int k;
|
| 458 |
+
scalar_t w_tmp;
|
| 459 |
+
|
| 460 |
+
int z_w = w / 4;
|
| 461 |
+
int z_mod = (w % 4) * 8;
|
| 462 |
+
|
| 463 |
+
float weight[BLOCKWIDTH];
|
| 464 |
+
|
| 465 |
+
for (int b = 0; b < batch; ++b){
|
| 466 |
+
for (int head = 0; head < heads; ++head){
|
| 467 |
+
int batch_shift = b * heads + head;
|
| 468 |
+
for (k = 0; k < BLOCKWIDTH && h * 4 + k < vec_height; ++k){
|
| 469 |
+
int k_w = (k / 4);
|
| 470 |
+
int k_bit = (k % 4) * 8;
|
| 471 |
+
|
| 472 |
+
int w_index = batch_shift * height * width + i + (k_w * width);
|
| 473 |
+
if (w_index >= weight_total || w >= width) {
|
| 474 |
+
weight[k] = 0;
|
| 475 |
+
} else {
|
| 476 |
+
scalar_t scale = scales[batch_shift * width + w];
|
| 477 |
+
scalar_t zero;
|
| 478 |
+
if (zero_width == width) {
|
| 479 |
+
zero = zeros[batch_shift * width + w];
|
| 480 |
+
} else {
|
| 481 |
+
zero = scalar_t(((as_unsigned(zeros[batch_shift * zero_width + z_w]) >> z_mod) & 0xFF) + 1);
|
| 482 |
+
}
|
| 483 |
+
w_tmp = ((as_unsigned(mat[w_index]) >> k_bit) & 0xFF);
|
| 484 |
+
weight[k] = scale * (w_tmp - zero);
|
| 485 |
+
}
|
| 486 |
+
}
|
| 487 |
+
|
| 488 |
+
scalar_t res;
|
| 489 |
+
for (int vr = 0; vr < vec_row; ++vr){
|
| 490 |
+
res = 0;
|
| 491 |
+
int vec_index = (batch_shift * vec_row + vr) * vec_height + blockIdx.x * BLOCKWIDTH + tid;
|
| 492 |
+
if (vec_index < input_total) {
|
| 493 |
+
blockvec[tid] = vec[vec_index];
|
| 494 |
+
} else {
|
| 495 |
+
blockvec[tid] = 0;
|
| 496 |
+
}
|
| 497 |
+
|
| 498 |
+
__syncthreads();
|
| 499 |
+
for (k = 0; k < BLOCKWIDTH && h * 4 + k < vec_height; ++k){
|
| 500 |
+
// res is the dot product of BLOCKWIDTH elements (part of width)
|
| 501 |
+
res += weight[k] * blockvec[k];
|
| 502 |
+
}
|
| 503 |
+
// add res to the final result, final matrix shape: (batch, vec_row, width)
|
| 504 |
+
int out_index = (batch_shift * vec_row + vr) * width + w;
|
| 505 |
+
if (out_index < out_total) {
|
| 506 |
+
atomicAdd(&mul[out_index], res);
|
| 507 |
+
}
|
| 508 |
+
__syncthreads();
|
| 509 |
+
}
|
| 510 |
+
}
|
| 511 |
+
}
|
| 512 |
+
}
|
| 513 |
+
|
| 514 |
+
|
| 515 |
+
void vecquant8matmul_cuda(
|
| 516 |
+
torch::Tensor vec,
|
| 517 |
+
torch::Tensor mat,
|
| 518 |
+
torch::Tensor mul,
|
| 519 |
+
torch::Tensor scales,
|
| 520 |
+
torch::Tensor zeros,
|
| 521 |
+
torch::Tensor g_idx
|
| 522 |
+
) {
|
| 523 |
+
int batch = vec.size(0);
|
| 524 |
+
int vec_height = vec.size(1);
|
| 525 |
+
int height = mat.size(0);
|
| 526 |
+
int width = mat.size(1);
|
| 527 |
+
int zero_width = zeros.size(1);
|
| 528 |
+
|
| 529 |
+
dim3 blocks(
|
| 530 |
+
(height + BLOCKHEIGHT8 - 1) / BLOCKHEIGHT8,
|
| 531 |
+
(width + BLOCKWIDTH - 1) / BLOCKWIDTH
|
| 532 |
+
);
|
| 533 |
+
dim3 threads(BLOCKWIDTH);
|
| 534 |
+
|
| 535 |
+
AT_DISPATCH_FLOATING_TYPES(
|
| 536 |
+
vec.type(), "vecquant8matmul_cuda", ([&] {
|
| 537 |
+
VecQuant8MatMulKernel<<<blocks, threads>>>(
|
| 538 |
+
vec.data<scalar_t>(), mat.data<int>(), mul.data<scalar_t>(),
|
| 539 |
+
scales.data<scalar_t>(), zeros.data<int>(), g_idx.data<int>(),
|
| 540 |
+
batch, vec_height, height, width, zero_width
|
| 541 |
+
);
|
| 542 |
+
})
|
| 543 |
+
);
|
| 544 |
+
}
|
| 545 |
+
|
| 546 |
+
template <typename scalar_t>
|
| 547 |
+
__global__ void VecQuant8MatMulKernel(
|
| 548 |
+
const scalar_t* __restrict__ vec,
|
| 549 |
+
const int* __restrict__ mat,
|
| 550 |
+
scalar_t* __restrict__ mul,
|
| 551 |
+
const scalar_t* __restrict__ scales,
|
| 552 |
+
const int* __restrict__ zeros,
|
| 553 |
+
const int* __restrict__ g_idx,
|
| 554 |
+
int batch,
|
| 555 |
+
int vec_height,
|
| 556 |
+
int height,
|
| 557 |
+
int width,
|
| 558 |
+
int zero_width
|
| 559 |
+
) {
|
| 560 |
+
int h = BLOCKHEIGHT8 * blockIdx.x;
|
| 561 |
+
int w = BLOCKWIDTH * blockIdx.y + threadIdx.x;
|
| 562 |
+
|
| 563 |
+
__shared__ scalar_t blockvec[BLOCKWIDTH];
|
| 564 |
+
int i = width * h + w;
|
| 565 |
+
int g_h = h * 4;
|
| 566 |
+
int k;
|
| 567 |
+
unsigned int g;
|
| 568 |
+
scalar_t w_tmp;
|
| 569 |
+
|
| 570 |
+
int z_w = w / 4;
|
| 571 |
+
int z_mod = (w % 4) * 8;
|
| 572 |
+
|
| 573 |
+
float weight[BLOCKWIDTH];
|
| 574 |
+
|
| 575 |
+
for (k = 0; k < BLOCKWIDTH; ++k){
|
| 576 |
+
int k_w = (k / 4);
|
| 577 |
+
int k_bit = (k % 4) * 8;
|
| 578 |
+
|
| 579 |
+
g = as_int(g_idx[g_h + k]);
|
| 580 |
+
scalar_t scale = scales[g * width + w];
|
| 581 |
+
scalar_t zero = scalar_t(((as_unsigned(zeros[g * zero_width + z_w]) >> z_mod) & 0xFF) + 1);
|
| 582 |
+
|
| 583 |
+
w_tmp = ((as_unsigned(mat[i + (k_w * width)]) >> k_bit) & 0xFF);
|
| 584 |
+
|
| 585 |
+
weight[k] = scale * (w_tmp - zero);
|
| 586 |
+
}
|
| 587 |
+
|
| 588 |
+
|
| 589 |
+
scalar_t res;
|
| 590 |
+
for (int b = 0; b < batch; ++b){
|
| 591 |
+
res = 0;
|
| 592 |
+
blockvec[threadIdx.x] = vec[b * vec_height + blockIdx.x * BLOCKWIDTH + threadIdx.x];
|
| 593 |
+
__syncthreads();
|
| 594 |
+
for (k = 0; k < BLOCKWIDTH; ++k){
|
| 595 |
+
res += weight[k] * blockvec[k];
|
| 596 |
+
}
|
| 597 |
+
atomicAdd(&mul[b * width + w], res);
|
| 598 |
+
__syncthreads();
|
| 599 |
+
}
|
| 600 |
+
}
|
| 601 |
+
|
| 602 |
+
|
| 603 |
+
|
| 604 |
+
void vecquant4matmul_batched_cuda(
|
| 605 |
+
torch::Tensor vec,
|
| 606 |
+
torch::Tensor mat,
|
| 607 |
+
torch::Tensor mul,
|
| 608 |
+
torch::Tensor scales,
|
| 609 |
+
torch::Tensor zeros
|
| 610 |
+
) {
|
| 611 |
+
int batch = vec.size(0);
|
| 612 |
+
int heads = vec.size(1);
|
| 613 |
+
int vec_row = vec.size(2);
|
| 614 |
+
int vec_height = vec.size(3);
|
| 615 |
+
int height = mat.size(2);
|
| 616 |
+
int width = mat.size(3);
|
| 617 |
+
int zero_width = zeros.size(2);
|
| 618 |
+
|
| 619 |
+
dim3 blocks(
|
| 620 |
+
(height + BLOCKHEIGHT4 - 1) / BLOCKHEIGHT4,
|
| 621 |
+
(width + BLOCKWIDTH - 1) / BLOCKWIDTH
|
| 622 |
+
);
|
| 623 |
+
dim3 threads(BLOCKWIDTH);
|
| 624 |
+
|
| 625 |
+
AT_DISPATCH_FLOATING_TYPES(
|
| 626 |
+
vec.type(), "vecquant4matmul_batched_cuda", ([&] {
|
| 627 |
+
VecQuant4BatchMatMulKernel<<<blocks, threads>>>(
|
| 628 |
+
vec.data<scalar_t>(), mat.data<int>(), mul.data<scalar_t>(),
|
| 629 |
+
scales.data<scalar_t>(), zeros.data<int>(),
|
| 630 |
+
batch, heads, vec_row, vec_height, height, width, zero_width
|
| 631 |
+
);
|
| 632 |
+
})
|
| 633 |
+
);
|
| 634 |
+
|
| 635 |
+
}
|
| 636 |
+
|
| 637 |
+
template <typename scalar_t>
|
| 638 |
+
__global__ void VecQuant4BatchMatMulKernel(
|
| 639 |
+
const scalar_t* __restrict__ vec,
|
| 640 |
+
const int* __restrict__ mat,
|
| 641 |
+
scalar_t* __restrict__ mul,
|
| 642 |
+
const scalar_t* __restrict__ scales,
|
| 643 |
+
const int* __restrict__ zeros,
|
| 644 |
+
int batch,
|
| 645 |
+
int heads,
|
| 646 |
+
int vec_row,
|
| 647 |
+
int vec_height,
|
| 648 |
+
int height,
|
| 649 |
+
int width,
|
| 650 |
+
int zero_width
|
| 651 |
+
) {
|
| 652 |
+
int weight_total = batch * heads * height * width;
|
| 653 |
+
int input_total = batch * heads * vec_row * vec_height;
|
| 654 |
+
int out_total = batch * heads * vec_row * width;
|
| 655 |
+
int tid = threadIdx.x;
|
| 656 |
+
// h is index of height with step being BLOCKHEIGHT4
|
| 657 |
+
int h = BLOCKHEIGHT4 * blockIdx.x;
|
| 658 |
+
// w is index of width with step being 1
|
| 659 |
+
int w = BLOCKWIDTH * blockIdx.y + tid;
|
| 660 |
+
if (w >= width && tid >= vec_height) {
|
| 661 |
+
return;
|
| 662 |
+
}
|
| 663 |
+
|
| 664 |
+
__shared__ scalar_t blockvec[BLOCKWIDTH];
|
| 665 |
+
// i is index of mat of block first row
|
| 666 |
+
int i = width * h + w;
|
| 667 |
+
int k;
|
| 668 |
+
scalar_t w_tmp;
|
| 669 |
+
|
| 670 |
+
int z_w = w / 8;
|
| 671 |
+
int z_mod = (w % 8) * 4;
|
| 672 |
+
|
| 673 |
+
float weight[BLOCKWIDTH];
|
| 674 |
+
|
| 675 |
+
for (int b = 0; b < batch; ++b){
|
| 676 |
+
for (int head = 0; head < heads; ++head){
|
| 677 |
+
int batch_shift = b * heads + head;
|
| 678 |
+
for (k = 0; k < BLOCKWIDTH && h * 8 + k < vec_height; ++k){
|
| 679 |
+
int k_w = (k / 8);
|
| 680 |
+
int k_bit = (k % 8) * 4;
|
| 681 |
+
|
| 682 |
+
int w_index = batch_shift * height * width + i + (k_w * width);
|
| 683 |
+
if (w_index >= weight_total || w >= width) {
|
| 684 |
+
weight[k] = 0;
|
| 685 |
+
} else {
|
| 686 |
+
scalar_t scale = scales[batch_shift * width + w];
|
| 687 |
+
scalar_t zero;
|
| 688 |
+
if (zero_width == width) {
|
| 689 |
+
zero = zeros[batch_shift * width + w];
|
| 690 |
+
} else {
|
| 691 |
+
zero = scalar_t(((as_unsigned(zeros[batch_shift * zero_width + z_w]) >> z_mod) & 0xF));
|
| 692 |
+
}
|
| 693 |
+
w_tmp = ((as_unsigned(mat[w_index]) >> k_bit) & 0xF);
|
| 694 |
+
weight[k] = scale * (w_tmp - zero);
|
| 695 |
+
}
|
| 696 |
+
}
|
| 697 |
+
|
| 698 |
+
scalar_t res;
|
| 699 |
+
for (int vr = 0; vr < vec_row; ++vr){
|
| 700 |
+
res = 0;
|
| 701 |
+
int vec_index = (batch_shift * vec_row + vr) * vec_height + blockIdx.x * BLOCKWIDTH + tid;
|
| 702 |
+
if (vec_index < input_total) {
|
| 703 |
+
blockvec[tid] = vec[vec_index];
|
| 704 |
+
} else {
|
| 705 |
+
blockvec[tid] = 0;
|
| 706 |
+
}
|
| 707 |
+
|
| 708 |
+
__syncthreads();
|
| 709 |
+
for (k = 0; k < BLOCKWIDTH && h * 8 + k < vec_height; ++k){
|
| 710 |
+
// res is the dot product of BLOCKWIDTH elements (part of width)
|
| 711 |
+
res += weight[k] * blockvec[k];
|
| 712 |
+
}
|
| 713 |
+
// add res to the final result, final matrix shape: (batch, vec_row, width)
|
| 714 |
+
int out_index = (batch_shift * vec_row + vr) * width + w;
|
| 715 |
+
if (out_index < out_total) {
|
| 716 |
+
atomicAdd(&mul[out_index], res);
|
| 717 |
+
}
|
| 718 |
+
__syncthreads();
|
| 719 |
+
}
|
| 720 |
+
}
|
| 721 |
+
}
|
| 722 |
+
}
|
| 723 |
+
|
| 724 |
+
|
| 725 |
+
|
| 726 |
+
void vecquant4matmul_batched_column_compression_cuda(
|
| 727 |
+
torch::Tensor vec,
|
| 728 |
+
torch::Tensor mat,
|
| 729 |
+
torch::Tensor mul,
|
| 730 |
+
torch::Tensor scales,
|
| 731 |
+
torch::Tensor zeros
|
| 732 |
+
) {
|
| 733 |
+
int batch = vec.size(0);
|
| 734 |
+
int heads = vec.size(1);
|
| 735 |
+
int vec_row = vec.size(2);
|
| 736 |
+
int height = vec.size(3);
|
| 737 |
+
int width = mat.size(3) * 8;
|
| 738 |
+
|
| 739 |
+
dim3 blocks(
|
| 740 |
+
(height + BLOCKWIDTH - 1) / BLOCKWIDTH,
|
| 741 |
+
(width + BLOCKWIDTH - 1) / BLOCKWIDTH
|
| 742 |
+
);
|
| 743 |
+
dim3 threads(BLOCKWIDTH);
|
| 744 |
+
|
| 745 |
+
AT_DISPATCH_FLOATING_TYPES(
|
| 746 |
+
vec.type(), "vecquant4matmul_batched_cuda", ([&] {
|
| 747 |
+
VecQuant4BatchMatMulColumnCompressionKernel<<<blocks, threads>>>(
|
| 748 |
+
vec.data<scalar_t>(), mat.data<int>(), mul.data<scalar_t>(),
|
| 749 |
+
scales.data<scalar_t>(), zeros.data<int>(),
|
| 750 |
+
batch, heads, vec_row, height, width
|
| 751 |
+
);
|
| 752 |
+
})
|
| 753 |
+
);
|
| 754 |
+
|
| 755 |
+
}
|
| 756 |
+
|
| 757 |
+
template <typename scalar_t>
|
| 758 |
+
__global__ void VecQuant4BatchMatMulColumnCompressionKernel(
|
| 759 |
+
const scalar_t* __restrict__ vec,
|
| 760 |
+
const int* __restrict__ mat,
|
| 761 |
+
scalar_t* __restrict__ mul,
|
| 762 |
+
const scalar_t* __restrict__ scales,
|
| 763 |
+
const int* __restrict__ zeros,
|
| 764 |
+
int batch,
|
| 765 |
+
int heads,
|
| 766 |
+
int vec_row,
|
| 767 |
+
int height,
|
| 768 |
+
int width
|
| 769 |
+
) {
|
| 770 |
+
int weight_total = batch * heads * height * width / 8;
|
| 771 |
+
int input_total = batch * heads * vec_row * height;
|
| 772 |
+
int out_total = batch * heads * vec_row * width;
|
| 773 |
+
int tid = threadIdx.x;
|
| 774 |
+
// h is index of height with step being BLOCKWIDTH
|
| 775 |
+
int h = BLOCKWIDTH * blockIdx.x;
|
| 776 |
+
// w is index of width with step being 1
|
| 777 |
+
int w = BLOCKWIDTH * blockIdx.y + tid;
|
| 778 |
+
if (w >= width && tid >= height) {
|
| 779 |
+
return;
|
| 780 |
+
}
|
| 781 |
+
|
| 782 |
+
__shared__ scalar_t blockvec[BLOCKWIDTH];
|
| 783 |
+
int k;
|
| 784 |
+
scalar_t w_tmp;
|
| 785 |
+
|
| 786 |
+
float weight[BLOCKWIDTH];
|
| 787 |
+
|
| 788 |
+
for (int b = 0; b < batch; ++b){
|
| 789 |
+
for (int head = 0; head < heads; ++head){
|
| 790 |
+
int batch_shift = b * heads + head;
|
| 791 |
+
for (k = 0; k < BLOCKWIDTH && h + k < height; ++k){
|
| 792 |
+
int i_w = (w / 8);
|
| 793 |
+
int w_bit = (w % 8) * 4;
|
| 794 |
+
|
| 795 |
+
int w_index = (batch_shift * height + h + k) * width / 8 + i_w;
|
| 796 |
+
if (w_index >= weight_total || w >= width) {
|
| 797 |
+
weight[k] = 0;
|
| 798 |
+
} else {
|
| 799 |
+
scalar_t scale = scales[batch_shift * height + h + k];
|
| 800 |
+
scalar_t zero = zeros[batch_shift * height + h + k];
|
| 801 |
+
w_tmp = ((as_unsigned(mat[w_index]) >> w_bit) & 0xF);
|
| 802 |
+
weight[k] = scale * (w_tmp - zero);
|
| 803 |
+
}
|
| 804 |
+
}
|
| 805 |
+
|
| 806 |
+
scalar_t res;
|
| 807 |
+
for (int vr = 0; vr < vec_row; ++vr){
|
| 808 |
+
res = 0;
|
| 809 |
+
int vec_index = (batch_shift * vec_row + vr) * height + blockIdx.x * BLOCKWIDTH + tid;
|
| 810 |
+
if (vec_index < input_total) {
|
| 811 |
+
blockvec[tid] = vec[vec_index];
|
| 812 |
+
} else {
|
| 813 |
+
blockvec[tid] = 0;
|
| 814 |
+
}
|
| 815 |
+
|
| 816 |
+
__syncthreads();
|
| 817 |
+
for (k = 0; k < BLOCKWIDTH && h + k < height; ++k){
|
| 818 |
+
// res is the dot product of BLOCKWIDTH elements (part of width)
|
| 819 |
+
res += weight[k] * blockvec[k];
|
| 820 |
+
}
|
| 821 |
+
// add res to the final result, final matrix shape: (batch, vec_row, width)
|
| 822 |
+
int out_index = (batch_shift * vec_row + vr) * width + w;
|
| 823 |
+
if (out_index < out_total) {
|
| 824 |
+
atomicAdd(&mul[out_index], res);
|
| 825 |
+
}
|
| 826 |
+
__syncthreads();
|
| 827 |
+
}
|
| 828 |
+
}
|
| 829 |
+
}
|
| 830 |
+
}
|
| 831 |
+
|
| 832 |
+
|
| 833 |
+
void vecquant8matmul_batched_old_cuda(
|
| 834 |
+
torch::Tensor vec,
|
| 835 |
+
torch::Tensor mat,
|
| 836 |
+
torch::Tensor mul,
|
| 837 |
+
torch::Tensor scales,
|
| 838 |
+
torch::Tensor zeros
|
| 839 |
+
) {
|
| 840 |
+
int batch = vec.size(0);
|
| 841 |
+
int heads = vec.size(1);
|
| 842 |
+
int vec_row = vec.size(2);
|
| 843 |
+
int vec_height = vec.size(3);
|
| 844 |
+
int height = mat.size(2);
|
| 845 |
+
int width = mat.size(3);
|
| 846 |
+
int zero_width = zeros.size(2);
|
| 847 |
+
|
| 848 |
+
dim3 blocks(
|
| 849 |
+
(height + BLOCKWIDTH - 1) / BLOCKWIDTH,
|
| 850 |
+
(width + BLOCKWIDTH - 1) / BLOCKWIDTH
|
| 851 |
+
);
|
| 852 |
+
dim3 threads(BLOCKWIDTH);
|
| 853 |
+
|
| 854 |
+
AT_DISPATCH_FLOATING_TYPES(
|
| 855 |
+
vec.type(), "vecquant8matmul_batched_old_cuda", ([&] {
|
| 856 |
+
VecQuant8BatchMatMulKernel_old<<<blocks, threads>>>(
|
| 857 |
+
vec.data<scalar_t>(), mat.data<uint8_t>(), mul.data<scalar_t>(),
|
| 858 |
+
scales.data<scalar_t>(), zeros.data<scalar_t>(),
|
| 859 |
+
batch, heads, vec_row, vec_height, height, width, zero_width
|
| 860 |
+
);
|
| 861 |
+
})
|
| 862 |
+
);
|
| 863 |
+
}
|
| 864 |
+
|
| 865 |
+
|
| 866 |
+
template <typename scalar_t>
|
| 867 |
+
__global__ void VecQuant8BatchMatMulKernel_old(
|
| 868 |
+
const scalar_t* __restrict__ vec,
|
| 869 |
+
const uint8_t* __restrict__ mat,
|
| 870 |
+
scalar_t* __restrict__ mul,
|
| 871 |
+
const scalar_t* __restrict__ scales,
|
| 872 |
+
const scalar_t* __restrict__ zeros,
|
| 873 |
+
int batch,
|
| 874 |
+
int heads,
|
| 875 |
+
int vec_row,
|
| 876 |
+
int vec_height,
|
| 877 |
+
int height,
|
| 878 |
+
int width,
|
| 879 |
+
int zero_width
|
| 880 |
+
) {
|
| 881 |
+
int weight_total = batch * heads * height * width;
|
| 882 |
+
int input_total = batch * heads * vec_row * vec_height;
|
| 883 |
+
int out_total = batch * heads * vec_row * width;
|
| 884 |
+
int tid = threadIdx.x;
|
| 885 |
+
// h is index of height with step being BLOCKHEIGHT8
|
| 886 |
+
int h = BLOCKWIDTH * blockIdx.x;
|
| 887 |
+
// w is index of width with step being 1
|
| 888 |
+
int w = BLOCKWIDTH * blockIdx.y + tid;
|
| 889 |
+
if (w >= width && tid >= vec_height) {
|
| 890 |
+
return;
|
| 891 |
+
}
|
| 892 |
+
|
| 893 |
+
__shared__ scalar_t blockvec[BLOCKWIDTH];
|
| 894 |
+
// i is index of mat of block first row
|
| 895 |
+
int i = width * h + w;
|
| 896 |
+
int k;
|
| 897 |
+
scalar_t w_tmp;
|
| 898 |
+
|
| 899 |
+
float weight[BLOCKWIDTH];
|
| 900 |
+
for (int b = 0; b < batch; ++b){
|
| 901 |
+
for (int head = 0; head < heads; ++head){
|
| 902 |
+
int batch_shift = b * heads + head;
|
| 903 |
+
for (k = 0; k < BLOCKWIDTH && h + k < vec_height; ++k){
|
| 904 |
+
int k_w = k;
|
| 905 |
+
int w_index = batch_shift * height * width + i + (k_w * width);
|
| 906 |
+
if (w_index >= weight_total || w >= width) {
|
| 907 |
+
weight[k] = 0;
|
| 908 |
+
} else {
|
| 909 |
+
scalar_t scale = scales[batch_shift * width + w];
|
| 910 |
+
scalar_t zero = zeros[batch_shift * width + w];
|
| 911 |
+
w_tmp = as_unsigned(mat[w_index]);
|
| 912 |
+
weight[k] = scale * (w_tmp - zero);
|
| 913 |
+
}
|
| 914 |
+
}
|
| 915 |
+
|
| 916 |
+
scalar_t res;
|
| 917 |
+
for (int vr = 0; vr < vec_row; ++vr){
|
| 918 |
+
res = 0;
|
| 919 |
+
int vec_index = (batch_shift * vec_row + vr) * vec_height + blockIdx.x * BLOCKWIDTH + tid;
|
| 920 |
+
if (vec_index < input_total) {
|
| 921 |
+
blockvec[tid] = vec[vec_index];
|
| 922 |
+
} else {
|
| 923 |
+
blockvec[tid] = 0;
|
| 924 |
+
}
|
| 925 |
+
|
| 926 |
+
__syncthreads();
|
| 927 |
+
for (k = 0; k < BLOCKWIDTH && h + k < vec_height; ++k){
|
| 928 |
+
// res is the dot product of BLOCKWIDTH elements (part of width)
|
| 929 |
+
res += weight[k] * blockvec[k];
|
| 930 |
+
}
|
| 931 |
+
// add res to the final result, final matrix shape: (batch, vec_row, width)
|
| 932 |
+
int out_index = (batch_shift * vec_row + vr) * width + w;
|
| 933 |
+
if (out_index < out_total) {
|
| 934 |
+
atomicAdd(&mul[out_index], res);
|
| 935 |
+
}
|
| 936 |
+
__syncthreads();
|
| 937 |
+
}
|
| 938 |
+
}
|
| 939 |
+
}
|
| 940 |
+
}
|
| 941 |
+
|
| 942 |
+
|
| 943 |
+
|
| 944 |
+
void vecquant8matmul_batched_faster_cuda(
|
| 945 |
+
torch::Tensor vec,
|
| 946 |
+
torch::Tensor mat,
|
| 947 |
+
torch::Tensor mul,
|
| 948 |
+
torch::Tensor scales,
|
| 949 |
+
torch::Tensor zeros
|
| 950 |
+
) {
|
| 951 |
+
int batch = vec.size(0);
|
| 952 |
+
int heads = vec.size(1);
|
| 953 |
+
int vec_row = vec.size(2);
|
| 954 |
+
int vec_height = vec.size(3);
|
| 955 |
+
int height = mat.size(2);
|
| 956 |
+
int width = mat.size(3);
|
| 957 |
+
int zero_width = zeros.size(2);
|
| 958 |
+
|
| 959 |
+
dim3 blocks(
|
| 960 |
+
(height + BLOCKWIDTH - 1) / BLOCKWIDTH,
|
| 961 |
+
(width + BLOCKWIDTH - 1) / BLOCKWIDTH
|
| 962 |
+
);
|
| 963 |
+
dim3 threads(BLOCKWIDTH);
|
| 964 |
+
|
| 965 |
+
VecQuant8BatchMatMulKernel_faster<<<blocks, threads>>>(
|
| 966 |
+
(half*) vec.data_ptr(),
|
| 967 |
+
(uint8_t*) mat.data_ptr(),
|
| 968 |
+
(half*) mul.data_ptr(),
|
| 969 |
+
(half*) scales.data_ptr(),
|
| 970 |
+
(half*) zeros.data_ptr(),
|
| 971 |
+
batch, heads, vec_row, vec_height, height, width, zero_width
|
| 972 |
+
);
|
| 973 |
+
}
|
| 974 |
+
|
| 975 |
+
|
| 976 |
+
|
| 977 |
+
__global__ void VecQuant8BatchMatMulKernel_faster(
|
| 978 |
+
const half* __restrict__ vec,
|
| 979 |
+
const uint8_t* __restrict__ mat,
|
| 980 |
+
half* __restrict__ mul,
|
| 981 |
+
const half* __restrict__ scales,
|
| 982 |
+
const half* __restrict__ zeros,
|
| 983 |
+
int batch,
|
| 984 |
+
int heads,
|
| 985 |
+
int vec_row,
|
| 986 |
+
int vec_height,
|
| 987 |
+
int height,
|
| 988 |
+
int width,
|
| 989 |
+
int zero_width
|
| 990 |
+
) {
|
| 991 |
+
//int weight_total = batch * heads * height * width;
|
| 992 |
+
int input_total = batch * heads * vec_row * vec_height;
|
| 993 |
+
int out_total = batch * heads * vec_row * width;
|
| 994 |
+
int tid = threadIdx.x;
|
| 995 |
+
int h = BLOCKWIDTH * blockIdx.x;
|
| 996 |
+
int w = BLOCKWIDTH * blockIdx.y + tid;
|
| 997 |
+
if (w >= width && tid >= height) {
|
| 998 |
+
return;
|
| 999 |
+
}
|
| 1000 |
+
|
| 1001 |
+
__shared__ float blockvec[BLOCKWIDTH];
|
| 1002 |
+
int i = width * h + w;
|
| 1003 |
+
int k;
|
| 1004 |
+
float w_tmp;
|
| 1005 |
+
|
| 1006 |
+
float weight[BLOCKWIDTH];
|
| 1007 |
+
for (int b = 0; b < batch; ++b){
|
| 1008 |
+
for (int head = 0; head < heads; ++head){
|
| 1009 |
+
int batch_shift = b * heads + head;
|
| 1010 |
+
for (k = 0; k < BLOCKWIDTH && h + k < vec_height; ++k){
|
| 1011 |
+
int k_w = k;
|
| 1012 |
+
int w_index = batch_shift * height * width + i + (k_w * width);
|
| 1013 |
+
float scale = __half2float(scales[batch_shift * width + w]);
|
| 1014 |
+
float zero = __half2float(zeros[batch_shift * width + w]);
|
| 1015 |
+
w_tmp = as_unsigned(mat[w_index]);
|
| 1016 |
+
weight[k] = scale *(w_tmp-zero);
|
| 1017 |
+
}
|
| 1018 |
+
|
| 1019 |
+
float res;
|
| 1020 |
+
for (int vr = 0; vr < vec_row; ++vr){
|
| 1021 |
+
res = 0;
|
| 1022 |
+
int vec_index = (batch_shift * vec_row + vr) * vec_height + blockIdx.x * BLOCKWIDTH + tid;
|
| 1023 |
+
if (vec_index < input_total) {
|
| 1024 |
+
blockvec[tid] = __half2float(vec[vec_index]);
|
| 1025 |
+
} else {
|
| 1026 |
+
blockvec[tid] = 0;
|
| 1027 |
+
}
|
| 1028 |
+
__syncthreads();
|
| 1029 |
+
for (k = 0; k < BLOCKWIDTH && h + k < vec_height; ++k){
|
| 1030 |
+
float temp_res = weight[k]*blockvec[k];
|
| 1031 |
+
res += temp_res;
|
| 1032 |
+
}
|
| 1033 |
+
int out_index = (batch_shift * vec_row + vr) * width + w;
|
| 1034 |
+
if (out_index < out_total) {
|
| 1035 |
+
atomicAdd(&mul[out_index], __float2half(res));
|
| 1036 |
+
}
|
| 1037 |
+
__syncthreads();
|
| 1038 |
+
}
|
| 1039 |
+
}
|
| 1040 |
+
}
|
| 1041 |
+
}
|
| 1042 |
+
|
| 1043 |
+
|
| 1044 |
+
|
| 1045 |
+
|
| 1046 |
+
void vecquant8matmul_batched_column_compression_faster_cuda(
|
| 1047 |
+
torch::Tensor vec,
|
| 1048 |
+
torch::Tensor mat,
|
| 1049 |
+
torch::Tensor mul,
|
| 1050 |
+
torch::Tensor scales,
|
| 1051 |
+
torch::Tensor zeros
|
| 1052 |
+
) {
|
| 1053 |
+
int batch = vec.size(0);
|
| 1054 |
+
int heads = vec.size(1);
|
| 1055 |
+
int vec_row = vec.size(2);
|
| 1056 |
+
int height = vec.size(3);
|
| 1057 |
+
int width = mat.size(3);
|
| 1058 |
+
|
| 1059 |
+
dim3 blocks(
|
| 1060 |
+
(height + BLOCKWIDTH - 1) / BLOCKWIDTH,
|
| 1061 |
+
(width + BLOCKWIDTH - 1) / BLOCKWIDTH
|
| 1062 |
+
);
|
| 1063 |
+
dim3 threads(BLOCKWIDTH);
|
| 1064 |
+
|
| 1065 |
+
VecQuant8BatchMatMulColumnCompressionKernel_faster<<<blocks, threads>>>(
|
| 1066 |
+
(half*) vec.data_ptr(),
|
| 1067 |
+
(uint8_t*) mat.data_ptr(),
|
| 1068 |
+
(half*) mul.data_ptr(),
|
| 1069 |
+
(half*) scales.data_ptr(),
|
| 1070 |
+
(half*) zeros.data_ptr(),
|
| 1071 |
+
batch, heads, vec_row, height, width
|
| 1072 |
+
);
|
| 1073 |
+
|
| 1074 |
+
}
|
| 1075 |
+
|
| 1076 |
+
__global__ void VecQuant8BatchMatMulColumnCompressionKernel_faster(
|
| 1077 |
+
const half* __restrict__ vec,
|
| 1078 |
+
const uint8_t* __restrict__ mat,
|
| 1079 |
+
half* __restrict__ mul,
|
| 1080 |
+
const half* __restrict__ scales,
|
| 1081 |
+
const half* __restrict__ zeros,
|
| 1082 |
+
int batch,
|
| 1083 |
+
int heads,
|
| 1084 |
+
int vec_row,
|
| 1085 |
+
int height,
|
| 1086 |
+
int width
|
| 1087 |
+
) {
|
| 1088 |
+
//int weight_total = batch * heads * height * width;
|
| 1089 |
+
int input_total = batch * heads * vec_row * height;
|
| 1090 |
+
int out_total = batch * heads * vec_row * width;
|
| 1091 |
+
int tid = threadIdx.x;
|
| 1092 |
+
int h = BLOCKWIDTH * blockIdx.x;
|
| 1093 |
+
int w = BLOCKWIDTH * blockIdx.y + tid;
|
| 1094 |
+
if (w >= width && tid >= height) {
|
| 1095 |
+
return;
|
| 1096 |
+
}
|
| 1097 |
+
|
| 1098 |
+
__shared__ float blockvec[BLOCKWIDTH];
|
| 1099 |
+
int k;
|
| 1100 |
+
float w_tmp;
|
| 1101 |
+
float weight[BLOCKWIDTH];
|
| 1102 |
+
|
| 1103 |
+
for (int b = 0; b < batch; ++b){
|
| 1104 |
+
for (int head = 0; head < heads; ++head){
|
| 1105 |
+
int batch_shift = b * heads + head;
|
| 1106 |
+
for (k = 0; k < BLOCKWIDTH; ++k){
|
| 1107 |
+
int w_index = (batch_shift * height + h + k) * width + w;
|
| 1108 |
+
float scale = __half2float(scales[batch_shift * height + h + k]);
|
| 1109 |
+
float zero = __half2float(zeros[batch_shift * height + h + k]);
|
| 1110 |
+
w_tmp = mat[w_index];
|
| 1111 |
+
weight[k] = scale * (w_tmp-zero);
|
| 1112 |
+
}
|
| 1113 |
+
|
| 1114 |
+
float res;
|
| 1115 |
+
for (int vr = 0; vr < vec_row; ++vr){
|
| 1116 |
+
res = 0;
|
| 1117 |
+
int vec_index = (batch_shift * vec_row + vr) * height + blockIdx.x * BLOCKWIDTH + tid;
|
| 1118 |
+
if (vec_index < input_total) {
|
| 1119 |
+
blockvec[tid] = __half2float(vec[vec_index]);
|
| 1120 |
+
} else {
|
| 1121 |
+
blockvec[tid] = 0;
|
| 1122 |
+
}
|
| 1123 |
+
__syncthreads();
|
| 1124 |
+
for (k = 0; k < BLOCKWIDTH; ++k){
|
| 1125 |
+
res += weight[k]*blockvec[k];
|
| 1126 |
+
}
|
| 1127 |
+
int out_index = (batch_shift * vec_row + vr) * width + w;
|
| 1128 |
+
if (out_index < out_total) {
|
| 1129 |
+
atomicAdd(&mul[out_index], __float2half(res));
|
| 1130 |
+
}
|
| 1131 |
+
__syncthreads();
|
| 1132 |
+
}
|
| 1133 |
+
}
|
| 1134 |
+
}
|
| 1135 |
+
}
|
| 1136 |
+
|
| 1137 |
+
|
| 1138 |
+
|
| 1139 |
+
void vecquant8matmul_batched_column_compression_old_cuda(
|
| 1140 |
+
torch::Tensor vec,
|
| 1141 |
+
torch::Tensor mat,
|
| 1142 |
+
torch::Tensor mul,
|
| 1143 |
+
torch::Tensor scales,
|
| 1144 |
+
torch::Tensor zeros
|
| 1145 |
+
) {
|
| 1146 |
+
int batch = vec.size(0);
|
| 1147 |
+
int heads = vec.size(1);
|
| 1148 |
+
int vec_row = vec.size(2);
|
| 1149 |
+
int height = vec.size(3);
|
| 1150 |
+
int width = mat.size(3);
|
| 1151 |
+
|
| 1152 |
+
dim3 blocks(
|
| 1153 |
+
(height + BLOCKWIDTH - 1) / BLOCKWIDTH,
|
| 1154 |
+
(width + BLOCKWIDTH - 1) / BLOCKWIDTH
|
| 1155 |
+
);
|
| 1156 |
+
dim3 threads(BLOCKWIDTH);
|
| 1157 |
+
|
| 1158 |
+
AT_DISPATCH_FLOATING_TYPES(
|
| 1159 |
+
vec.type(), "vecquant8matmul_batched_column_compression_old_cuda", ([&] {
|
| 1160 |
+
VecQuant8BatchMatMulColumnCompressionKernel_old<<<blocks, threads>>>(
|
| 1161 |
+
vec.data<scalar_t>(), mat.data<uint8_t>(), mul.data<scalar_t>(),
|
| 1162 |
+
scales.data<scalar_t>(), zeros.data<scalar_t>(),
|
| 1163 |
+
batch, heads, vec_row, height, width
|
| 1164 |
+
);
|
| 1165 |
+
})
|
| 1166 |
+
);
|
| 1167 |
+
|
| 1168 |
+
}
|
| 1169 |
+
|
| 1170 |
+
template <typename scalar_t>
|
| 1171 |
+
__global__ void VecQuant8BatchMatMulColumnCompressionKernel_old(
|
| 1172 |
+
const scalar_t* __restrict__ vec,
|
| 1173 |
+
const uint8_t* __restrict__ mat,
|
| 1174 |
+
scalar_t* __restrict__ mul,
|
| 1175 |
+
const scalar_t* __restrict__ scales,
|
| 1176 |
+
const scalar_t* __restrict__ zeros,
|
| 1177 |
+
int batch,
|
| 1178 |
+
int heads,
|
| 1179 |
+
int vec_row,
|
| 1180 |
+
int height,
|
| 1181 |
+
int width
|
| 1182 |
+
) {
|
| 1183 |
+
int weight_total = batch * heads * height * width;
|
| 1184 |
+
int input_total = batch * heads * vec_row * height;
|
| 1185 |
+
int out_total = batch * heads * vec_row * width;
|
| 1186 |
+
int tid = threadIdx.x;
|
| 1187 |
+
// h is index of height with step being BLOCKWIDTH
|
| 1188 |
+
int h = BLOCKWIDTH * blockIdx.x;
|
| 1189 |
+
// w is index of width with step being 1
|
| 1190 |
+
int w = BLOCKWIDTH * blockIdx.y + tid;
|
| 1191 |
+
if (w >= width && tid >= height) {
|
| 1192 |
+
return;
|
| 1193 |
+
}
|
| 1194 |
+
|
| 1195 |
+
__shared__ scalar_t blockvec[BLOCKWIDTH];
|
| 1196 |
+
int k;
|
| 1197 |
+
scalar_t w_tmp;
|
| 1198 |
+
|
| 1199 |
+
float weight[BLOCKWIDTH];
|
| 1200 |
+
|
| 1201 |
+
for (int b = 0; b < batch; ++b){
|
| 1202 |
+
for (int head = 0; head < heads; ++head){
|
| 1203 |
+
int batch_shift = b * heads + head;
|
| 1204 |
+
for (k = 0; k < BLOCKWIDTH && h + k < height; ++k){
|
| 1205 |
+
int w_index = (batch_shift * height + h + k) * width + w;
|
| 1206 |
+
if (w_index >= weight_total || w >= width) {
|
| 1207 |
+
weight[k] = 0;
|
| 1208 |
+
} else {
|
| 1209 |
+
scalar_t scale = scales[batch_shift * height + h + k];
|
| 1210 |
+
scalar_t zero = zeros[batch_shift * height + h + k];
|
| 1211 |
+
w_tmp = mat[w_index];
|
| 1212 |
+
weight[k] = scale * (w_tmp - zero);
|
| 1213 |
+
}
|
| 1214 |
+
}
|
| 1215 |
+
|
| 1216 |
+
scalar_t res;
|
| 1217 |
+
for (int vr = 0; vr < vec_row; ++vr){
|
| 1218 |
+
res = 0;
|
| 1219 |
+
int vec_index = (batch_shift * vec_row + vr) * height + blockIdx.x * BLOCKWIDTH + tid;
|
| 1220 |
+
if (vec_index < input_total) {
|
| 1221 |
+
blockvec[tid] = vec[vec_index];
|
| 1222 |
+
} else {
|
| 1223 |
+
blockvec[tid] = 0;
|
| 1224 |
+
}
|
| 1225 |
+
|
| 1226 |
+
__syncthreads();
|
| 1227 |
+
for (k = 0; k < BLOCKWIDTH && h + k < height; ++k){
|
| 1228 |
+
// res is the dot product of BLOCKWIDTH elements (part of width)
|
| 1229 |
+
res += weight[k] * blockvec[k];
|
| 1230 |
+
}
|
| 1231 |
+
// add res to the final result, final matrix shape: (batch, vec_row, width)
|
| 1232 |
+
int out_index = (batch_shift * vec_row + vr) * width + w;
|
| 1233 |
+
if (out_index < out_total) {
|
| 1234 |
+
atomicAdd(&mul[out_index], res);
|
| 1235 |
+
}
|
| 1236 |
+
__syncthreads();
|
| 1237 |
+
}
|
| 1238 |
+
}
|
| 1239 |
+
}
|
| 1240 |
+
}
|
| 1241 |
+
|
| 1242 |
+
|
| 1243 |
+
void vecquant4matmul_batched_old_cuda(
|
| 1244 |
+
torch::Tensor vec,
|
| 1245 |
+
torch::Tensor mat,
|
| 1246 |
+
torch::Tensor mul,
|
| 1247 |
+
torch::Tensor scales,
|
| 1248 |
+
torch::Tensor zeros
|
| 1249 |
+
) {
|
| 1250 |
+
int batch = vec.size(0);
|
| 1251 |
+
int heads = vec.size(1);
|
| 1252 |
+
int vec_row = vec.size(2);
|
| 1253 |
+
int vec_height = vec.size(3);
|
| 1254 |
+
int height = mat.size(2);
|
| 1255 |
+
int width = mat.size(3);
|
| 1256 |
+
int zero_width = zeros.size(2);
|
| 1257 |
+
|
| 1258 |
+
dim3 blocks(
|
| 1259 |
+
(height + BLOCKHEIGHT_OLD4 - 1) / BLOCKHEIGHT_OLD4,
|
| 1260 |
+
(width + BLOCKWIDTH - 1) / BLOCKWIDTH
|
| 1261 |
+
);
|
| 1262 |
+
dim3 threads(BLOCKWIDTH);
|
| 1263 |
+
|
| 1264 |
+
AT_DISPATCH_FLOATING_TYPES(
|
| 1265 |
+
vec.type(), "vecquant4matmul_batched_old_cuda", ([&] {
|
| 1266 |
+
VecQuant4BatchMatMulKernel_old<<<blocks, threads>>>(
|
| 1267 |
+
vec.data<scalar_t>(), mat.data<uint8_t>(), mul.data<scalar_t>(),
|
| 1268 |
+
scales.data<scalar_t>(), zeros.data<scalar_t>(),
|
| 1269 |
+
batch, heads, vec_row, vec_height, height, width, zero_width
|
| 1270 |
+
);
|
| 1271 |
+
})
|
| 1272 |
+
);
|
| 1273 |
+
|
| 1274 |
+
}
|
| 1275 |
+
|
| 1276 |
+
template <typename scalar_t>
|
| 1277 |
+
__global__ void VecQuant4BatchMatMulKernel_old(
|
| 1278 |
+
const scalar_t* __restrict__ vec,
|
| 1279 |
+
const uint8_t* __restrict__ mat,
|
| 1280 |
+
scalar_t* __restrict__ mul,
|
| 1281 |
+
const scalar_t* __restrict__ scales,
|
| 1282 |
+
const scalar_t* __restrict__ zeros,
|
| 1283 |
+
int batch,
|
| 1284 |
+
int heads,
|
| 1285 |
+
int vec_row,
|
| 1286 |
+
int vec_height,
|
| 1287 |
+
int height,
|
| 1288 |
+
int width,
|
| 1289 |
+
int zero_width
|
| 1290 |
+
) {
|
| 1291 |
+
int weight_total = batch * heads * height * width;
|
| 1292 |
+
int input_total = batch * heads * vec_row * vec_height;
|
| 1293 |
+
int out_total = batch * heads * vec_row * width;
|
| 1294 |
+
int tid = threadIdx.x;
|
| 1295 |
+
// h is index of height with step being BLOCKHEIGHT_OLD4
|
| 1296 |
+
int h = BLOCKHEIGHT_OLD4 * blockIdx.x;
|
| 1297 |
+
// w is index of width with step being 1
|
| 1298 |
+
int w = BLOCKWIDTH * blockIdx.y + tid;
|
| 1299 |
+
if (w >= width && tid >= vec_height) {
|
| 1300 |
+
return;
|
| 1301 |
+
}
|
| 1302 |
+
|
| 1303 |
+
__shared__ scalar_t blockvec[BLOCKWIDTH];
|
| 1304 |
+
// i is index of mat of block first row
|
| 1305 |
+
int i = width * h + w;
|
| 1306 |
+
int k;
|
| 1307 |
+
scalar_t w_tmp;
|
| 1308 |
+
|
| 1309 |
+
float weight[BLOCKWIDTH];
|
| 1310 |
+
for (int b = 0; b < batch; ++b){
|
| 1311 |
+
for (int head = 0; head < heads; ++head){
|
| 1312 |
+
int batch_shift = b * heads + head;
|
| 1313 |
+
for (k = 0; k < BLOCKWIDTH && h*2 + k < vec_height; ++k){
|
| 1314 |
+
int k_w = (k / 2);
|
| 1315 |
+
int k_bit = (k % 2) * 4;
|
| 1316 |
+
int w_index = batch_shift * height * width + i + (k_w * width);
|
| 1317 |
+
if (w_index >= weight_total || w >= width) {
|
| 1318 |
+
weight[k] = 0;
|
| 1319 |
+
} else {
|
| 1320 |
+
scalar_t scale = scales[batch_shift * width + w];
|
| 1321 |
+
scalar_t zero = zeros[batch_shift * width + w];
|
| 1322 |
+
w_tmp = ((as_unsigned(mat[w_index]) >> k_bit) & 0xF);
|
| 1323 |
+
weight[k] = scale * (w_tmp - zero);
|
| 1324 |
+
}
|
| 1325 |
+
}
|
| 1326 |
+
|
| 1327 |
+
scalar_t res;
|
| 1328 |
+
for (int vr = 0; vr < vec_row; ++vr){
|
| 1329 |
+
res = 0;
|
| 1330 |
+
int vec_index = (batch_shift * vec_row + vr) * vec_height + blockIdx.x * BLOCKWIDTH + tid;
|
| 1331 |
+
if (vec_index < input_total) {
|
| 1332 |
+
blockvec[tid] = vec[vec_index];
|
| 1333 |
+
} else {
|
| 1334 |
+
blockvec[tid] = 0;
|
| 1335 |
+
}
|
| 1336 |
+
|
| 1337 |
+
__syncthreads();
|
| 1338 |
+
for (k = 0; k < BLOCKWIDTH && h*2 + k < vec_height; ++k){
|
| 1339 |
+
// res is the dot product of BLOCKWIDTH elements (part of width)
|
| 1340 |
+
res += weight[k] * blockvec[k];
|
| 1341 |
+
}
|
| 1342 |
+
// add res to the final result, final matrix shape: (batch, vec_row, width)
|
| 1343 |
+
int out_index = (batch_shift * vec_row + vr) * width + w;
|
| 1344 |
+
if (out_index < out_total) {
|
| 1345 |
+
atomicAdd(&mul[out_index], res);
|
| 1346 |
+
}
|
| 1347 |
+
__syncthreads();
|
| 1348 |
+
}
|
| 1349 |
+
}
|
| 1350 |
+
}
|
| 1351 |
+
}
|
| 1352 |
+
|
| 1353 |
+
|
| 1354 |
+
|
| 1355 |
+
|
| 1356 |
+
|
| 1357 |
+
void vecquant4matmul_batched_column_compression_old_cuda(
|
| 1358 |
+
torch::Tensor vec,
|
| 1359 |
+
torch::Tensor mat,
|
| 1360 |
+
torch::Tensor mul,
|
| 1361 |
+
torch::Tensor scales,
|
| 1362 |
+
torch::Tensor zeros
|
| 1363 |
+
) {
|
| 1364 |
+
int batch = vec.size(0);
|
| 1365 |
+
int heads = vec.size(1);
|
| 1366 |
+
int vec_row = vec.size(2);
|
| 1367 |
+
int height = vec.size(3);
|
| 1368 |
+
int width = mat.size(3);
|
| 1369 |
+
|
| 1370 |
+
dim3 blocks(
|
| 1371 |
+
(height + BLOCKHEIGHT_OLD4 - 1) / BLOCKHEIGHT_OLD4,
|
| 1372 |
+
(width + BLOCKWIDTH - 1) / BLOCKWIDTH
|
| 1373 |
+
);
|
| 1374 |
+
dim3 threads(BLOCKWIDTH);
|
| 1375 |
+
|
| 1376 |
+
AT_DISPATCH_FLOATING_TYPES(
|
| 1377 |
+
vec.type(), "vecquant4matmul_batched_column_compression_old_cuda", ([&] {
|
| 1378 |
+
VecQuant4BatchMatMulColumnCompressionKernel_old<<<blocks, threads>>>(
|
| 1379 |
+
vec.data<scalar_t>(), mat.data<uint8_t>(), mul.data<scalar_t>(),
|
| 1380 |
+
scales.data<scalar_t>(), zeros.data<scalar_t>(),
|
| 1381 |
+
batch, heads, vec_row, height, width
|
| 1382 |
+
);
|
| 1383 |
+
})
|
| 1384 |
+
);
|
| 1385 |
+
|
| 1386 |
+
}
|
| 1387 |
+
|
| 1388 |
+
template <typename scalar_t>
|
| 1389 |
+
__global__ void VecQuant4BatchMatMulColumnCompressionKernel_old(
|
| 1390 |
+
const scalar_t* __restrict__ vec,
|
| 1391 |
+
const uint8_t* __restrict__ mat,
|
| 1392 |
+
scalar_t* __restrict__ mul,
|
| 1393 |
+
const scalar_t* __restrict__ scales,
|
| 1394 |
+
const scalar_t* __restrict__ zeros,
|
| 1395 |
+
int batch,
|
| 1396 |
+
int heads,
|
| 1397 |
+
int vec_row,
|
| 1398 |
+
int height,
|
| 1399 |
+
int width
|
| 1400 |
+
) {
|
| 1401 |
+
int weight_total = batch * heads * height * width;
|
| 1402 |
+
int input_total = batch * heads * vec_row * height;
|
| 1403 |
+
int out_total = batch * heads * vec_row * width;
|
| 1404 |
+
int tid = threadIdx.x;
|
| 1405 |
+
// h is index of height with step being BLOCKWIDTH
|
| 1406 |
+
int h = BLOCKHEIGHT_OLD4 * blockIdx.x;
|
| 1407 |
+
// w is index of width with step being 1
|
| 1408 |
+
int w = BLOCKWIDTH * blockIdx.y + tid;
|
| 1409 |
+
if (w >= width && tid >= height) {
|
| 1410 |
+
return;
|
| 1411 |
+
}
|
| 1412 |
+
|
| 1413 |
+
__shared__ scalar_t blockvec[BLOCKWIDTH];
|
| 1414 |
+
int k;
|
| 1415 |
+
scalar_t w_tmp;
|
| 1416 |
+
|
| 1417 |
+
float weight[BLOCKWIDTH];
|
| 1418 |
+
|
| 1419 |
+
for (int b = 0; b < batch; ++b){
|
| 1420 |
+
for (int head = 0; head < heads; ++head){
|
| 1421 |
+
int batch_shift = b * heads + head;
|
| 1422 |
+
for (k = 0; k < BLOCKWIDTH && h*2 + k < height; ++k){
|
| 1423 |
+
int k_w = (k / 2);
|
| 1424 |
+
int k_bit = (k % 2) * 4;
|
| 1425 |
+
int w_index = (batch_shift * height + h + k) * width + k_w;
|
| 1426 |
+
if (w_index >= weight_total || w >= width) {
|
| 1427 |
+
weight[k] = 0;
|
| 1428 |
+
} else {
|
| 1429 |
+
scalar_t scale = scales[batch_shift * height + h + k];
|
| 1430 |
+
scalar_t zero = zeros[batch_shift * height + h + k];
|
| 1431 |
+
w_tmp = ((as_unsigned(mat[w_index]) >> k_bit) & 0xF);
|
| 1432 |
+
weight[k] = scale * (w_tmp - zero);
|
| 1433 |
+
}
|
| 1434 |
+
}
|
| 1435 |
+
|
| 1436 |
+
scalar_t res;
|
| 1437 |
+
for (int vr = 0; vr < vec_row; ++vr){
|
| 1438 |
+
res = 0;
|
| 1439 |
+
int vec_index = (batch_shift * vec_row + vr) * height + blockIdx.x * BLOCKWIDTH + tid;
|
| 1440 |
+
if (vec_index < input_total) {
|
| 1441 |
+
blockvec[tid] = vec[vec_index];
|
| 1442 |
+
} else {
|
| 1443 |
+
blockvec[tid] = 0;
|
| 1444 |
+
}
|
| 1445 |
+
|
| 1446 |
+
__syncthreads();
|
| 1447 |
+
for (k = 0; k < BLOCKWIDTH && h*2 + k < height; ++k){
|
| 1448 |
+
// res is the dot product of BLOCKWIDTH elements (part of width)
|
| 1449 |
+
res += weight[k] * blockvec[k];
|
| 1450 |
+
}
|
| 1451 |
+
// add res to the final result, final matrix shape: (batch, vec_row, width)
|
| 1452 |
+
int out_index = (batch_shift * vec_row + vr) * width + w;
|
| 1453 |
+
if (out_index < out_total) {
|
| 1454 |
+
atomicAdd(&mul[out_index], res);
|
| 1455 |
+
}
|
| 1456 |
+
__syncthreads();
|
| 1457 |
+
}
|
| 1458 |
+
}
|
| 1459 |
+
}
|
| 1460 |
+
}
|
| 1461 |
+
|
| 1462 |
+
|
| 1463 |
+
|
| 1464 |
+
|
| 1465 |
+
|
| 1466 |
+
void vecquant8matmul_batched_faster_old_cuda(
|
| 1467 |
+
torch::Tensor vec,
|
| 1468 |
+
torch::Tensor mat,
|
| 1469 |
+
torch::Tensor mul,
|
| 1470 |
+
torch::Tensor scales,
|
| 1471 |
+
torch::Tensor zeros
|
| 1472 |
+
) {
|
| 1473 |
+
int batch = vec.size(0);
|
| 1474 |
+
int heads = vec.size(1);
|
| 1475 |
+
int vec_row = vec.size(2);
|
| 1476 |
+
int vec_height = vec.size(3);
|
| 1477 |
+
int height = mat.size(2);
|
| 1478 |
+
int width = mat.size(3);
|
| 1479 |
+
|
| 1480 |
+
dim3 blocks(
|
| 1481 |
+
(height + BLOCKWIDTH - 1) / BLOCKWIDTH,
|
| 1482 |
+
(width + BLOCKWIDTH - 1) / BLOCKWIDTH
|
| 1483 |
+
);
|
| 1484 |
+
dim3 threads(BLOCKWIDTH);
|
| 1485 |
+
|
| 1486 |
+
VecQuant8BatchMatMulKernel_faster_old<<<blocks, threads>>>(
|
| 1487 |
+
(half*) vec.data_ptr(),
|
| 1488 |
+
(uint8_t*) mat.data_ptr(),
|
| 1489 |
+
(half*) mul.data_ptr(),
|
| 1490 |
+
(half*) scales.data_ptr(),
|
| 1491 |
+
(half*) zeros.data_ptr(),
|
| 1492 |
+
batch, heads, vec_row, vec_height, height, width
|
| 1493 |
+
);
|
| 1494 |
+
}
|
| 1495 |
+
|
| 1496 |
+
|
| 1497 |
+
__global__ void VecQuant8BatchMatMulKernel_faster_old(
|
| 1498 |
+
const half* __restrict__ vec,
|
| 1499 |
+
const uint8_t* __restrict__ mat,
|
| 1500 |
+
half* __restrict__ mul,
|
| 1501 |
+
const half* __restrict__ scales,
|
| 1502 |
+
const half* __restrict__ zeros,
|
| 1503 |
+
int batch,
|
| 1504 |
+
int heads,
|
| 1505 |
+
int vec_row,
|
| 1506 |
+
int vec_height,
|
| 1507 |
+
int height,
|
| 1508 |
+
int width
|
| 1509 |
+
) {
|
| 1510 |
+
int weight_total = batch * heads * height * width;
|
| 1511 |
+
int input_total = batch * heads * vec_row * vec_height;
|
| 1512 |
+
int out_total = batch * heads * vec_row * width;
|
| 1513 |
+
int tid = threadIdx.x;
|
| 1514 |
+
const int BLOCKWIDTH_half = BLOCKWIDTH/2;
|
| 1515 |
+
|
| 1516 |
+
int h = BLOCKWIDTH * blockIdx.x; //head_dim, dim=-1
|
| 1517 |
+
int w = BLOCKWIDTH * blockIdx.y + tid; //seq-len, +0-256 ,dim=-2
|
| 1518 |
+
/*
|
| 1519 |
+
if (w >= width && tid >= vec_height) {
|
| 1520 |
+
return;
|
| 1521 |
+
}
|
| 1522 |
+
*/
|
| 1523 |
+
__shared__ half blockvec[BLOCKWIDTH]; //256
|
| 1524 |
+
int i = width * h + w;
|
| 1525 |
+
int k;
|
| 1526 |
+
|
| 1527 |
+
half w_tmp1 = __float2half(0);
|
| 1528 |
+
half w_tmp2 = __float2half(0);
|
| 1529 |
+
|
| 1530 |
+
half2 weight[BLOCKWIDTH_half];
|
| 1531 |
+
for (int b = 0; b < batch; ++b){
|
| 1532 |
+
for (int head = 0; head < heads; ++head){
|
| 1533 |
+
int batch_shift = b * heads + head;
|
| 1534 |
+
//int zero_index = batch_shift;
|
| 1535 |
+
for (k = 0; k < BLOCKWIDTH_half; ++k){
|
| 1536 |
+
int w_index1 = batch_shift * height * width + i + (2 * k * width); // [batch,head,h+k, w]
|
| 1537 |
+
int w_index2 = batch_shift * height * width + i + ((2 * k + 1) * width);
|
| 1538 |
+
int zero_index = batch_shift * width + w; // [batch,head, w]
|
| 1539 |
+
if (w_index1 >= weight_total || w >= width || (2 * k + h) >= height) {
|
| 1540 |
+
weight[k] = __float2half2_rn(0);
|
| 1541 |
+
} else {
|
| 1542 |
+
float zero_f=__half2float(zeros[zero_index]);
|
| 1543 |
+
float scale_f= __half2float(scales[zero_index]);
|
| 1544 |
+
if (w_index2 >= weight_total){
|
| 1545 |
+
w_tmp1 = __float2half((as_unsigned(mat[w_index1]) -zero_f)*scale_f);
|
| 1546 |
+
w_tmp2 = __float2half(0);
|
| 1547 |
+
weight[k] = __halves2half2(w_tmp1,w_tmp2);
|
| 1548 |
+
//printf("zero_index is %d w is %d height is %d width is %d w_index1 is %d w_tmp1 is %f w_tmp2 is %f zero is %f scale is %f low is %f high is %f \n ",zero_index,w,height, width,w_index1,__half2float(w_tmp1),__half2float(w_tmp2),zero_f,scale_f,__low2float(weight[k]),__high2float(weight[k]));
|
| 1549 |
+
}else{
|
| 1550 |
+
w_tmp1 = __int2half_rn(as_unsigned(mat[w_index1]));
|
| 1551 |
+
w_tmp2 = __int2half_rn(as_unsigned(mat[w_index2]));
|
| 1552 |
+
|
| 1553 |
+
//weight[k] = __hmul2(__hsub2(__halves2half2(w_tmp1,w_tmp2), __halves2half2(zero,zero)),__halves2half2(scale,scale));
|
| 1554 |
+
weight[k] = __hfma2(__halves2half2(w_tmp1,w_tmp2), __float2half2_rn(scale_f), __float2half2_rn(-(scale_f * zero_f)));
|
| 1555 |
+
//printf("zero_index1 is %d zero_index2 is %d k is %d head is %d w is %d h is %d height is %d width is %d w_index1 is %d w_index2 is %d zero is %f scale is %f low is %f high is %f \n ",zero_index1,zero_index2,k,head,w,h,height, width,w_index1,w_index2,__half2float(zero1),__half2float(scale1),__low2float(weight[k]),__high2float(weight[k]));
|
| 1556 |
+
}
|
| 1557 |
+
}
|
| 1558 |
+
}
|
| 1559 |
+
|
| 1560 |
+
|
| 1561 |
+
for (int vr = 0; vr < vec_row; ++vr){
|
| 1562 |
+
float res=0;
|
| 1563 |
+
int vec_index = (batch_shift * vec_row + vr) * height + blockIdx.x * BLOCKWIDTH + tid;
|
| 1564 |
+
int out_index = (batch_shift * vec_row + vr) * width + w;
|
| 1565 |
+
if (vec_index < input_total) {
|
| 1566 |
+
//blockvec[tid] = __half2float(vec[vec_index]);// [batch, head, vr, tid(seq_len dim+)]
|
| 1567 |
+
blockvec[tid] = vec[vec_index];
|
| 1568 |
+
//printf("width is %d height is %d h is %d w is %d vec_index is %d out_index is %d vec_row is %d vec_height is %d,vr is %d tid is %d blockvec is %f\n",width,height, h,w,vec_index,out_index,vec_row,vec_height,vr,tid,blockvec[tid]);
|
| 1569 |
+
} else {
|
| 1570 |
+
blockvec[tid] = __float2half(0);
|
| 1571 |
+
}
|
| 1572 |
+
__syncthreads();
|
| 1573 |
+
if (out_index < out_total) {
|
| 1574 |
+
for (k = 0; k < BLOCKWIDTH_half; ++k){
|
| 1575 |
+
half2 res2 = __hmul2(weight[k],__halves2half2(blockvec[2*k],blockvec[2*k+1]));
|
| 1576 |
+
res += __low2float(res2) + __high2float(res2);
|
| 1577 |
+
}
|
| 1578 |
+
atomicAdd(&mul[out_index], __float2half(res));
|
| 1579 |
+
}
|
| 1580 |
+
__syncthreads();
|
| 1581 |
+
}
|
| 1582 |
+
}
|
| 1583 |
+
}
|
| 1584 |
+
}
|
| 1585 |
+
|
| 1586 |
+
|
| 1587 |
+
void vecquant8matmul_batched_column_compression_faster_old_cuda(
|
| 1588 |
+
torch::Tensor vec, // [batch,heads, seq_q, seq_v]
|
| 1589 |
+
torch::Tensor mat, // [batch,heads, seq_v, head_dim]
|
| 1590 |
+
torch::Tensor mul, // [batch,heads, seq_q,head_dim]
|
| 1591 |
+
torch::Tensor scales, // [batch,heads, head_dim]
|
| 1592 |
+
torch::Tensor zeros
|
| 1593 |
+
) {
|
| 1594 |
+
int batch = vec.size(0);
|
| 1595 |
+
int heads = vec.size(1);
|
| 1596 |
+
int vec_row = vec.size(2); //ql
|
| 1597 |
+
int height = mat.size(2); //vl
|
| 1598 |
+
int width = mat.size(3); //head_dim
|
| 1599 |
+
|
| 1600 |
+
dim3 blocks(
|
| 1601 |
+
(height + BLOCKWIDTH - 1) / BLOCKWIDTH,
|
| 1602 |
+
(width + BLOCKWIDTH - 1) / BLOCKWIDTH
|
| 1603 |
+
);
|
| 1604 |
+
dim3 threads(BLOCKWIDTH);
|
| 1605 |
+
|
| 1606 |
+
VecQuant8BatchMatMulColumnCompressionKernel_faster_old<<<blocks, threads>>>(
|
| 1607 |
+
(half*) vec.data_ptr(),
|
| 1608 |
+
(uint8_t*) mat.data_ptr(),
|
| 1609 |
+
(half*) mul.data_ptr(),
|
| 1610 |
+
(half*) scales.data_ptr(),
|
| 1611 |
+
(half*) zeros.data_ptr(),
|
| 1612 |
+
batch, heads, vec_row, height, width
|
| 1613 |
+
);
|
| 1614 |
+
|
| 1615 |
+
}
|
| 1616 |
+
|
| 1617 |
+
|
| 1618 |
+
__global__ void VecQuant8BatchMatMulColumnCompressionKernel_faster_old(
|
| 1619 |
+
const half* __restrict__ vec, // [batch,heads, seq_q, seq_v]
|
| 1620 |
+
const uint8_t* __restrict__ mat, // [batch,heads, seq_v, head_dim]
|
| 1621 |
+
half* __restrict__ mul, // [batch,heads, seq_q,head_dim]
|
| 1622 |
+
const half* __restrict__ scales, // [batch,heads, seq_v]
|
| 1623 |
+
const half* __restrict__ zeros,
|
| 1624 |
+
int batch,
|
| 1625 |
+
int heads,
|
| 1626 |
+
int vec_row, //seq_q
|
| 1627 |
+
int height, //seq_v
|
| 1628 |
+
int width //head_dim
|
| 1629 |
+
) {
|
| 1630 |
+
int weight_total = batch * heads * height * width;
|
| 1631 |
+
int input_total = batch * heads * vec_row * height;
|
| 1632 |
+
int out_total = batch * heads * vec_row * width;
|
| 1633 |
+
int tid = threadIdx.x;
|
| 1634 |
+
int h = BLOCKWIDTH * blockIdx.x; // vl
|
| 1635 |
+
int w = BLOCKWIDTH * blockIdx.y + tid; //head_dim + block
|
| 1636 |
+
if (w >= width && tid >= height) {
|
| 1637 |
+
return;
|
| 1638 |
+
}
|
| 1639 |
+
__shared__ half blockvec[BLOCKWIDTH];
|
| 1640 |
+
int k;
|
| 1641 |
+
half w_tmp1 = __float2half(0);
|
| 1642 |
+
half w_tmp2 = __float2half(0);
|
| 1643 |
+
int i = width * h + w;
|
| 1644 |
+
const int BLOCKWIDTH_half = BLOCKWIDTH/2;
|
| 1645 |
+
half2 weight[BLOCKWIDTH_half];
|
| 1646 |
+
|
| 1647 |
+
for (int b = 0; b < batch; ++b){
|
| 1648 |
+
for (int head = 0; head < heads; ++head){
|
| 1649 |
+
int batch_shift = b * heads + head;
|
| 1650 |
+
//int zero_index = batch_shift;
|
| 1651 |
+
for (k = 0; k < BLOCKWIDTH_half; ++k){
|
| 1652 |
+
int w_index1 = batch_shift * height * width + i + (2 * k) * width; // [batch,head, h+k, w]
|
| 1653 |
+
int w_index2 = batch_shift * height * width + i + ((2 * k + 1) * width);
|
| 1654 |
+
int zero_index1 = batch_shift * height + h + 2*k; // [batch,head, w]
|
| 1655 |
+
int zero_index2 = batch_shift * height + h + 2*k+1; // [batch,head, w]
|
| 1656 |
+
|
| 1657 |
+
if (w_index1 >= weight_total || (2 * k + h)>=height) {
|
| 1658 |
+
weight[k]=__float2half2_rn(0);
|
| 1659 |
+
} else{
|
| 1660 |
+
//int zero_index = batch_shift + h; // [batch,head, w]
|
| 1661 |
+
//float scale_f1 = __half2float(scales[zero_index1]);
|
| 1662 |
+
//float zero_f1 = __half2float(zeros[zero_index1]);
|
| 1663 |
+
if (w_index2>=weight_total){
|
| 1664 |
+
w_tmp1 = __float2half((as_unsigned(mat[w_index1]) - __half2float(zeros[zero_index1]))* __half2float(scales[zero_index1]));
|
| 1665 |
+
w_tmp2 = __float2half(0);
|
| 1666 |
+
weight[k] = __halves2half2(w_tmp1,w_tmp2);
|
| 1667 |
+
//printf("zero_index is %d k is %d w is %d head is %d height is %d width is %d w_index1 is %d w_tmp1 is %f w_tmp2 is %f zero is %f scale is %f low is %f high is %f \n ",zero_index,k,w,head,height, width,w_index1,__half2float(w_tmp1),__half2float(w_tmp2),zero_f,scale_f,__low2float(weight[k]),__high2float(weight[k]));
|
| 1668 |
+
}else{
|
| 1669 |
+
w_tmp1 = __int2half_rn(as_unsigned(mat[w_index1]));
|
| 1670 |
+
w_tmp2 = __int2half_rn(as_unsigned(mat[w_index2]));
|
| 1671 |
+
half zero1=zeros[zero_index1];
|
| 1672 |
+
half zero2=zeros[zero_index2];
|
| 1673 |
+
half scale1=scales[zero_index1];
|
| 1674 |
+
half scale2=scales[zero_index2];
|
| 1675 |
+
weight[k] = __hmul2(__hsub2(__halves2half2(w_tmp1,w_tmp2), __halves2half2(zero1,zero2)),__halves2half2(scale1,scale2));
|
| 1676 |
+
//weight[k] = __hfma2(__halves2half2(w_tmp1,w_tmp2), __float2half2_rn(scale_f), __float2half2_rn(-(scale_f * zero_f)));
|
| 1677 |
+
//printf("zero_index1 is %d zero_index2 is %d k is %d head is %d w is %d h is %d height is %d width is %d w_index1 is %d w_index2 is %d zero is %f scale is %f low is %f high is %f \n ",zero_index1,zero_index2,k,head,w,h,height, width,w_index1,w_index2,__half2float(zero1),__half2float(scale1),__low2float(weight[k]),__high2float(weight[k]));
|
| 1678 |
+
}
|
| 1679 |
+
}
|
| 1680 |
+
}
|
| 1681 |
+
|
| 1682 |
+
|
| 1683 |
+
for (int vr = 0; vr < vec_row; ++vr){
|
| 1684 |
+
float res=0;
|
| 1685 |
+
int vec_index = (batch_shift * vec_row + vr) * height + blockIdx.x * BLOCKWIDTH + tid;
|
| 1686 |
+
int out_index = (batch_shift * vec_row + vr) * width + w;
|
| 1687 |
+
|
| 1688 |
+
if (vec_index < input_total) {
|
| 1689 |
+
//blockvec[tid] = __half2float(vec[vec_index]);
|
| 1690 |
+
blockvec[tid] = vec[vec_index];
|
| 1691 |
+
//printf("vec_index is %d out_index is %d vec_row is %d ,vr is %d tid is %d blockvec is %f\n",vec_index,out_index,vec_row,vr,tid,blockvec[tid]);
|
| 1692 |
+
} else {
|
| 1693 |
+
blockvec[tid] = __float2half(0);
|
| 1694 |
+
//blockvec[tid] = 0;
|
| 1695 |
+
}
|
| 1696 |
+
__syncthreads();
|
| 1697 |
+
if (out_index < out_total) {
|
| 1698 |
+
for (k = 0; k < BLOCKWIDTH_half; ++k){
|
| 1699 |
+
half2 res2 = __hmul2(weight[k],__halves2half2(blockvec[2*k],blockvec[2*k+1]));
|
| 1700 |
+
res += __low2float(res2) + __high2float(res2);
|
| 1701 |
+
}
|
| 1702 |
+
atomicAdd(&mul[out_index], __float2half(res));
|
| 1703 |
+
}
|
| 1704 |
+
__syncthreads();
|
| 1705 |
+
}
|
| 1706 |
+
}
|
| 1707 |
+
}
|
| 1708 |
+
}
|
config.json
ADDED
|
@@ -0,0 +1,49 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"QWenLMHeadModel"
|
| 4 |
+
],
|
| 5 |
+
"auto_map": {
|
| 6 |
+
"AutoConfig": "configuration_qwen.QWenConfig",
|
| 7 |
+
"AutoModelForCausalLM": "modeling_qwen.QWenLMHeadModel"
|
| 8 |
+
},
|
| 9 |
+
"attn_dropout_prob": 0.0,
|
| 10 |
+
"bf16": false,
|
| 11 |
+
"emb_dropout_prob": 0.0,
|
| 12 |
+
"fp16": true,
|
| 13 |
+
"fp32": false,
|
| 14 |
+
"hidden_size": 4096,
|
| 15 |
+
"intermediate_size": 22016,
|
| 16 |
+
"initializer_range": 0.02,
|
| 17 |
+
"kv_channels": 128,
|
| 18 |
+
"layer_norm_epsilon": 1e-06,
|
| 19 |
+
"max_position_embeddings": 8192,
|
| 20 |
+
"model_type": "qwen",
|
| 21 |
+
"no_bias": true,
|
| 22 |
+
"num_attention_heads": 32,
|
| 23 |
+
"num_hidden_layers": 32,
|
| 24 |
+
"onnx_safe": null,
|
| 25 |
+
"quantization_config": {
|
| 26 |
+
"bits": 8,
|
| 27 |
+
"group_size": 128,
|
| 28 |
+
"damp_percent": 0.01,
|
| 29 |
+
"desc_act": false,
|
| 30 |
+
"static_groups": false,
|
| 31 |
+
"sym": true,
|
| 32 |
+
"true_sequential": true,
|
| 33 |
+
"model_name_or_path": null,
|
| 34 |
+
"model_file_base_name": "model",
|
| 35 |
+
"quant_method": "gptq"
|
| 36 |
+
},
|
| 37 |
+
"rotary_emb_base": 10000,
|
| 38 |
+
"rotary_pct": 1.0,
|
| 39 |
+
"scale_attn_weights": true,
|
| 40 |
+
"seq_length": 8192,
|
| 41 |
+
"tie_word_embeddings": false,
|
| 42 |
+
"tokenizer_class": "QWenTokenizer",
|
| 43 |
+
"transformers_version": "4.32.0",
|
| 44 |
+
"use_cache": true,
|
| 45 |
+
"use_dynamic_ntk": true,
|
| 46 |
+
"use_flash_attn": "auto",
|
| 47 |
+
"use_logn_attn": true,
|
| 48 |
+
"vocab_size": 151936
|
| 49 |
+
}
|
configuration_qwen.py
ADDED
|
@@ -0,0 +1,71 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Alibaba Cloud.
|
| 2 |
+
#
|
| 3 |
+
# This source code is licensed under the license found in the
|
| 4 |
+
# LICENSE file in the root directory of this source tree.
|
| 5 |
+
|
| 6 |
+
from transformers import PretrainedConfig
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class QWenConfig(PretrainedConfig):
|
| 10 |
+
model_type = "qwen"
|
| 11 |
+
keys_to_ignore_at_inference = ["past_key_values"]
|
| 12 |
+
|
| 13 |
+
def __init__(
|
| 14 |
+
self,
|
| 15 |
+
vocab_size=151936,
|
| 16 |
+
hidden_size=4096,
|
| 17 |
+
num_hidden_layers=32,
|
| 18 |
+
num_attention_heads=32,
|
| 19 |
+
emb_dropout_prob=0.0,
|
| 20 |
+
attn_dropout_prob=0.0,
|
| 21 |
+
layer_norm_epsilon=1e-6,
|
| 22 |
+
initializer_range=0.02,
|
| 23 |
+
max_position_embeddings=8192,
|
| 24 |
+
scale_attn_weights=True,
|
| 25 |
+
use_cache=True,
|
| 26 |
+
bf16=False,
|
| 27 |
+
fp16=False,
|
| 28 |
+
fp32=False,
|
| 29 |
+
kv_channels=128,
|
| 30 |
+
rotary_pct=1.0,
|
| 31 |
+
rotary_emb_base=10000,
|
| 32 |
+
use_dynamic_ntk=True,
|
| 33 |
+
use_logn_attn=True,
|
| 34 |
+
use_flash_attn="auto",
|
| 35 |
+
intermediate_size=22016,
|
| 36 |
+
no_bias=True,
|
| 37 |
+
tie_word_embeddings=False,
|
| 38 |
+
use_cache_quantization=False,
|
| 39 |
+
use_cache_kernel=False,
|
| 40 |
+
softmax_in_fp32=False,
|
| 41 |
+
**kwargs,
|
| 42 |
+
):
|
| 43 |
+
self.vocab_size = vocab_size
|
| 44 |
+
self.hidden_size = hidden_size
|
| 45 |
+
self.intermediate_size = intermediate_size
|
| 46 |
+
self.num_hidden_layers = num_hidden_layers
|
| 47 |
+
self.num_attention_heads = num_attention_heads
|
| 48 |
+
self.emb_dropout_prob = emb_dropout_prob
|
| 49 |
+
self.attn_dropout_prob = attn_dropout_prob
|
| 50 |
+
self.layer_norm_epsilon = layer_norm_epsilon
|
| 51 |
+
self.initializer_range = initializer_range
|
| 52 |
+
self.scale_attn_weights = scale_attn_weights
|
| 53 |
+
self.use_cache = use_cache
|
| 54 |
+
self.max_position_embeddings = max_position_embeddings
|
| 55 |
+
self.bf16 = bf16
|
| 56 |
+
self.fp16 = fp16
|
| 57 |
+
self.fp32 = fp32
|
| 58 |
+
self.kv_channels = kv_channels
|
| 59 |
+
self.rotary_pct = rotary_pct
|
| 60 |
+
self.rotary_emb_base = rotary_emb_base
|
| 61 |
+
self.use_dynamic_ntk = use_dynamic_ntk
|
| 62 |
+
self.use_logn_attn = use_logn_attn
|
| 63 |
+
self.use_flash_attn = use_flash_attn
|
| 64 |
+
self.no_bias = no_bias
|
| 65 |
+
self.use_cache_quantization = use_cache_quantization
|
| 66 |
+
self.use_cache_kernel = use_cache_kernel
|
| 67 |
+
self.softmax_in_fp32 = softmax_in_fp32
|
| 68 |
+
super().__init__(
|
| 69 |
+
tie_word_embeddings=tie_word_embeddings,
|
| 70 |
+
**kwargs
|
| 71 |
+
)
|
cpp_kernels.py
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from torch.utils import cpp_extension
|
| 2 |
+
import pathlib
|
| 3 |
+
import os
|
| 4 |
+
import subprocess
|
| 5 |
+
|
| 6 |
+
def _get_cuda_bare_metal_version(cuda_dir):
|
| 7 |
+
raw_output = subprocess.check_output([cuda_dir + "/bin/nvcc", "-V"],
|
| 8 |
+
universal_newlines=True)
|
| 9 |
+
output = raw_output.split()
|
| 10 |
+
release_idx = output.index("release") + 1
|
| 11 |
+
release = output[release_idx].split(".")
|
| 12 |
+
bare_metal_major = release[0]
|
| 13 |
+
bare_metal_minor = release[1][0]
|
| 14 |
+
|
| 15 |
+
return raw_output, bare_metal_major, bare_metal_minor
|
| 16 |
+
|
| 17 |
+
def _create_build_dir(buildpath):
|
| 18 |
+
try:
|
| 19 |
+
os.mkdir(buildpath)
|
| 20 |
+
except OSError:
|
| 21 |
+
if not os.path.isdir(buildpath):
|
| 22 |
+
print(f"Creation of the build directory {buildpath} failed")
|
| 23 |
+
|
| 24 |
+
# Check if cuda 11 is installed for compute capability 8.0
|
| 25 |
+
cc_flag = []
|
| 26 |
+
_, bare_metal_major, bare_metal_minor = _get_cuda_bare_metal_version(cpp_extension.CUDA_HOME)
|
| 27 |
+
if int(bare_metal_major) >= 11:
|
| 28 |
+
cc_flag.append('-gencode')
|
| 29 |
+
cc_flag.append('arch=compute_80,code=sm_80')
|
| 30 |
+
if int(bare_metal_minor) >= 7:
|
| 31 |
+
cc_flag.append('-gencode')
|
| 32 |
+
cc_flag.append('arch=compute_90,code=sm_90')
|
| 33 |
+
|
| 34 |
+
# Build path
|
| 35 |
+
srcpath = pathlib.Path(__file__).parent.absolute()
|
| 36 |
+
buildpath = srcpath / 'build'
|
| 37 |
+
_create_build_dir(buildpath)
|
| 38 |
+
|
| 39 |
+
def _cpp_extention_load_helper(name, sources, extra_cuda_flags):
|
| 40 |
+
return cpp_extension.load(
|
| 41 |
+
name=name,
|
| 42 |
+
sources=sources,
|
| 43 |
+
build_directory=buildpath,
|
| 44 |
+
extra_cflags=['-O3', ],
|
| 45 |
+
extra_cuda_cflags=['-O3',
|
| 46 |
+
'-gencode', 'arch=compute_70,code=sm_70',
|
| 47 |
+
'--use_fast_math'] + extra_cuda_flags + cc_flag,
|
| 48 |
+
verbose=1
|
| 49 |
+
)
|
| 50 |
+
|
| 51 |
+
extra_flags = []
|
| 52 |
+
|
| 53 |
+
cache_autogptq_cuda_256_sources = ["./cache_autogptq_cuda_256.cpp",
|
| 54 |
+
"./cache_autogptq_cuda_kernel_256.cu"]
|
| 55 |
+
cache_autogptq_cuda_256 = _cpp_extention_load_helper("cache_autogptq_cuda_256", cache_autogptq_cuda_256_sources, extra_flags)
|
generation_config.json
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"chat_format": "chatml",
|
| 3 |
+
"eos_token_id": 151643,
|
| 4 |
+
"pad_token_id": 151643,
|
| 5 |
+
"max_window_size": 6144,
|
| 6 |
+
"max_new_tokens": 512,
|
| 7 |
+
"do_sample": true,
|
| 8 |
+
"top_k": 0,
|
| 9 |
+
"top_p": 0.5,
|
| 10 |
+
"transformers_version": "4.31.0"
|
| 11 |
+
}
|
model-00001-of-00005.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d90ed52eb3d78f1dfb3dae4442e15be20e3091721d3922fe2aa66f216ee977aa
|
| 3 |
+
size 2027803784
|
model-00002-of-00005.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0a22dce056808bfd0431682148c2328b783c71e6be6012e9893788e8f684e23a
|
| 3 |
+
size 2027137056
|
model-00003-of-00005.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b1a8b8e02257f5ac689e0a66585a630bb6f4d1b48840b26234f81e5f4ba4d2d6
|
| 3 |
+
size 2027123384
|
model-00004-of-00005.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d4c0c11d36d163bc83fef6eff3cb62d9fd57454ee0b9472c94f4dd2d86ac3915
|
| 3 |
+
size 1797232848
|
model-00005-of-00005.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:1af00198dd551fb60493d7bd5ca1233dadf5082745b921e0e4d2707402133caa
|
| 3 |
+
size 1244659840
|
model.safetensors.index.json
ADDED
|
@@ -0,0 +1,874 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_size": 9123864576
|
| 4 |
+
},
|
| 5 |
+
"weight_map": {
|
| 6 |
+
"lm_head.weight": "model-00005-of-00005.safetensors",
|
| 7 |
+
"transformer.h.0.attn.c_attn.bias": "model-00001-of-00005.safetensors",
|
| 8 |
+
"transformer.h.0.attn.c_attn.g_idx": "model-00001-of-00005.safetensors",
|
| 9 |
+
"transformer.h.0.attn.c_attn.qweight": "model-00001-of-00005.safetensors",
|
| 10 |
+
"transformer.h.0.attn.c_attn.qzeros": "model-00001-of-00005.safetensors",
|
| 11 |
+
"transformer.h.0.attn.c_attn.scales": "model-00001-of-00005.safetensors",
|
| 12 |
+
"transformer.h.0.attn.c_proj.bias": "model-00001-of-00005.safetensors",
|
| 13 |
+
"transformer.h.0.attn.c_proj.g_idx": "model-00001-of-00005.safetensors",
|
| 14 |
+
"transformer.h.0.attn.c_proj.qweight": "model-00001-of-00005.safetensors",
|
| 15 |
+
"transformer.h.0.attn.c_proj.qzeros": "model-00001-of-00005.safetensors",
|
| 16 |
+
"transformer.h.0.attn.c_proj.scales": "model-00001-of-00005.safetensors",
|
| 17 |
+
"transformer.h.0.ln_1.weight": "model-00001-of-00005.safetensors",
|
| 18 |
+
"transformer.h.0.ln_2.weight": "model-00001-of-00005.safetensors",
|
| 19 |
+
"transformer.h.0.mlp.c_proj.bias": "model-00001-of-00005.safetensors",
|
| 20 |
+
"transformer.h.0.mlp.c_proj.g_idx": "model-00001-of-00005.safetensors",
|
| 21 |
+
"transformer.h.0.mlp.c_proj.qweight": "model-00001-of-00005.safetensors",
|
| 22 |
+
"transformer.h.0.mlp.c_proj.qzeros": "model-00001-of-00005.safetensors",
|
| 23 |
+
"transformer.h.0.mlp.c_proj.scales": "model-00001-of-00005.safetensors",
|
| 24 |
+
"transformer.h.0.mlp.w1.bias": "model-00001-of-00005.safetensors",
|
| 25 |
+
"transformer.h.0.mlp.w1.g_idx": "model-00001-of-00005.safetensors",
|
| 26 |
+
"transformer.h.0.mlp.w1.qweight": "model-00001-of-00005.safetensors",
|
| 27 |
+
"transformer.h.0.mlp.w1.qzeros": "model-00001-of-00005.safetensors",
|
| 28 |
+
"transformer.h.0.mlp.w1.scales": "model-00001-of-00005.safetensors",
|
| 29 |
+
"transformer.h.0.mlp.w2.bias": "model-00001-of-00005.safetensors",
|
| 30 |
+
"transformer.h.0.mlp.w2.g_idx": "model-00001-of-00005.safetensors",
|
| 31 |
+
"transformer.h.0.mlp.w2.qweight": "model-00001-of-00005.safetensors",
|
| 32 |
+
"transformer.h.0.mlp.w2.qzeros": "model-00001-of-00005.safetensors",
|
| 33 |
+
"transformer.h.0.mlp.w2.scales": "model-00001-of-00005.safetensors",
|
| 34 |
+
"transformer.h.1.attn.c_attn.bias": "model-00001-of-00005.safetensors",
|
| 35 |
+
"transformer.h.1.attn.c_attn.g_idx": "model-00001-of-00005.safetensors",
|
| 36 |
+
"transformer.h.1.attn.c_attn.qweight": "model-00001-of-00005.safetensors",
|
| 37 |
+
"transformer.h.1.attn.c_attn.qzeros": "model-00001-of-00005.safetensors",
|
| 38 |
+
"transformer.h.1.attn.c_attn.scales": "model-00001-of-00005.safetensors",
|
| 39 |
+
"transformer.h.1.attn.c_proj.bias": "model-00001-of-00005.safetensors",
|
| 40 |
+
"transformer.h.1.attn.c_proj.g_idx": "model-00001-of-00005.safetensors",
|
| 41 |
+
"transformer.h.1.attn.c_proj.qweight": "model-00001-of-00005.safetensors",
|
| 42 |
+
"transformer.h.1.attn.c_proj.qzeros": "model-00001-of-00005.safetensors",
|
| 43 |
+
"transformer.h.1.attn.c_proj.scales": "model-00001-of-00005.safetensors",
|
| 44 |
+
"transformer.h.1.ln_1.weight": "model-00001-of-00005.safetensors",
|
| 45 |
+
"transformer.h.1.ln_2.weight": "model-00001-of-00005.safetensors",
|
| 46 |
+
"transformer.h.1.mlp.c_proj.bias": "model-00001-of-00005.safetensors",
|
| 47 |
+
"transformer.h.1.mlp.c_proj.g_idx": "model-00001-of-00005.safetensors",
|
| 48 |
+
"transformer.h.1.mlp.c_proj.qweight": "model-00001-of-00005.safetensors",
|
| 49 |
+
"transformer.h.1.mlp.c_proj.qzeros": "model-00001-of-00005.safetensors",
|
| 50 |
+
"transformer.h.1.mlp.c_proj.scales": "model-00001-of-00005.safetensors",
|
| 51 |
+
"transformer.h.1.mlp.w1.bias": "model-00001-of-00005.safetensors",
|
| 52 |
+
"transformer.h.1.mlp.w1.g_idx": "model-00001-of-00005.safetensors",
|
| 53 |
+
"transformer.h.1.mlp.w1.qweight": "model-00001-of-00005.safetensors",
|
| 54 |
+
"transformer.h.1.mlp.w1.qzeros": "model-00001-of-00005.safetensors",
|
| 55 |
+
"transformer.h.1.mlp.w1.scales": "model-00001-of-00005.safetensors",
|
| 56 |
+
"transformer.h.1.mlp.w2.bias": "model-00001-of-00005.safetensors",
|
| 57 |
+
"transformer.h.1.mlp.w2.g_idx": "model-00001-of-00005.safetensors",
|
| 58 |
+
"transformer.h.1.mlp.w2.qweight": "model-00001-of-00005.safetensors",
|
| 59 |
+
"transformer.h.1.mlp.w2.qzeros": "model-00001-of-00005.safetensors",
|
| 60 |
+
"transformer.h.1.mlp.w2.scales": "model-00001-of-00005.safetensors",
|
| 61 |
+
"transformer.h.10.attn.c_attn.bias": "model-00002-of-00005.safetensors",
|
| 62 |
+
"transformer.h.10.attn.c_attn.g_idx": "model-00002-of-00005.safetensors",
|
| 63 |
+
"transformer.h.10.attn.c_attn.qweight": "model-00002-of-00005.safetensors",
|
| 64 |
+
"transformer.h.10.attn.c_attn.qzeros": "model-00002-of-00005.safetensors",
|
| 65 |
+
"transformer.h.10.attn.c_attn.scales": "model-00002-of-00005.safetensors",
|
| 66 |
+
"transformer.h.10.attn.c_proj.bias": "model-00002-of-00005.safetensors",
|
| 67 |
+
"transformer.h.10.attn.c_proj.g_idx": "model-00002-of-00005.safetensors",
|
| 68 |
+
"transformer.h.10.attn.c_proj.qweight": "model-00002-of-00005.safetensors",
|
| 69 |
+
"transformer.h.10.attn.c_proj.qzeros": "model-00002-of-00005.safetensors",
|
| 70 |
+
"transformer.h.10.attn.c_proj.scales": "model-00002-of-00005.safetensors",
|
| 71 |
+
"transformer.h.10.ln_1.weight": "model-00002-of-00005.safetensors",
|
| 72 |
+
"transformer.h.10.ln_2.weight": "model-00002-of-00005.safetensors",
|
| 73 |
+
"transformer.h.10.mlp.c_proj.bias": "model-00002-of-00005.safetensors",
|
| 74 |
+
"transformer.h.10.mlp.c_proj.g_idx": "model-00002-of-00005.safetensors",
|
| 75 |
+
"transformer.h.10.mlp.c_proj.qweight": "model-00002-of-00005.safetensors",
|
| 76 |
+
"transformer.h.10.mlp.c_proj.qzeros": "model-00002-of-00005.safetensors",
|
| 77 |
+
"transformer.h.10.mlp.c_proj.scales": "model-00002-of-00005.safetensors",
|
| 78 |
+
"transformer.h.10.mlp.w1.bias": "model-00002-of-00005.safetensors",
|
| 79 |
+
"transformer.h.10.mlp.w1.g_idx": "model-00002-of-00005.safetensors",
|
| 80 |
+
"transformer.h.10.mlp.w1.qweight": "model-00002-of-00005.safetensors",
|
| 81 |
+
"transformer.h.10.mlp.w1.qzeros": "model-00002-of-00005.safetensors",
|
| 82 |
+
"transformer.h.10.mlp.w1.scales": "model-00002-of-00005.safetensors",
|
| 83 |
+
"transformer.h.10.mlp.w2.bias": "model-00002-of-00005.safetensors",
|
| 84 |
+
"transformer.h.10.mlp.w2.g_idx": "model-00002-of-00005.safetensors",
|
| 85 |
+
"transformer.h.10.mlp.w2.qweight": "model-00002-of-00005.safetensors",
|
| 86 |
+
"transformer.h.10.mlp.w2.qzeros": "model-00002-of-00005.safetensors",
|
| 87 |
+
"transformer.h.10.mlp.w2.scales": "model-00002-of-00005.safetensors",
|
| 88 |
+
"transformer.h.11.attn.c_attn.bias": "model-00002-of-00005.safetensors",
|
| 89 |
+
"transformer.h.11.attn.c_attn.g_idx": "model-00002-of-00005.safetensors",
|
| 90 |
+
"transformer.h.11.attn.c_attn.qweight": "model-00002-of-00005.safetensors",
|
| 91 |
+
"transformer.h.11.attn.c_attn.qzeros": "model-00002-of-00005.safetensors",
|
| 92 |
+
"transformer.h.11.attn.c_attn.scales": "model-00002-of-00005.safetensors",
|
| 93 |
+
"transformer.h.11.attn.c_proj.bias": "model-00002-of-00005.safetensors",
|
| 94 |
+
"transformer.h.11.attn.c_proj.g_idx": "model-00002-of-00005.safetensors",
|
| 95 |
+
"transformer.h.11.attn.c_proj.qweight": "model-00002-of-00005.safetensors",
|
| 96 |
+
"transformer.h.11.attn.c_proj.qzeros": "model-00002-of-00005.safetensors",
|
| 97 |
+
"transformer.h.11.attn.c_proj.scales": "model-00002-of-00005.safetensors",
|
| 98 |
+
"transformer.h.11.ln_1.weight": "model-00002-of-00005.safetensors",
|
| 99 |
+
"transformer.h.11.ln_2.weight": "model-00002-of-00005.safetensors",
|
| 100 |
+
"transformer.h.11.mlp.c_proj.bias": "model-00002-of-00005.safetensors",
|
| 101 |
+
"transformer.h.11.mlp.c_proj.g_idx": "model-00002-of-00005.safetensors",
|
| 102 |
+
"transformer.h.11.mlp.c_proj.qweight": "model-00002-of-00005.safetensors",
|
| 103 |
+
"transformer.h.11.mlp.c_proj.qzeros": "model-00002-of-00005.safetensors",
|
| 104 |
+
"transformer.h.11.mlp.c_proj.scales": "model-00002-of-00005.safetensors",
|
| 105 |
+
"transformer.h.11.mlp.w1.bias": "model-00002-of-00005.safetensors",
|
| 106 |
+
"transformer.h.11.mlp.w1.g_idx": "model-00002-of-00005.safetensors",
|
| 107 |
+
"transformer.h.11.mlp.w1.qweight": "model-00002-of-00005.safetensors",
|
| 108 |
+
"transformer.h.11.mlp.w1.qzeros": "model-00002-of-00005.safetensors",
|
| 109 |
+
"transformer.h.11.mlp.w1.scales": "model-00002-of-00005.safetensors",
|
| 110 |
+
"transformer.h.11.mlp.w2.bias": "model-00002-of-00005.safetensors",
|
| 111 |
+
"transformer.h.11.mlp.w2.g_idx": "model-00002-of-00005.safetensors",
|
| 112 |
+
"transformer.h.11.mlp.w2.qweight": "model-00002-of-00005.safetensors",
|
| 113 |
+
"transformer.h.11.mlp.w2.qzeros": "model-00002-of-00005.safetensors",
|
| 114 |
+
"transformer.h.11.mlp.w2.scales": "model-00002-of-00005.safetensors",
|
| 115 |
+
"transformer.h.12.attn.c_attn.bias": "model-00002-of-00005.safetensors",
|
| 116 |
+
"transformer.h.12.attn.c_attn.g_idx": "model-00002-of-00005.safetensors",
|
| 117 |
+
"transformer.h.12.attn.c_attn.qweight": "model-00002-of-00005.safetensors",
|
| 118 |
+
"transformer.h.12.attn.c_attn.qzeros": "model-00002-of-00005.safetensors",
|
| 119 |
+
"transformer.h.12.attn.c_attn.scales": "model-00002-of-00005.safetensors",
|
| 120 |
+
"transformer.h.12.attn.c_proj.bias": "model-00002-of-00005.safetensors",
|
| 121 |
+
"transformer.h.12.attn.c_proj.g_idx": "model-00002-of-00005.safetensors",
|
| 122 |
+
"transformer.h.12.attn.c_proj.qweight": "model-00002-of-00005.safetensors",
|
| 123 |
+
"transformer.h.12.attn.c_proj.qzeros": "model-00002-of-00005.safetensors",
|
| 124 |
+
"transformer.h.12.attn.c_proj.scales": "model-00002-of-00005.safetensors",
|
| 125 |
+
"transformer.h.12.ln_1.weight": "model-00002-of-00005.safetensors",
|
| 126 |
+
"transformer.h.12.ln_2.weight": "model-00002-of-00005.safetensors",
|
| 127 |
+
"transformer.h.12.mlp.c_proj.bias": "model-00002-of-00005.safetensors",
|
| 128 |
+
"transformer.h.12.mlp.c_proj.g_idx": "model-00002-of-00005.safetensors",
|
| 129 |
+
"transformer.h.12.mlp.c_proj.qweight": "model-00002-of-00005.safetensors",
|
| 130 |
+
"transformer.h.12.mlp.c_proj.qzeros": "model-00002-of-00005.safetensors",
|
| 131 |
+
"transformer.h.12.mlp.c_proj.scales": "model-00002-of-00005.safetensors",
|
| 132 |
+
"transformer.h.12.mlp.w1.bias": "model-00002-of-00005.safetensors",
|
| 133 |
+
"transformer.h.12.mlp.w1.g_idx": "model-00002-of-00005.safetensors",
|
| 134 |
+
"transformer.h.12.mlp.w1.qweight": "model-00002-of-00005.safetensors",
|
| 135 |
+
"transformer.h.12.mlp.w1.qzeros": "model-00002-of-00005.safetensors",
|
| 136 |
+
"transformer.h.12.mlp.w1.scales": "model-00002-of-00005.safetensors",
|
| 137 |
+
"transformer.h.12.mlp.w2.bias": "model-00002-of-00005.safetensors",
|
| 138 |
+
"transformer.h.12.mlp.w2.g_idx": "model-00002-of-00005.safetensors",
|
| 139 |
+
"transformer.h.12.mlp.w2.qweight": "model-00002-of-00005.safetensors",
|
| 140 |
+
"transformer.h.12.mlp.w2.qzeros": "model-00002-of-00005.safetensors",
|
| 141 |
+
"transformer.h.12.mlp.w2.scales": "model-00002-of-00005.safetensors",
|
| 142 |
+
"transformer.h.13.attn.c_attn.bias": "model-00002-of-00005.safetensors",
|
| 143 |
+
"transformer.h.13.attn.c_attn.g_idx": "model-00002-of-00005.safetensors",
|
| 144 |
+
"transformer.h.13.attn.c_attn.qweight": "model-00002-of-00005.safetensors",
|
| 145 |
+
"transformer.h.13.attn.c_attn.qzeros": "model-00002-of-00005.safetensors",
|
| 146 |
+
"transformer.h.13.attn.c_attn.scales": "model-00002-of-00005.safetensors",
|
| 147 |
+
"transformer.h.13.attn.c_proj.bias": "model-00002-of-00005.safetensors",
|
| 148 |
+
"transformer.h.13.attn.c_proj.g_idx": "model-00002-of-00005.safetensors",
|
| 149 |
+
"transformer.h.13.attn.c_proj.qweight": "model-00002-of-00005.safetensors",
|
| 150 |
+
"transformer.h.13.attn.c_proj.qzeros": "model-00002-of-00005.safetensors",
|
| 151 |
+
"transformer.h.13.attn.c_proj.scales": "model-00002-of-00005.safetensors",
|
| 152 |
+
"transformer.h.13.ln_1.weight": "model-00002-of-00005.safetensors",
|
| 153 |
+
"transformer.h.13.ln_2.weight": "model-00002-of-00005.safetensors",
|
| 154 |
+
"transformer.h.13.mlp.c_proj.bias": "model-00002-of-00005.safetensors",
|
| 155 |
+
"transformer.h.13.mlp.c_proj.g_idx": "model-00002-of-00005.safetensors",
|
| 156 |
+
"transformer.h.13.mlp.c_proj.qweight": "model-00002-of-00005.safetensors",
|
| 157 |
+
"transformer.h.13.mlp.c_proj.qzeros": "model-00002-of-00005.safetensors",
|
| 158 |
+
"transformer.h.13.mlp.c_proj.scales": "model-00002-of-00005.safetensors",
|
| 159 |
+
"transformer.h.13.mlp.w1.bias": "model-00003-of-00005.safetensors",
|
| 160 |
+
"transformer.h.13.mlp.w1.g_idx": "model-00003-of-00005.safetensors",
|
| 161 |
+
"transformer.h.13.mlp.w1.qweight": "model-00003-of-00005.safetensors",
|
| 162 |
+
"transformer.h.13.mlp.w1.qzeros": "model-00003-of-00005.safetensors",
|
| 163 |
+
"transformer.h.13.mlp.w1.scales": "model-00003-of-00005.safetensors",
|
| 164 |
+
"transformer.h.13.mlp.w2.bias": "model-00003-of-00005.safetensors",
|
| 165 |
+
"transformer.h.13.mlp.w2.g_idx": "model-00003-of-00005.safetensors",
|
| 166 |
+
"transformer.h.13.mlp.w2.qweight": "model-00003-of-00005.safetensors",
|
| 167 |
+
"transformer.h.13.mlp.w2.qzeros": "model-00003-of-00005.safetensors",
|
| 168 |
+
"transformer.h.13.mlp.w2.scales": "model-00003-of-00005.safetensors",
|
| 169 |
+
"transformer.h.14.attn.c_attn.bias": "model-00003-of-00005.safetensors",
|
| 170 |
+
"transformer.h.14.attn.c_attn.g_idx": "model-00003-of-00005.safetensors",
|
| 171 |
+
"transformer.h.14.attn.c_attn.qweight": "model-00003-of-00005.safetensors",
|
| 172 |
+
"transformer.h.14.attn.c_attn.qzeros": "model-00003-of-00005.safetensors",
|
| 173 |
+
"transformer.h.14.attn.c_attn.scales": "model-00003-of-00005.safetensors",
|
| 174 |
+
"transformer.h.14.attn.c_proj.bias": "model-00003-of-00005.safetensors",
|
| 175 |
+
"transformer.h.14.attn.c_proj.g_idx": "model-00003-of-00005.safetensors",
|
| 176 |
+
"transformer.h.14.attn.c_proj.qweight": "model-00003-of-00005.safetensors",
|
| 177 |
+
"transformer.h.14.attn.c_proj.qzeros": "model-00003-of-00005.safetensors",
|
| 178 |
+
"transformer.h.14.attn.c_proj.scales": "model-00003-of-00005.safetensors",
|
| 179 |
+
"transformer.h.14.ln_1.weight": "model-00003-of-00005.safetensors",
|
| 180 |
+
"transformer.h.14.ln_2.weight": "model-00003-of-00005.safetensors",
|
| 181 |
+
"transformer.h.14.mlp.c_proj.bias": "model-00003-of-00005.safetensors",
|
| 182 |
+
"transformer.h.14.mlp.c_proj.g_idx": "model-00003-of-00005.safetensors",
|
| 183 |
+
"transformer.h.14.mlp.c_proj.qweight": "model-00003-of-00005.safetensors",
|
| 184 |
+
"transformer.h.14.mlp.c_proj.qzeros": "model-00003-of-00005.safetensors",
|
| 185 |
+
"transformer.h.14.mlp.c_proj.scales": "model-00003-of-00005.safetensors",
|
| 186 |
+
"transformer.h.14.mlp.w1.bias": "model-00003-of-00005.safetensors",
|
| 187 |
+
"transformer.h.14.mlp.w1.g_idx": "model-00003-of-00005.safetensors",
|
| 188 |
+
"transformer.h.14.mlp.w1.qweight": "model-00003-of-00005.safetensors",
|
| 189 |
+
"transformer.h.14.mlp.w1.qzeros": "model-00003-of-00005.safetensors",
|
| 190 |
+
"transformer.h.14.mlp.w1.scales": "model-00003-of-00005.safetensors",
|
| 191 |
+
"transformer.h.14.mlp.w2.bias": "model-00003-of-00005.safetensors",
|
| 192 |
+
"transformer.h.14.mlp.w2.g_idx": "model-00003-of-00005.safetensors",
|
| 193 |
+
"transformer.h.14.mlp.w2.qweight": "model-00003-of-00005.safetensors",
|
| 194 |
+
"transformer.h.14.mlp.w2.qzeros": "model-00003-of-00005.safetensors",
|
| 195 |
+
"transformer.h.14.mlp.w2.scales": "model-00003-of-00005.safetensors",
|
| 196 |
+
"transformer.h.15.attn.c_attn.bias": "model-00003-of-00005.safetensors",
|
| 197 |
+
"transformer.h.15.attn.c_attn.g_idx": "model-00003-of-00005.safetensors",
|
| 198 |
+
"transformer.h.15.attn.c_attn.qweight": "model-00003-of-00005.safetensors",
|
| 199 |
+
"transformer.h.15.attn.c_attn.qzeros": "model-00003-of-00005.safetensors",
|
| 200 |
+
"transformer.h.15.attn.c_attn.scales": "model-00003-of-00005.safetensors",
|
| 201 |
+
"transformer.h.15.attn.c_proj.bias": "model-00003-of-00005.safetensors",
|
| 202 |
+
"transformer.h.15.attn.c_proj.g_idx": "model-00003-of-00005.safetensors",
|
| 203 |
+
"transformer.h.15.attn.c_proj.qweight": "model-00003-of-00005.safetensors",
|
| 204 |
+
"transformer.h.15.attn.c_proj.qzeros": "model-00003-of-00005.safetensors",
|
| 205 |
+
"transformer.h.15.attn.c_proj.scales": "model-00003-of-00005.safetensors",
|
| 206 |
+
"transformer.h.15.ln_1.weight": "model-00003-of-00005.safetensors",
|
| 207 |
+
"transformer.h.15.ln_2.weight": "model-00003-of-00005.safetensors",
|
| 208 |
+
"transformer.h.15.mlp.c_proj.bias": "model-00003-of-00005.safetensors",
|
| 209 |
+
"transformer.h.15.mlp.c_proj.g_idx": "model-00003-of-00005.safetensors",
|
| 210 |
+
"transformer.h.15.mlp.c_proj.qweight": "model-00003-of-00005.safetensors",
|
| 211 |
+
"transformer.h.15.mlp.c_proj.qzeros": "model-00003-of-00005.safetensors",
|
| 212 |
+
"transformer.h.15.mlp.c_proj.scales": "model-00003-of-00005.safetensors",
|
| 213 |
+
"transformer.h.15.mlp.w1.bias": "model-00003-of-00005.safetensors",
|
| 214 |
+
"transformer.h.15.mlp.w1.g_idx": "model-00003-of-00005.safetensors",
|
| 215 |
+
"transformer.h.15.mlp.w1.qweight": "model-00003-of-00005.safetensors",
|
| 216 |
+
"transformer.h.15.mlp.w1.qzeros": "model-00003-of-00005.safetensors",
|
| 217 |
+
"transformer.h.15.mlp.w1.scales": "model-00003-of-00005.safetensors",
|
| 218 |
+
"transformer.h.15.mlp.w2.bias": "model-00003-of-00005.safetensors",
|
| 219 |
+
"transformer.h.15.mlp.w2.g_idx": "model-00003-of-00005.safetensors",
|
| 220 |
+
"transformer.h.15.mlp.w2.qweight": "model-00003-of-00005.safetensors",
|
| 221 |
+
"transformer.h.15.mlp.w2.qzeros": "model-00003-of-00005.safetensors",
|
| 222 |
+
"transformer.h.15.mlp.w2.scales": "model-00003-of-00005.safetensors",
|
| 223 |
+
"transformer.h.16.attn.c_attn.bias": "model-00003-of-00005.safetensors",
|
| 224 |
+
"transformer.h.16.attn.c_attn.g_idx": "model-00003-of-00005.safetensors",
|
| 225 |
+
"transformer.h.16.attn.c_attn.qweight": "model-00003-of-00005.safetensors",
|
| 226 |
+
"transformer.h.16.attn.c_attn.qzeros": "model-00003-of-00005.safetensors",
|
| 227 |
+
"transformer.h.16.attn.c_attn.scales": "model-00003-of-00005.safetensors",
|
| 228 |
+
"transformer.h.16.attn.c_proj.bias": "model-00003-of-00005.safetensors",
|
| 229 |
+
"transformer.h.16.attn.c_proj.g_idx": "model-00003-of-00005.safetensors",
|
| 230 |
+
"transformer.h.16.attn.c_proj.qweight": "model-00003-of-00005.safetensors",
|
| 231 |
+
"transformer.h.16.attn.c_proj.qzeros": "model-00003-of-00005.safetensors",
|
| 232 |
+
"transformer.h.16.attn.c_proj.scales": "model-00003-of-00005.safetensors",
|
| 233 |
+
"transformer.h.16.ln_1.weight": "model-00003-of-00005.safetensors",
|
| 234 |
+
"transformer.h.16.ln_2.weight": "model-00003-of-00005.safetensors",
|
| 235 |
+
"transformer.h.16.mlp.c_proj.bias": "model-00003-of-00005.safetensors",
|
| 236 |
+
"transformer.h.16.mlp.c_proj.g_idx": "model-00003-of-00005.safetensors",
|
| 237 |
+
"transformer.h.16.mlp.c_proj.qweight": "model-00003-of-00005.safetensors",
|
| 238 |
+
"transformer.h.16.mlp.c_proj.qzeros": "model-00003-of-00005.safetensors",
|
| 239 |
+
"transformer.h.16.mlp.c_proj.scales": "model-00003-of-00005.safetensors",
|
| 240 |
+
"transformer.h.16.mlp.w1.bias": "model-00003-of-00005.safetensors",
|
| 241 |
+
"transformer.h.16.mlp.w1.g_idx": "model-00003-of-00005.safetensors",
|
| 242 |
+
"transformer.h.16.mlp.w1.qweight": "model-00003-of-00005.safetensors",
|
| 243 |
+
"transformer.h.16.mlp.w1.qzeros": "model-00003-of-00005.safetensors",
|
| 244 |
+
"transformer.h.16.mlp.w1.scales": "model-00003-of-00005.safetensors",
|
| 245 |
+
"transformer.h.16.mlp.w2.bias": "model-00003-of-00005.safetensors",
|
| 246 |
+
"transformer.h.16.mlp.w2.g_idx": "model-00003-of-00005.safetensors",
|
| 247 |
+
"transformer.h.16.mlp.w2.qweight": "model-00003-of-00005.safetensors",
|
| 248 |
+
"transformer.h.16.mlp.w2.qzeros": "model-00003-of-00005.safetensors",
|
| 249 |
+
"transformer.h.16.mlp.w2.scales": "model-00003-of-00005.safetensors",
|
| 250 |
+
"transformer.h.17.attn.c_attn.bias": "model-00003-of-00005.safetensors",
|
| 251 |
+
"transformer.h.17.attn.c_attn.g_idx": "model-00003-of-00005.safetensors",
|
| 252 |
+
"transformer.h.17.attn.c_attn.qweight": "model-00003-of-00005.safetensors",
|
| 253 |
+
"transformer.h.17.attn.c_attn.qzeros": "model-00003-of-00005.safetensors",
|
| 254 |
+
"transformer.h.17.attn.c_attn.scales": "model-00003-of-00005.safetensors",
|
| 255 |
+
"transformer.h.17.attn.c_proj.bias": "model-00003-of-00005.safetensors",
|
| 256 |
+
"transformer.h.17.attn.c_proj.g_idx": "model-00003-of-00005.safetensors",
|
| 257 |
+
"transformer.h.17.attn.c_proj.qweight": "model-00003-of-00005.safetensors",
|
| 258 |
+
"transformer.h.17.attn.c_proj.qzeros": "model-00003-of-00005.safetensors",
|
| 259 |
+
"transformer.h.17.attn.c_proj.scales": "model-00003-of-00005.safetensors",
|
| 260 |
+
"transformer.h.17.ln_1.weight": "model-00003-of-00005.safetensors",
|
| 261 |
+
"transformer.h.17.ln_2.weight": "model-00003-of-00005.safetensors",
|
| 262 |
+
"transformer.h.17.mlp.c_proj.bias": "model-00003-of-00005.safetensors",
|
| 263 |
+
"transformer.h.17.mlp.c_proj.g_idx": "model-00003-of-00005.safetensors",
|
| 264 |
+
"transformer.h.17.mlp.c_proj.qweight": "model-00003-of-00005.safetensors",
|
| 265 |
+
"transformer.h.17.mlp.c_proj.qzeros": "model-00003-of-00005.safetensors",
|
| 266 |
+
"transformer.h.17.mlp.c_proj.scales": "model-00003-of-00005.safetensors",
|
| 267 |
+
"transformer.h.17.mlp.w1.bias": "model-00003-of-00005.safetensors",
|
| 268 |
+
"transformer.h.17.mlp.w1.g_idx": "model-00003-of-00005.safetensors",
|
| 269 |
+
"transformer.h.17.mlp.w1.qweight": "model-00003-of-00005.safetensors",
|
| 270 |
+
"transformer.h.17.mlp.w1.qzeros": "model-00003-of-00005.safetensors",
|
| 271 |
+
"transformer.h.17.mlp.w1.scales": "model-00003-of-00005.safetensors",
|
| 272 |
+
"transformer.h.17.mlp.w2.bias": "model-00003-of-00005.safetensors",
|
| 273 |
+
"transformer.h.17.mlp.w2.g_idx": "model-00003-of-00005.safetensors",
|
| 274 |
+
"transformer.h.17.mlp.w2.qweight": "model-00003-of-00005.safetensors",
|
| 275 |
+
"transformer.h.17.mlp.w2.qzeros": "model-00003-of-00005.safetensors",
|
| 276 |
+
"transformer.h.17.mlp.w2.scales": "model-00003-of-00005.safetensors",
|
| 277 |
+
"transformer.h.18.attn.c_attn.bias": "model-00003-of-00005.safetensors",
|
| 278 |
+
"transformer.h.18.attn.c_attn.g_idx": "model-00003-of-00005.safetensors",
|
| 279 |
+
"transformer.h.18.attn.c_attn.qweight": "model-00003-of-00005.safetensors",
|
| 280 |
+
"transformer.h.18.attn.c_attn.qzeros": "model-00003-of-00005.safetensors",
|
| 281 |
+
"transformer.h.18.attn.c_attn.scales": "model-00003-of-00005.safetensors",
|
| 282 |
+
"transformer.h.18.attn.c_proj.bias": "model-00003-of-00005.safetensors",
|
| 283 |
+
"transformer.h.18.attn.c_proj.g_idx": "model-00003-of-00005.safetensors",
|
| 284 |
+
"transformer.h.18.attn.c_proj.qweight": "model-00003-of-00005.safetensors",
|
| 285 |
+
"transformer.h.18.attn.c_proj.qzeros": "model-00003-of-00005.safetensors",
|
| 286 |
+
"transformer.h.18.attn.c_proj.scales": "model-00003-of-00005.safetensors",
|
| 287 |
+
"transformer.h.18.ln_1.weight": "model-00003-of-00005.safetensors",
|
| 288 |
+
"transformer.h.18.ln_2.weight": "model-00003-of-00005.safetensors",
|
| 289 |
+
"transformer.h.18.mlp.c_proj.bias": "model-00003-of-00005.safetensors",
|
| 290 |
+
"transformer.h.18.mlp.c_proj.g_idx": "model-00003-of-00005.safetensors",
|
| 291 |
+
"transformer.h.18.mlp.c_proj.qweight": "model-00003-of-00005.safetensors",
|
| 292 |
+
"transformer.h.18.mlp.c_proj.qzeros": "model-00003-of-00005.safetensors",
|
| 293 |
+
"transformer.h.18.mlp.c_proj.scales": "model-00003-of-00005.safetensors",
|
| 294 |
+
"transformer.h.18.mlp.w1.bias": "model-00003-of-00005.safetensors",
|
| 295 |
+
"transformer.h.18.mlp.w1.g_idx": "model-00003-of-00005.safetensors",
|
| 296 |
+
"transformer.h.18.mlp.w1.qweight": "model-00003-of-00005.safetensors",
|
| 297 |
+
"transformer.h.18.mlp.w1.qzeros": "model-00003-of-00005.safetensors",
|
| 298 |
+
"transformer.h.18.mlp.w1.scales": "model-00003-of-00005.safetensors",
|
| 299 |
+
"transformer.h.18.mlp.w2.bias": "model-00003-of-00005.safetensors",
|
| 300 |
+
"transformer.h.18.mlp.w2.g_idx": "model-00003-of-00005.safetensors",
|
| 301 |
+
"transformer.h.18.mlp.w2.qweight": "model-00003-of-00005.safetensors",
|
| 302 |
+
"transformer.h.18.mlp.w2.qzeros": "model-00003-of-00005.safetensors",
|
| 303 |
+
"transformer.h.18.mlp.w2.scales": "model-00003-of-00005.safetensors",
|
| 304 |
+
"transformer.h.19.attn.c_attn.bias": "model-00003-of-00005.safetensors",
|
| 305 |
+
"transformer.h.19.attn.c_attn.g_idx": "model-00003-of-00005.safetensors",
|
| 306 |
+
"transformer.h.19.attn.c_attn.qweight": "model-00003-of-00005.safetensors",
|
| 307 |
+
"transformer.h.19.attn.c_attn.qzeros": "model-00003-of-00005.safetensors",
|
| 308 |
+
"transformer.h.19.attn.c_attn.scales": "model-00003-of-00005.safetensors",
|
| 309 |
+
"transformer.h.19.attn.c_proj.bias": "model-00003-of-00005.safetensors",
|
| 310 |
+
"transformer.h.19.attn.c_proj.g_idx": "model-00003-of-00005.safetensors",
|
| 311 |
+
"transformer.h.19.attn.c_proj.qweight": "model-00003-of-00005.safetensors",
|
| 312 |
+
"transformer.h.19.attn.c_proj.qzeros": "model-00003-of-00005.safetensors",
|
| 313 |
+
"transformer.h.19.attn.c_proj.scales": "model-00003-of-00005.safetensors",
|
| 314 |
+
"transformer.h.19.ln_1.weight": "model-00003-of-00005.safetensors",
|
| 315 |
+
"transformer.h.19.ln_2.weight": "model-00003-of-00005.safetensors",
|
| 316 |
+
"transformer.h.19.mlp.c_proj.bias": "model-00003-of-00005.safetensors",
|
| 317 |
+
"transformer.h.19.mlp.c_proj.g_idx": "model-00003-of-00005.safetensors",
|
| 318 |
+
"transformer.h.19.mlp.c_proj.qweight": "model-00003-of-00005.safetensors",
|
| 319 |
+
"transformer.h.19.mlp.c_proj.qzeros": "model-00003-of-00005.safetensors",
|
| 320 |
+
"transformer.h.19.mlp.c_proj.scales": "model-00003-of-00005.safetensors",
|
| 321 |
+
"transformer.h.19.mlp.w1.bias": "model-00003-of-00005.safetensors",
|
| 322 |
+
"transformer.h.19.mlp.w1.g_idx": "model-00003-of-00005.safetensors",
|
| 323 |
+
"transformer.h.19.mlp.w1.qweight": "model-00003-of-00005.safetensors",
|
| 324 |
+
"transformer.h.19.mlp.w1.qzeros": "model-00003-of-00005.safetensors",
|
| 325 |
+
"transformer.h.19.mlp.w1.scales": "model-00003-of-00005.safetensors",
|
| 326 |
+
"transformer.h.19.mlp.w2.bias": "model-00003-of-00005.safetensors",
|
| 327 |
+
"transformer.h.19.mlp.w2.g_idx": "model-00003-of-00005.safetensors",
|
| 328 |
+
"transformer.h.19.mlp.w2.qweight": "model-00003-of-00005.safetensors",
|
| 329 |
+
"transformer.h.19.mlp.w2.qzeros": "model-00003-of-00005.safetensors",
|
| 330 |
+
"transformer.h.19.mlp.w2.scales": "model-00003-of-00005.safetensors",
|
| 331 |
+
"transformer.h.2.attn.c_attn.bias": "model-00001-of-00005.safetensors",
|
| 332 |
+
"transformer.h.2.attn.c_attn.g_idx": "model-00001-of-00005.safetensors",
|
| 333 |
+
"transformer.h.2.attn.c_attn.qweight": "model-00001-of-00005.safetensors",
|
| 334 |
+
"transformer.h.2.attn.c_attn.qzeros": "model-00001-of-00005.safetensors",
|
| 335 |
+
"transformer.h.2.attn.c_attn.scales": "model-00001-of-00005.safetensors",
|
| 336 |
+
"transformer.h.2.attn.c_proj.bias": "model-00001-of-00005.safetensors",
|
| 337 |
+
"transformer.h.2.attn.c_proj.g_idx": "model-00001-of-00005.safetensors",
|
| 338 |
+
"transformer.h.2.attn.c_proj.qweight": "model-00001-of-00005.safetensors",
|
| 339 |
+
"transformer.h.2.attn.c_proj.qzeros": "model-00001-of-00005.safetensors",
|
| 340 |
+
"transformer.h.2.attn.c_proj.scales": "model-00001-of-00005.safetensors",
|
| 341 |
+
"transformer.h.2.ln_1.weight": "model-00001-of-00005.safetensors",
|
| 342 |
+
"transformer.h.2.ln_2.weight": "model-00001-of-00005.safetensors",
|
| 343 |
+
"transformer.h.2.mlp.c_proj.bias": "model-00001-of-00005.safetensors",
|
| 344 |
+
"transformer.h.2.mlp.c_proj.g_idx": "model-00001-of-00005.safetensors",
|
| 345 |
+
"transformer.h.2.mlp.c_proj.qweight": "model-00001-of-00005.safetensors",
|
| 346 |
+
"transformer.h.2.mlp.c_proj.qzeros": "model-00001-of-00005.safetensors",
|
| 347 |
+
"transformer.h.2.mlp.c_proj.scales": "model-00001-of-00005.safetensors",
|
| 348 |
+
"transformer.h.2.mlp.w1.bias": "model-00001-of-00005.safetensors",
|
| 349 |
+
"transformer.h.2.mlp.w1.g_idx": "model-00001-of-00005.safetensors",
|
| 350 |
+
"transformer.h.2.mlp.w1.qweight": "model-00001-of-00005.safetensors",
|
| 351 |
+
"transformer.h.2.mlp.w1.qzeros": "model-00001-of-00005.safetensors",
|
| 352 |
+
"transformer.h.2.mlp.w1.scales": "model-00001-of-00005.safetensors",
|
| 353 |
+
"transformer.h.2.mlp.w2.bias": "model-00001-of-00005.safetensors",
|
| 354 |
+
"transformer.h.2.mlp.w2.g_idx": "model-00001-of-00005.safetensors",
|
| 355 |
+
"transformer.h.2.mlp.w2.qweight": "model-00001-of-00005.safetensors",
|
| 356 |
+
"transformer.h.2.mlp.w2.qzeros": "model-00001-of-00005.safetensors",
|
| 357 |
+
"transformer.h.2.mlp.w2.scales": "model-00001-of-00005.safetensors",
|
| 358 |
+
"transformer.h.20.attn.c_attn.bias": "model-00003-of-00005.safetensors",
|
| 359 |
+
"transformer.h.20.attn.c_attn.g_idx": "model-00003-of-00005.safetensors",
|
| 360 |
+
"transformer.h.20.attn.c_attn.qweight": "model-00003-of-00005.safetensors",
|
| 361 |
+
"transformer.h.20.attn.c_attn.qzeros": "model-00003-of-00005.safetensors",
|
| 362 |
+
"transformer.h.20.attn.c_attn.scales": "model-00003-of-00005.safetensors",
|
| 363 |
+
"transformer.h.20.attn.c_proj.bias": "model-00003-of-00005.safetensors",
|
| 364 |
+
"transformer.h.20.attn.c_proj.g_idx": "model-00003-of-00005.safetensors",
|
| 365 |
+
"transformer.h.20.attn.c_proj.qweight": "model-00003-of-00005.safetensors",
|
| 366 |
+
"transformer.h.20.attn.c_proj.qzeros": "model-00003-of-00005.safetensors",
|
| 367 |
+
"transformer.h.20.attn.c_proj.scales": "model-00003-of-00005.safetensors",
|
| 368 |
+
"transformer.h.20.ln_1.weight": "model-00003-of-00005.safetensors",
|
| 369 |
+
"transformer.h.20.ln_2.weight": "model-00003-of-00005.safetensors",
|
| 370 |
+
"transformer.h.20.mlp.c_proj.bias": "model-00003-of-00005.safetensors",
|
| 371 |
+
"transformer.h.20.mlp.c_proj.g_idx": "model-00003-of-00005.safetensors",
|
| 372 |
+
"transformer.h.20.mlp.c_proj.qweight": "model-00003-of-00005.safetensors",
|
| 373 |
+
"transformer.h.20.mlp.c_proj.qzeros": "model-00003-of-00005.safetensors",
|
| 374 |
+
"transformer.h.20.mlp.c_proj.scales": "model-00003-of-00005.safetensors",
|
| 375 |
+
"transformer.h.20.mlp.w1.bias": "model-00003-of-00005.safetensors",
|
| 376 |
+
"transformer.h.20.mlp.w1.g_idx": "model-00003-of-00005.safetensors",
|
| 377 |
+
"transformer.h.20.mlp.w1.qweight": "model-00003-of-00005.safetensors",
|
| 378 |
+
"transformer.h.20.mlp.w1.qzeros": "model-00003-of-00005.safetensors",
|
| 379 |
+
"transformer.h.20.mlp.w1.scales": "model-00003-of-00005.safetensors",
|
| 380 |
+
"transformer.h.20.mlp.w2.bias": "model-00003-of-00005.safetensors",
|
| 381 |
+
"transformer.h.20.mlp.w2.g_idx": "model-00003-of-00005.safetensors",
|
| 382 |
+
"transformer.h.20.mlp.w2.qweight": "model-00003-of-00005.safetensors",
|
| 383 |
+
"transformer.h.20.mlp.w2.qzeros": "model-00003-of-00005.safetensors",
|
| 384 |
+
"transformer.h.20.mlp.w2.scales": "model-00003-of-00005.safetensors",
|
| 385 |
+
"transformer.h.21.attn.c_attn.bias": "model-00003-of-00005.safetensors",
|
| 386 |
+
"transformer.h.21.attn.c_attn.g_idx": "model-00003-of-00005.safetensors",
|
| 387 |
+
"transformer.h.21.attn.c_attn.qweight": "model-00003-of-00005.safetensors",
|
| 388 |
+
"transformer.h.21.attn.c_attn.qzeros": "model-00003-of-00005.safetensors",
|
| 389 |
+
"transformer.h.21.attn.c_attn.scales": "model-00003-of-00005.safetensors",
|
| 390 |
+
"transformer.h.21.attn.c_proj.bias": "model-00003-of-00005.safetensors",
|
| 391 |
+
"transformer.h.21.attn.c_proj.g_idx": "model-00003-of-00005.safetensors",
|
| 392 |
+
"transformer.h.21.attn.c_proj.qweight": "model-00003-of-00005.safetensors",
|
| 393 |
+
"transformer.h.21.attn.c_proj.qzeros": "model-00003-of-00005.safetensors",
|
| 394 |
+
"transformer.h.21.attn.c_proj.scales": "model-00003-of-00005.safetensors",
|
| 395 |
+
"transformer.h.21.ln_1.weight": "model-00003-of-00005.safetensors",
|
| 396 |
+
"transformer.h.21.ln_2.weight": "model-00003-of-00005.safetensors",
|
| 397 |
+
"transformer.h.21.mlp.c_proj.bias": "model-00003-of-00005.safetensors",
|
| 398 |
+
"transformer.h.21.mlp.c_proj.g_idx": "model-00003-of-00005.safetensors",
|
| 399 |
+
"transformer.h.21.mlp.c_proj.qweight": "model-00003-of-00005.safetensors",
|
| 400 |
+
"transformer.h.21.mlp.c_proj.qzeros": "model-00003-of-00005.safetensors",
|
| 401 |
+
"transformer.h.21.mlp.c_proj.scales": "model-00003-of-00005.safetensors",
|
| 402 |
+
"transformer.h.21.mlp.w1.bias": "model-00003-of-00005.safetensors",
|
| 403 |
+
"transformer.h.21.mlp.w1.g_idx": "model-00003-of-00005.safetensors",
|
| 404 |
+
"transformer.h.21.mlp.w1.qweight": "model-00003-of-00005.safetensors",
|
| 405 |
+
"transformer.h.21.mlp.w1.qzeros": "model-00003-of-00005.safetensors",
|
| 406 |
+
"transformer.h.21.mlp.w1.scales": "model-00003-of-00005.safetensors",
|
| 407 |
+
"transformer.h.21.mlp.w2.bias": "model-00003-of-00005.safetensors",
|
| 408 |
+
"transformer.h.21.mlp.w2.g_idx": "model-00003-of-00005.safetensors",
|
| 409 |
+
"transformer.h.21.mlp.w2.qweight": "model-00003-of-00005.safetensors",
|
| 410 |
+
"transformer.h.21.mlp.w2.qzeros": "model-00003-of-00005.safetensors",
|
| 411 |
+
"transformer.h.21.mlp.w2.scales": "model-00003-of-00005.safetensors",
|
| 412 |
+
"transformer.h.22.attn.c_attn.bias": "model-00003-of-00005.safetensors",
|
| 413 |
+
"transformer.h.22.attn.c_attn.g_idx": "model-00003-of-00005.safetensors",
|
| 414 |
+
"transformer.h.22.attn.c_attn.qweight": "model-00003-of-00005.safetensors",
|
| 415 |
+
"transformer.h.22.attn.c_attn.qzeros": "model-00003-of-00005.safetensors",
|
| 416 |
+
"transformer.h.22.attn.c_attn.scales": "model-00003-of-00005.safetensors",
|
| 417 |
+
"transformer.h.22.attn.c_proj.bias": "model-00003-of-00005.safetensors",
|
| 418 |
+
"transformer.h.22.attn.c_proj.g_idx": "model-00003-of-00005.safetensors",
|
| 419 |
+
"transformer.h.22.attn.c_proj.qweight": "model-00003-of-00005.safetensors",
|
| 420 |
+
"transformer.h.22.attn.c_proj.qzeros": "model-00003-of-00005.safetensors",
|
| 421 |
+
"transformer.h.22.attn.c_proj.scales": "model-00003-of-00005.safetensors",
|
| 422 |
+
"transformer.h.22.ln_1.weight": "model-00003-of-00005.safetensors",
|
| 423 |
+
"transformer.h.22.ln_2.weight": "model-00003-of-00005.safetensors",
|
| 424 |
+
"transformer.h.22.mlp.c_proj.bias": "model-00003-of-00005.safetensors",
|
| 425 |
+
"transformer.h.22.mlp.c_proj.g_idx": "model-00003-of-00005.safetensors",
|
| 426 |
+
"transformer.h.22.mlp.c_proj.qweight": "model-00003-of-00005.safetensors",
|
| 427 |
+
"transformer.h.22.mlp.c_proj.qzeros": "model-00003-of-00005.safetensors",
|
| 428 |
+
"transformer.h.22.mlp.c_proj.scales": "model-00003-of-00005.safetensors",
|
| 429 |
+
"transformer.h.22.mlp.w1.bias": "model-00003-of-00005.safetensors",
|
| 430 |
+
"transformer.h.22.mlp.w1.g_idx": "model-00003-of-00005.safetensors",
|
| 431 |
+
"transformer.h.22.mlp.w1.qweight": "model-00003-of-00005.safetensors",
|
| 432 |
+
"transformer.h.22.mlp.w1.qzeros": "model-00003-of-00005.safetensors",
|
| 433 |
+
"transformer.h.22.mlp.w1.scales": "model-00003-of-00005.safetensors",
|
| 434 |
+
"transformer.h.22.mlp.w2.bias": "model-00003-of-00005.safetensors",
|
| 435 |
+
"transformer.h.22.mlp.w2.g_idx": "model-00003-of-00005.safetensors",
|
| 436 |
+
"transformer.h.22.mlp.w2.qweight": "model-00003-of-00005.safetensors",
|
| 437 |
+
"transformer.h.22.mlp.w2.qzeros": "model-00003-of-00005.safetensors",
|
| 438 |
+
"transformer.h.22.mlp.w2.scales": "model-00003-of-00005.safetensors",
|
| 439 |
+
"transformer.h.23.attn.c_attn.bias": "model-00003-of-00005.safetensors",
|
| 440 |
+
"transformer.h.23.attn.c_attn.g_idx": "model-00003-of-00005.safetensors",
|
| 441 |
+
"transformer.h.23.attn.c_attn.qweight": "model-00003-of-00005.safetensors",
|
| 442 |
+
"transformer.h.23.attn.c_attn.qzeros": "model-00003-of-00005.safetensors",
|
| 443 |
+
"transformer.h.23.attn.c_attn.scales": "model-00003-of-00005.safetensors",
|
| 444 |
+
"transformer.h.23.attn.c_proj.bias": "model-00003-of-00005.safetensors",
|
| 445 |
+
"transformer.h.23.attn.c_proj.g_idx": "model-00003-of-00005.safetensors",
|
| 446 |
+
"transformer.h.23.attn.c_proj.qweight": "model-00003-of-00005.safetensors",
|
| 447 |
+
"transformer.h.23.attn.c_proj.qzeros": "model-00003-of-00005.safetensors",
|
| 448 |
+
"transformer.h.23.attn.c_proj.scales": "model-00003-of-00005.safetensors",
|
| 449 |
+
"transformer.h.23.ln_1.weight": "model-00003-of-00005.safetensors",
|
| 450 |
+
"transformer.h.23.ln_2.weight": "model-00003-of-00005.safetensors",
|
| 451 |
+
"transformer.h.23.mlp.c_proj.bias": "model-00004-of-00005.safetensors",
|
| 452 |
+
"transformer.h.23.mlp.c_proj.g_idx": "model-00004-of-00005.safetensors",
|
| 453 |
+
"transformer.h.23.mlp.c_proj.qweight": "model-00004-of-00005.safetensors",
|
| 454 |
+
"transformer.h.23.mlp.c_proj.qzeros": "model-00004-of-00005.safetensors",
|
| 455 |
+
"transformer.h.23.mlp.c_proj.scales": "model-00004-of-00005.safetensors",
|
| 456 |
+
"transformer.h.23.mlp.w1.bias": "model-00004-of-00005.safetensors",
|
| 457 |
+
"transformer.h.23.mlp.w1.g_idx": "model-00004-of-00005.safetensors",
|
| 458 |
+
"transformer.h.23.mlp.w1.qweight": "model-00004-of-00005.safetensors",
|
| 459 |
+
"transformer.h.23.mlp.w1.qzeros": "model-00004-of-00005.safetensors",
|
| 460 |
+
"transformer.h.23.mlp.w1.scales": "model-00004-of-00005.safetensors",
|
| 461 |
+
"transformer.h.23.mlp.w2.bias": "model-00004-of-00005.safetensors",
|
| 462 |
+
"transformer.h.23.mlp.w2.g_idx": "model-00004-of-00005.safetensors",
|
| 463 |
+
"transformer.h.23.mlp.w2.qweight": "model-00004-of-00005.safetensors",
|
| 464 |
+
"transformer.h.23.mlp.w2.qzeros": "model-00004-of-00005.safetensors",
|
| 465 |
+
"transformer.h.23.mlp.w2.scales": "model-00004-of-00005.safetensors",
|
| 466 |
+
"transformer.h.24.attn.c_attn.bias": "model-00004-of-00005.safetensors",
|
| 467 |
+
"transformer.h.24.attn.c_attn.g_idx": "model-00004-of-00005.safetensors",
|
| 468 |
+
"transformer.h.24.attn.c_attn.qweight": "model-00004-of-00005.safetensors",
|
| 469 |
+
"transformer.h.24.attn.c_attn.qzeros": "model-00004-of-00005.safetensors",
|
| 470 |
+
"transformer.h.24.attn.c_attn.scales": "model-00004-of-00005.safetensors",
|
| 471 |
+
"transformer.h.24.attn.c_proj.bias": "model-00004-of-00005.safetensors",
|
| 472 |
+
"transformer.h.24.attn.c_proj.g_idx": "model-00004-of-00005.safetensors",
|
| 473 |
+
"transformer.h.24.attn.c_proj.qweight": "model-00004-of-00005.safetensors",
|
| 474 |
+
"transformer.h.24.attn.c_proj.qzeros": "model-00004-of-00005.safetensors",
|
| 475 |
+
"transformer.h.24.attn.c_proj.scales": "model-00004-of-00005.safetensors",
|
| 476 |
+
"transformer.h.24.ln_1.weight": "model-00004-of-00005.safetensors",
|
| 477 |
+
"transformer.h.24.ln_2.weight": "model-00004-of-00005.safetensors",
|
| 478 |
+
"transformer.h.24.mlp.c_proj.bias": "model-00004-of-00005.safetensors",
|
| 479 |
+
"transformer.h.24.mlp.c_proj.g_idx": "model-00004-of-00005.safetensors",
|
| 480 |
+
"transformer.h.24.mlp.c_proj.qweight": "model-00004-of-00005.safetensors",
|
| 481 |
+
"transformer.h.24.mlp.c_proj.qzeros": "model-00004-of-00005.safetensors",
|
| 482 |
+
"transformer.h.24.mlp.c_proj.scales": "model-00004-of-00005.safetensors",
|
| 483 |
+
"transformer.h.24.mlp.w1.bias": "model-00004-of-00005.safetensors",
|
| 484 |
+
"transformer.h.24.mlp.w1.g_idx": "model-00004-of-00005.safetensors",
|
| 485 |
+
"transformer.h.24.mlp.w1.qweight": "model-00004-of-00005.safetensors",
|
| 486 |
+
"transformer.h.24.mlp.w1.qzeros": "model-00004-of-00005.safetensors",
|
| 487 |
+
"transformer.h.24.mlp.w1.scales": "model-00004-of-00005.safetensors",
|
| 488 |
+
"transformer.h.24.mlp.w2.bias": "model-00004-of-00005.safetensors",
|
| 489 |
+
"transformer.h.24.mlp.w2.g_idx": "model-00004-of-00005.safetensors",
|
| 490 |
+
"transformer.h.24.mlp.w2.qweight": "model-00004-of-00005.safetensors",
|
| 491 |
+
"transformer.h.24.mlp.w2.qzeros": "model-00004-of-00005.safetensors",
|
| 492 |
+
"transformer.h.24.mlp.w2.scales": "model-00004-of-00005.safetensors",
|
| 493 |
+
"transformer.h.25.attn.c_attn.bias": "model-00004-of-00005.safetensors",
|
| 494 |
+
"transformer.h.25.attn.c_attn.g_idx": "model-00004-of-00005.safetensors",
|
| 495 |
+
"transformer.h.25.attn.c_attn.qweight": "model-00004-of-00005.safetensors",
|
| 496 |
+
"transformer.h.25.attn.c_attn.qzeros": "model-00004-of-00005.safetensors",
|
| 497 |
+
"transformer.h.25.attn.c_attn.scales": "model-00004-of-00005.safetensors",
|
| 498 |
+
"transformer.h.25.attn.c_proj.bias": "model-00004-of-00005.safetensors",
|
| 499 |
+
"transformer.h.25.attn.c_proj.g_idx": "model-00004-of-00005.safetensors",
|
| 500 |
+
"transformer.h.25.attn.c_proj.qweight": "model-00004-of-00005.safetensors",
|
| 501 |
+
"transformer.h.25.attn.c_proj.qzeros": "model-00004-of-00005.safetensors",
|
| 502 |
+
"transformer.h.25.attn.c_proj.scales": "model-00004-of-00005.safetensors",
|
| 503 |
+
"transformer.h.25.ln_1.weight": "model-00004-of-00005.safetensors",
|
| 504 |
+
"transformer.h.25.ln_2.weight": "model-00004-of-00005.safetensors",
|
| 505 |
+
"transformer.h.25.mlp.c_proj.bias": "model-00004-of-00005.safetensors",
|
| 506 |
+
"transformer.h.25.mlp.c_proj.g_idx": "model-00004-of-00005.safetensors",
|
| 507 |
+
"transformer.h.25.mlp.c_proj.qweight": "model-00004-of-00005.safetensors",
|
| 508 |
+
"transformer.h.25.mlp.c_proj.qzeros": "model-00004-of-00005.safetensors",
|
| 509 |
+
"transformer.h.25.mlp.c_proj.scales": "model-00004-of-00005.safetensors",
|
| 510 |
+
"transformer.h.25.mlp.w1.bias": "model-00004-of-00005.safetensors",
|
| 511 |
+
"transformer.h.25.mlp.w1.g_idx": "model-00004-of-00005.safetensors",
|
| 512 |
+
"transformer.h.25.mlp.w1.qweight": "model-00004-of-00005.safetensors",
|
| 513 |
+
"transformer.h.25.mlp.w1.qzeros": "model-00004-of-00005.safetensors",
|
| 514 |
+
"transformer.h.25.mlp.w1.scales": "model-00004-of-00005.safetensors",
|
| 515 |
+
"transformer.h.25.mlp.w2.bias": "model-00004-of-00005.safetensors",
|
| 516 |
+
"transformer.h.25.mlp.w2.g_idx": "model-00004-of-00005.safetensors",
|
| 517 |
+
"transformer.h.25.mlp.w2.qweight": "model-00004-of-00005.safetensors",
|
| 518 |
+
"transformer.h.25.mlp.w2.qzeros": "model-00004-of-00005.safetensors",
|
| 519 |
+
"transformer.h.25.mlp.w2.scales": "model-00004-of-00005.safetensors",
|
| 520 |
+
"transformer.h.26.attn.c_attn.bias": "model-00004-of-00005.safetensors",
|
| 521 |
+
"transformer.h.26.attn.c_attn.g_idx": "model-00004-of-00005.safetensors",
|
| 522 |
+
"transformer.h.26.attn.c_attn.qweight": "model-00004-of-00005.safetensors",
|
| 523 |
+
"transformer.h.26.attn.c_attn.qzeros": "model-00004-of-00005.safetensors",
|
| 524 |
+
"transformer.h.26.attn.c_attn.scales": "model-00004-of-00005.safetensors",
|
| 525 |
+
"transformer.h.26.attn.c_proj.bias": "model-00004-of-00005.safetensors",
|
| 526 |
+
"transformer.h.26.attn.c_proj.g_idx": "model-00004-of-00005.safetensors",
|
| 527 |
+
"transformer.h.26.attn.c_proj.qweight": "model-00004-of-00005.safetensors",
|
| 528 |
+
"transformer.h.26.attn.c_proj.qzeros": "model-00004-of-00005.safetensors",
|
| 529 |
+
"transformer.h.26.attn.c_proj.scales": "model-00004-of-00005.safetensors",
|
| 530 |
+
"transformer.h.26.ln_1.weight": "model-00004-of-00005.safetensors",
|
| 531 |
+
"transformer.h.26.ln_2.weight": "model-00004-of-00005.safetensors",
|
| 532 |
+
"transformer.h.26.mlp.c_proj.bias": "model-00004-of-00005.safetensors",
|
| 533 |
+
"transformer.h.26.mlp.c_proj.g_idx": "model-00004-of-00005.safetensors",
|
| 534 |
+
"transformer.h.26.mlp.c_proj.qweight": "model-00004-of-00005.safetensors",
|
| 535 |
+
"transformer.h.26.mlp.c_proj.qzeros": "model-00004-of-00005.safetensors",
|
| 536 |
+
"transformer.h.26.mlp.c_proj.scales": "model-00004-of-00005.safetensors",
|
| 537 |
+
"transformer.h.26.mlp.w1.bias": "model-00004-of-00005.safetensors",
|
| 538 |
+
"transformer.h.26.mlp.w1.g_idx": "model-00004-of-00005.safetensors",
|
| 539 |
+
"transformer.h.26.mlp.w1.qweight": "model-00004-of-00005.safetensors",
|
| 540 |
+
"transformer.h.26.mlp.w1.qzeros": "model-00004-of-00005.safetensors",
|
| 541 |
+
"transformer.h.26.mlp.w1.scales": "model-00004-of-00005.safetensors",
|
| 542 |
+
"transformer.h.26.mlp.w2.bias": "model-00004-of-00005.safetensors",
|
| 543 |
+
"transformer.h.26.mlp.w2.g_idx": "model-00004-of-00005.safetensors",
|
| 544 |
+
"transformer.h.26.mlp.w2.qweight": "model-00004-of-00005.safetensors",
|
| 545 |
+
"transformer.h.26.mlp.w2.qzeros": "model-00004-of-00005.safetensors",
|
| 546 |
+
"transformer.h.26.mlp.w2.scales": "model-00004-of-00005.safetensors",
|
| 547 |
+
"transformer.h.27.attn.c_attn.bias": "model-00004-of-00005.safetensors",
|
| 548 |
+
"transformer.h.27.attn.c_attn.g_idx": "model-00004-of-00005.safetensors",
|
| 549 |
+
"transformer.h.27.attn.c_attn.qweight": "model-00004-of-00005.safetensors",
|
| 550 |
+
"transformer.h.27.attn.c_attn.qzeros": "model-00004-of-00005.safetensors",
|
| 551 |
+
"transformer.h.27.attn.c_attn.scales": "model-00004-of-00005.safetensors",
|
| 552 |
+
"transformer.h.27.attn.c_proj.bias": "model-00004-of-00005.safetensors",
|
| 553 |
+
"transformer.h.27.attn.c_proj.g_idx": "model-00004-of-00005.safetensors",
|
| 554 |
+
"transformer.h.27.attn.c_proj.qweight": "model-00004-of-00005.safetensors",
|
| 555 |
+
"transformer.h.27.attn.c_proj.qzeros": "model-00004-of-00005.safetensors",
|
| 556 |
+
"transformer.h.27.attn.c_proj.scales": "model-00004-of-00005.safetensors",
|
| 557 |
+
"transformer.h.27.ln_1.weight": "model-00004-of-00005.safetensors",
|
| 558 |
+
"transformer.h.27.ln_2.weight": "model-00004-of-00005.safetensors",
|
| 559 |
+
"transformer.h.27.mlp.c_proj.bias": "model-00004-of-00005.safetensors",
|
| 560 |
+
"transformer.h.27.mlp.c_proj.g_idx": "model-00004-of-00005.safetensors",
|
| 561 |
+
"transformer.h.27.mlp.c_proj.qweight": "model-00004-of-00005.safetensors",
|
| 562 |
+
"transformer.h.27.mlp.c_proj.qzeros": "model-00004-of-00005.safetensors",
|
| 563 |
+
"transformer.h.27.mlp.c_proj.scales": "model-00004-of-00005.safetensors",
|
| 564 |
+
"transformer.h.27.mlp.w1.bias": "model-00004-of-00005.safetensors",
|
| 565 |
+
"transformer.h.27.mlp.w1.g_idx": "model-00004-of-00005.safetensors",
|
| 566 |
+
"transformer.h.27.mlp.w1.qweight": "model-00004-of-00005.safetensors",
|
| 567 |
+
"transformer.h.27.mlp.w1.qzeros": "model-00004-of-00005.safetensors",
|
| 568 |
+
"transformer.h.27.mlp.w1.scales": "model-00004-of-00005.safetensors",
|
| 569 |
+
"transformer.h.27.mlp.w2.bias": "model-00004-of-00005.safetensors",
|
| 570 |
+
"transformer.h.27.mlp.w2.g_idx": "model-00004-of-00005.safetensors",
|
| 571 |
+
"transformer.h.27.mlp.w2.qweight": "model-00004-of-00005.safetensors",
|
| 572 |
+
"transformer.h.27.mlp.w2.qzeros": "model-00004-of-00005.safetensors",
|
| 573 |
+
"transformer.h.27.mlp.w2.scales": "model-00004-of-00005.safetensors",
|
| 574 |
+
"transformer.h.28.attn.c_attn.bias": "model-00004-of-00005.safetensors",
|
| 575 |
+
"transformer.h.28.attn.c_attn.g_idx": "model-00004-of-00005.safetensors",
|
| 576 |
+
"transformer.h.28.attn.c_attn.qweight": "model-00004-of-00005.safetensors",
|
| 577 |
+
"transformer.h.28.attn.c_attn.qzeros": "model-00004-of-00005.safetensors",
|
| 578 |
+
"transformer.h.28.attn.c_attn.scales": "model-00004-of-00005.safetensors",
|
| 579 |
+
"transformer.h.28.attn.c_proj.bias": "model-00004-of-00005.safetensors",
|
| 580 |
+
"transformer.h.28.attn.c_proj.g_idx": "model-00004-of-00005.safetensors",
|
| 581 |
+
"transformer.h.28.attn.c_proj.qweight": "model-00004-of-00005.safetensors",
|
| 582 |
+
"transformer.h.28.attn.c_proj.qzeros": "model-00004-of-00005.safetensors",
|
| 583 |
+
"transformer.h.28.attn.c_proj.scales": "model-00004-of-00005.safetensors",
|
| 584 |
+
"transformer.h.28.ln_1.weight": "model-00004-of-00005.safetensors",
|
| 585 |
+
"transformer.h.28.ln_2.weight": "model-00004-of-00005.safetensors",
|
| 586 |
+
"transformer.h.28.mlp.c_proj.bias": "model-00004-of-00005.safetensors",
|
| 587 |
+
"transformer.h.28.mlp.c_proj.g_idx": "model-00004-of-00005.safetensors",
|
| 588 |
+
"transformer.h.28.mlp.c_proj.qweight": "model-00004-of-00005.safetensors",
|
| 589 |
+
"transformer.h.28.mlp.c_proj.qzeros": "model-00004-of-00005.safetensors",
|
| 590 |
+
"transformer.h.28.mlp.c_proj.scales": "model-00004-of-00005.safetensors",
|
| 591 |
+
"transformer.h.28.mlp.w1.bias": "model-00004-of-00005.safetensors",
|
| 592 |
+
"transformer.h.28.mlp.w1.g_idx": "model-00004-of-00005.safetensors",
|
| 593 |
+
"transformer.h.28.mlp.w1.qweight": "model-00004-of-00005.safetensors",
|
| 594 |
+
"transformer.h.28.mlp.w1.qzeros": "model-00004-of-00005.safetensors",
|
| 595 |
+
"transformer.h.28.mlp.w1.scales": "model-00004-of-00005.safetensors",
|
| 596 |
+
"transformer.h.28.mlp.w2.bias": "model-00004-of-00005.safetensors",
|
| 597 |
+
"transformer.h.28.mlp.w2.g_idx": "model-00004-of-00005.safetensors",
|
| 598 |
+
"transformer.h.28.mlp.w2.qweight": "model-00004-of-00005.safetensors",
|
| 599 |
+
"transformer.h.28.mlp.w2.qzeros": "model-00004-of-00005.safetensors",
|
| 600 |
+
"transformer.h.28.mlp.w2.scales": "model-00004-of-00005.safetensors",
|
| 601 |
+
"transformer.h.29.attn.c_attn.bias": "model-00004-of-00005.safetensors",
|
| 602 |
+
"transformer.h.29.attn.c_attn.g_idx": "model-00004-of-00005.safetensors",
|
| 603 |
+
"transformer.h.29.attn.c_attn.qweight": "model-00004-of-00005.safetensors",
|
| 604 |
+
"transformer.h.29.attn.c_attn.qzeros": "model-00004-of-00005.safetensors",
|
| 605 |
+
"transformer.h.29.attn.c_attn.scales": "model-00004-of-00005.safetensors",
|
| 606 |
+
"transformer.h.29.attn.c_proj.bias": "model-00004-of-00005.safetensors",
|
| 607 |
+
"transformer.h.29.attn.c_proj.g_idx": "model-00004-of-00005.safetensors",
|
| 608 |
+
"transformer.h.29.attn.c_proj.qweight": "model-00004-of-00005.safetensors",
|
| 609 |
+
"transformer.h.29.attn.c_proj.qzeros": "model-00004-of-00005.safetensors",
|
| 610 |
+
"transformer.h.29.attn.c_proj.scales": "model-00004-of-00005.safetensors",
|
| 611 |
+
"transformer.h.29.ln_1.weight": "model-00004-of-00005.safetensors",
|
| 612 |
+
"transformer.h.29.ln_2.weight": "model-00004-of-00005.safetensors",
|
| 613 |
+
"transformer.h.29.mlp.c_proj.bias": "model-00004-of-00005.safetensors",
|
| 614 |
+
"transformer.h.29.mlp.c_proj.g_idx": "model-00004-of-00005.safetensors",
|
| 615 |
+
"transformer.h.29.mlp.c_proj.qweight": "model-00004-of-00005.safetensors",
|
| 616 |
+
"transformer.h.29.mlp.c_proj.qzeros": "model-00004-of-00005.safetensors",
|
| 617 |
+
"transformer.h.29.mlp.c_proj.scales": "model-00004-of-00005.safetensors",
|
| 618 |
+
"transformer.h.29.mlp.w1.bias": "model-00004-of-00005.safetensors",
|
| 619 |
+
"transformer.h.29.mlp.w1.g_idx": "model-00004-of-00005.safetensors",
|
| 620 |
+
"transformer.h.29.mlp.w1.qweight": "model-00004-of-00005.safetensors",
|
| 621 |
+
"transformer.h.29.mlp.w1.qzeros": "model-00004-of-00005.safetensors",
|
| 622 |
+
"transformer.h.29.mlp.w1.scales": "model-00004-of-00005.safetensors",
|
| 623 |
+
"transformer.h.29.mlp.w2.bias": "model-00004-of-00005.safetensors",
|
| 624 |
+
"transformer.h.29.mlp.w2.g_idx": "model-00004-of-00005.safetensors",
|
| 625 |
+
"transformer.h.29.mlp.w2.qweight": "model-00004-of-00005.safetensors",
|
| 626 |
+
"transformer.h.29.mlp.w2.qzeros": "model-00004-of-00005.safetensors",
|
| 627 |
+
"transformer.h.29.mlp.w2.scales": "model-00004-of-00005.safetensors",
|
| 628 |
+
"transformer.h.3.attn.c_attn.bias": "model-00001-of-00005.safetensors",
|
| 629 |
+
"transformer.h.3.attn.c_attn.g_idx": "model-00001-of-00005.safetensors",
|
| 630 |
+
"transformer.h.3.attn.c_attn.qweight": "model-00001-of-00005.safetensors",
|
| 631 |
+
"transformer.h.3.attn.c_attn.qzeros": "model-00001-of-00005.safetensors",
|
| 632 |
+
"transformer.h.3.attn.c_attn.scales": "model-00001-of-00005.safetensors",
|
| 633 |
+
"transformer.h.3.attn.c_proj.bias": "model-00001-of-00005.safetensors",
|
| 634 |
+
"transformer.h.3.attn.c_proj.g_idx": "model-00001-of-00005.safetensors",
|
| 635 |
+
"transformer.h.3.attn.c_proj.qweight": "model-00001-of-00005.safetensors",
|
| 636 |
+
"transformer.h.3.attn.c_proj.qzeros": "model-00001-of-00005.safetensors",
|
| 637 |
+
"transformer.h.3.attn.c_proj.scales": "model-00001-of-00005.safetensors",
|
| 638 |
+
"transformer.h.3.ln_1.weight": "model-00001-of-00005.safetensors",
|
| 639 |
+
"transformer.h.3.ln_2.weight": "model-00001-of-00005.safetensors",
|
| 640 |
+
"transformer.h.3.mlp.c_proj.bias": "model-00001-of-00005.safetensors",
|
| 641 |
+
"transformer.h.3.mlp.c_proj.g_idx": "model-00001-of-00005.safetensors",
|
| 642 |
+
"transformer.h.3.mlp.c_proj.qweight": "model-00001-of-00005.safetensors",
|
| 643 |
+
"transformer.h.3.mlp.c_proj.qzeros": "model-00001-of-00005.safetensors",
|
| 644 |
+
"transformer.h.3.mlp.c_proj.scales": "model-00001-of-00005.safetensors",
|
| 645 |
+
"transformer.h.3.mlp.w1.bias": "model-00001-of-00005.safetensors",
|
| 646 |
+
"transformer.h.3.mlp.w1.g_idx": "model-00001-of-00005.safetensors",
|
| 647 |
+
"transformer.h.3.mlp.w1.qweight": "model-00001-of-00005.safetensors",
|
| 648 |
+
"transformer.h.3.mlp.w1.qzeros": "model-00001-of-00005.safetensors",
|
| 649 |
+
"transformer.h.3.mlp.w1.scales": "model-00001-of-00005.safetensors",
|
| 650 |
+
"transformer.h.3.mlp.w2.bias": "model-00002-of-00005.safetensors",
|
| 651 |
+
"transformer.h.3.mlp.w2.g_idx": "model-00002-of-00005.safetensors",
|
| 652 |
+
"transformer.h.3.mlp.w2.qweight": "model-00002-of-00005.safetensors",
|
| 653 |
+
"transformer.h.3.mlp.w2.qzeros": "model-00002-of-00005.safetensors",
|
| 654 |
+
"transformer.h.3.mlp.w2.scales": "model-00002-of-00005.safetensors",
|
| 655 |
+
"transformer.h.30.attn.c_attn.bias": "model-00004-of-00005.safetensors",
|
| 656 |
+
"transformer.h.30.attn.c_attn.g_idx": "model-00004-of-00005.safetensors",
|
| 657 |
+
"transformer.h.30.attn.c_attn.qweight": "model-00004-of-00005.safetensors",
|
| 658 |
+
"transformer.h.30.attn.c_attn.qzeros": "model-00004-of-00005.safetensors",
|
| 659 |
+
"transformer.h.30.attn.c_attn.scales": "model-00004-of-00005.safetensors",
|
| 660 |
+
"transformer.h.30.attn.c_proj.bias": "model-00004-of-00005.safetensors",
|
| 661 |
+
"transformer.h.30.attn.c_proj.g_idx": "model-00004-of-00005.safetensors",
|
| 662 |
+
"transformer.h.30.attn.c_proj.qweight": "model-00004-of-00005.safetensors",
|
| 663 |
+
"transformer.h.30.attn.c_proj.qzeros": "model-00004-of-00005.safetensors",
|
| 664 |
+
"transformer.h.30.attn.c_proj.scales": "model-00004-of-00005.safetensors",
|
| 665 |
+
"transformer.h.30.ln_1.weight": "model-00004-of-00005.safetensors",
|
| 666 |
+
"transformer.h.30.ln_2.weight": "model-00004-of-00005.safetensors",
|
| 667 |
+
"transformer.h.30.mlp.c_proj.bias": "model-00004-of-00005.safetensors",
|
| 668 |
+
"transformer.h.30.mlp.c_proj.g_idx": "model-00004-of-00005.safetensors",
|
| 669 |
+
"transformer.h.30.mlp.c_proj.qweight": "model-00004-of-00005.safetensors",
|
| 670 |
+
"transformer.h.30.mlp.c_proj.qzeros": "model-00004-of-00005.safetensors",
|
| 671 |
+
"transformer.h.30.mlp.c_proj.scales": "model-00004-of-00005.safetensors",
|
| 672 |
+
"transformer.h.30.mlp.w1.bias": "model-00004-of-00005.safetensors",
|
| 673 |
+
"transformer.h.30.mlp.w1.g_idx": "model-00004-of-00005.safetensors",
|
| 674 |
+
"transformer.h.30.mlp.w1.qweight": "model-00004-of-00005.safetensors",
|
| 675 |
+
"transformer.h.30.mlp.w1.qzeros": "model-00004-of-00005.safetensors",
|
| 676 |
+
"transformer.h.30.mlp.w1.scales": "model-00004-of-00005.safetensors",
|
| 677 |
+
"transformer.h.30.mlp.w2.bias": "model-00004-of-00005.safetensors",
|
| 678 |
+
"transformer.h.30.mlp.w2.g_idx": "model-00004-of-00005.safetensors",
|
| 679 |
+
"transformer.h.30.mlp.w2.qweight": "model-00004-of-00005.safetensors",
|
| 680 |
+
"transformer.h.30.mlp.w2.qzeros": "model-00004-of-00005.safetensors",
|
| 681 |
+
"transformer.h.30.mlp.w2.scales": "model-00004-of-00005.safetensors",
|
| 682 |
+
"transformer.h.31.attn.c_attn.bias": "model-00004-of-00005.safetensors",
|
| 683 |
+
"transformer.h.31.attn.c_attn.g_idx": "model-00004-of-00005.safetensors",
|
| 684 |
+
"transformer.h.31.attn.c_attn.qweight": "model-00004-of-00005.safetensors",
|
| 685 |
+
"transformer.h.31.attn.c_attn.qzeros": "model-00004-of-00005.safetensors",
|
| 686 |
+
"transformer.h.31.attn.c_attn.scales": "model-00004-of-00005.safetensors",
|
| 687 |
+
"transformer.h.31.attn.c_proj.bias": "model-00004-of-00005.safetensors",
|
| 688 |
+
"transformer.h.31.attn.c_proj.g_idx": "model-00004-of-00005.safetensors",
|
| 689 |
+
"transformer.h.31.attn.c_proj.qweight": "model-00004-of-00005.safetensors",
|
| 690 |
+
"transformer.h.31.attn.c_proj.qzeros": "model-00004-of-00005.safetensors",
|
| 691 |
+
"transformer.h.31.attn.c_proj.scales": "model-00004-of-00005.safetensors",
|
| 692 |
+
"transformer.h.31.ln_1.weight": "model-00004-of-00005.safetensors",
|
| 693 |
+
"transformer.h.31.ln_2.weight": "model-00004-of-00005.safetensors",
|
| 694 |
+
"transformer.h.31.mlp.c_proj.bias": "model-00004-of-00005.safetensors",
|
| 695 |
+
"transformer.h.31.mlp.c_proj.g_idx": "model-00004-of-00005.safetensors",
|
| 696 |
+
"transformer.h.31.mlp.c_proj.qweight": "model-00004-of-00005.safetensors",
|
| 697 |
+
"transformer.h.31.mlp.c_proj.qzeros": "model-00004-of-00005.safetensors",
|
| 698 |
+
"transformer.h.31.mlp.c_proj.scales": "model-00004-of-00005.safetensors",
|
| 699 |
+
"transformer.h.31.mlp.w1.bias": "model-00004-of-00005.safetensors",
|
| 700 |
+
"transformer.h.31.mlp.w1.g_idx": "model-00004-of-00005.safetensors",
|
| 701 |
+
"transformer.h.31.mlp.w1.qweight": "model-00004-of-00005.safetensors",
|
| 702 |
+
"transformer.h.31.mlp.w1.qzeros": "model-00004-of-00005.safetensors",
|
| 703 |
+
"transformer.h.31.mlp.w1.scales": "model-00004-of-00005.safetensors",
|
| 704 |
+
"transformer.h.31.mlp.w2.bias": "model-00004-of-00005.safetensors",
|
| 705 |
+
"transformer.h.31.mlp.w2.g_idx": "model-00004-of-00005.safetensors",
|
| 706 |
+
"transformer.h.31.mlp.w2.qweight": "model-00004-of-00005.safetensors",
|
| 707 |
+
"transformer.h.31.mlp.w2.qzeros": "model-00004-of-00005.safetensors",
|
| 708 |
+
"transformer.h.31.mlp.w2.scales": "model-00004-of-00005.safetensors",
|
| 709 |
+
"transformer.h.4.attn.c_attn.bias": "model-00002-of-00005.safetensors",
|
| 710 |
+
"transformer.h.4.attn.c_attn.g_idx": "model-00002-of-00005.safetensors",
|
| 711 |
+
"transformer.h.4.attn.c_attn.qweight": "model-00002-of-00005.safetensors",
|
| 712 |
+
"transformer.h.4.attn.c_attn.qzeros": "model-00002-of-00005.safetensors",
|
| 713 |
+
"transformer.h.4.attn.c_attn.scales": "model-00002-of-00005.safetensors",
|
| 714 |
+
"transformer.h.4.attn.c_proj.bias": "model-00002-of-00005.safetensors",
|
| 715 |
+
"transformer.h.4.attn.c_proj.g_idx": "model-00002-of-00005.safetensors",
|
| 716 |
+
"transformer.h.4.attn.c_proj.qweight": "model-00002-of-00005.safetensors",
|
| 717 |
+
"transformer.h.4.attn.c_proj.qzeros": "model-00002-of-00005.safetensors",
|
| 718 |
+
"transformer.h.4.attn.c_proj.scales": "model-00002-of-00005.safetensors",
|
| 719 |
+
"transformer.h.4.ln_1.weight": "model-00002-of-00005.safetensors",
|
| 720 |
+
"transformer.h.4.ln_2.weight": "model-00002-of-00005.safetensors",
|
| 721 |
+
"transformer.h.4.mlp.c_proj.bias": "model-00002-of-00005.safetensors",
|
| 722 |
+
"transformer.h.4.mlp.c_proj.g_idx": "model-00002-of-00005.safetensors",
|
| 723 |
+
"transformer.h.4.mlp.c_proj.qweight": "model-00002-of-00005.safetensors",
|
| 724 |
+
"transformer.h.4.mlp.c_proj.qzeros": "model-00002-of-00005.safetensors",
|
| 725 |
+
"transformer.h.4.mlp.c_proj.scales": "model-00002-of-00005.safetensors",
|
| 726 |
+
"transformer.h.4.mlp.w1.bias": "model-00002-of-00005.safetensors",
|
| 727 |
+
"transformer.h.4.mlp.w1.g_idx": "model-00002-of-00005.safetensors",
|
| 728 |
+
"transformer.h.4.mlp.w1.qweight": "model-00002-of-00005.safetensors",
|
| 729 |
+
"transformer.h.4.mlp.w1.qzeros": "model-00002-of-00005.safetensors",
|
| 730 |
+
"transformer.h.4.mlp.w1.scales": "model-00002-of-00005.safetensors",
|
| 731 |
+
"transformer.h.4.mlp.w2.bias": "model-00002-of-00005.safetensors",
|
| 732 |
+
"transformer.h.4.mlp.w2.g_idx": "model-00002-of-00005.safetensors",
|
| 733 |
+
"transformer.h.4.mlp.w2.qweight": "model-00002-of-00005.safetensors",
|
| 734 |
+
"transformer.h.4.mlp.w2.qzeros": "model-00002-of-00005.safetensors",
|
| 735 |
+
"transformer.h.4.mlp.w2.scales": "model-00002-of-00005.safetensors",
|
| 736 |
+
"transformer.h.5.attn.c_attn.bias": "model-00002-of-00005.safetensors",
|
| 737 |
+
"transformer.h.5.attn.c_attn.g_idx": "model-00002-of-00005.safetensors",
|
| 738 |
+
"transformer.h.5.attn.c_attn.qweight": "model-00002-of-00005.safetensors",
|
| 739 |
+
"transformer.h.5.attn.c_attn.qzeros": "model-00002-of-00005.safetensors",
|
| 740 |
+
"transformer.h.5.attn.c_attn.scales": "model-00002-of-00005.safetensors",
|
| 741 |
+
"transformer.h.5.attn.c_proj.bias": "model-00002-of-00005.safetensors",
|
| 742 |
+
"transformer.h.5.attn.c_proj.g_idx": "model-00002-of-00005.safetensors",
|
| 743 |
+
"transformer.h.5.attn.c_proj.qweight": "model-00002-of-00005.safetensors",
|
| 744 |
+
"transformer.h.5.attn.c_proj.qzeros": "model-00002-of-00005.safetensors",
|
| 745 |
+
"transformer.h.5.attn.c_proj.scales": "model-00002-of-00005.safetensors",
|
| 746 |
+
"transformer.h.5.ln_1.weight": "model-00002-of-00005.safetensors",
|
| 747 |
+
"transformer.h.5.ln_2.weight": "model-00002-of-00005.safetensors",
|
| 748 |
+
"transformer.h.5.mlp.c_proj.bias": "model-00002-of-00005.safetensors",
|
| 749 |
+
"transformer.h.5.mlp.c_proj.g_idx": "model-00002-of-00005.safetensors",
|
| 750 |
+
"transformer.h.5.mlp.c_proj.qweight": "model-00002-of-00005.safetensors",
|
| 751 |
+
"transformer.h.5.mlp.c_proj.qzeros": "model-00002-of-00005.safetensors",
|
| 752 |
+
"transformer.h.5.mlp.c_proj.scales": "model-00002-of-00005.safetensors",
|
| 753 |
+
"transformer.h.5.mlp.w1.bias": "model-00002-of-00005.safetensors",
|
| 754 |
+
"transformer.h.5.mlp.w1.g_idx": "model-00002-of-00005.safetensors",
|
| 755 |
+
"transformer.h.5.mlp.w1.qweight": "model-00002-of-00005.safetensors",
|
| 756 |
+
"transformer.h.5.mlp.w1.qzeros": "model-00002-of-00005.safetensors",
|
| 757 |
+
"transformer.h.5.mlp.w1.scales": "model-00002-of-00005.safetensors",
|
| 758 |
+
"transformer.h.5.mlp.w2.bias": "model-00002-of-00005.safetensors",
|
| 759 |
+
"transformer.h.5.mlp.w2.g_idx": "model-00002-of-00005.safetensors",
|
| 760 |
+
"transformer.h.5.mlp.w2.qweight": "model-00002-of-00005.safetensors",
|
| 761 |
+
"transformer.h.5.mlp.w2.qzeros": "model-00002-of-00005.safetensors",
|
| 762 |
+
"transformer.h.5.mlp.w2.scales": "model-00002-of-00005.safetensors",
|
| 763 |
+
"transformer.h.6.attn.c_attn.bias": "model-00002-of-00005.safetensors",
|
| 764 |
+
"transformer.h.6.attn.c_attn.g_idx": "model-00002-of-00005.safetensors",
|
| 765 |
+
"transformer.h.6.attn.c_attn.qweight": "model-00002-of-00005.safetensors",
|
| 766 |
+
"transformer.h.6.attn.c_attn.qzeros": "model-00002-of-00005.safetensors",
|
| 767 |
+
"transformer.h.6.attn.c_attn.scales": "model-00002-of-00005.safetensors",
|
| 768 |
+
"transformer.h.6.attn.c_proj.bias": "model-00002-of-00005.safetensors",
|
| 769 |
+
"transformer.h.6.attn.c_proj.g_idx": "model-00002-of-00005.safetensors",
|
| 770 |
+
"transformer.h.6.attn.c_proj.qweight": "model-00002-of-00005.safetensors",
|
| 771 |
+
"transformer.h.6.attn.c_proj.qzeros": "model-00002-of-00005.safetensors",
|
| 772 |
+
"transformer.h.6.attn.c_proj.scales": "model-00002-of-00005.safetensors",
|
| 773 |
+
"transformer.h.6.ln_1.weight": "model-00002-of-00005.safetensors",
|
| 774 |
+
"transformer.h.6.ln_2.weight": "model-00002-of-00005.safetensors",
|
| 775 |
+
"transformer.h.6.mlp.c_proj.bias": "model-00002-of-00005.safetensors",
|
| 776 |
+
"transformer.h.6.mlp.c_proj.g_idx": "model-00002-of-00005.safetensors",
|
| 777 |
+
"transformer.h.6.mlp.c_proj.qweight": "model-00002-of-00005.safetensors",
|
| 778 |
+
"transformer.h.6.mlp.c_proj.qzeros": "model-00002-of-00005.safetensors",
|
| 779 |
+
"transformer.h.6.mlp.c_proj.scales": "model-00002-of-00005.safetensors",
|
| 780 |
+
"transformer.h.6.mlp.w1.bias": "model-00002-of-00005.safetensors",
|
| 781 |
+
"transformer.h.6.mlp.w1.g_idx": "model-00002-of-00005.safetensors",
|
| 782 |
+
"transformer.h.6.mlp.w1.qweight": "model-00002-of-00005.safetensors",
|
| 783 |
+
"transformer.h.6.mlp.w1.qzeros": "model-00002-of-00005.safetensors",
|
| 784 |
+
"transformer.h.6.mlp.w1.scales": "model-00002-of-00005.safetensors",
|
| 785 |
+
"transformer.h.6.mlp.w2.bias": "model-00002-of-00005.safetensors",
|
| 786 |
+
"transformer.h.6.mlp.w2.g_idx": "model-00002-of-00005.safetensors",
|
| 787 |
+
"transformer.h.6.mlp.w2.qweight": "model-00002-of-00005.safetensors",
|
| 788 |
+
"transformer.h.6.mlp.w2.qzeros": "model-00002-of-00005.safetensors",
|
| 789 |
+
"transformer.h.6.mlp.w2.scales": "model-00002-of-00005.safetensors",
|
| 790 |
+
"transformer.h.7.attn.c_attn.bias": "model-00002-of-00005.safetensors",
|
| 791 |
+
"transformer.h.7.attn.c_attn.g_idx": "model-00002-of-00005.safetensors",
|
| 792 |
+
"transformer.h.7.attn.c_attn.qweight": "model-00002-of-00005.safetensors",
|
| 793 |
+
"transformer.h.7.attn.c_attn.qzeros": "model-00002-of-00005.safetensors",
|
| 794 |
+
"transformer.h.7.attn.c_attn.scales": "model-00002-of-00005.safetensors",
|
| 795 |
+
"transformer.h.7.attn.c_proj.bias": "model-00002-of-00005.safetensors",
|
| 796 |
+
"transformer.h.7.attn.c_proj.g_idx": "model-00002-of-00005.safetensors",
|
| 797 |
+
"transformer.h.7.attn.c_proj.qweight": "model-00002-of-00005.safetensors",
|
| 798 |
+
"transformer.h.7.attn.c_proj.qzeros": "model-00002-of-00005.safetensors",
|
| 799 |
+
"transformer.h.7.attn.c_proj.scales": "model-00002-of-00005.safetensors",
|
| 800 |
+
"transformer.h.7.ln_1.weight": "model-00002-of-00005.safetensors",
|
| 801 |
+
"transformer.h.7.ln_2.weight": "model-00002-of-00005.safetensors",
|
| 802 |
+
"transformer.h.7.mlp.c_proj.bias": "model-00002-of-00005.safetensors",
|
| 803 |
+
"transformer.h.7.mlp.c_proj.g_idx": "model-00002-of-00005.safetensors",
|
| 804 |
+
"transformer.h.7.mlp.c_proj.qweight": "model-00002-of-00005.safetensors",
|
| 805 |
+
"transformer.h.7.mlp.c_proj.qzeros": "model-00002-of-00005.safetensors",
|
| 806 |
+
"transformer.h.7.mlp.c_proj.scales": "model-00002-of-00005.safetensors",
|
| 807 |
+
"transformer.h.7.mlp.w1.bias": "model-00002-of-00005.safetensors",
|
| 808 |
+
"transformer.h.7.mlp.w1.g_idx": "model-00002-of-00005.safetensors",
|
| 809 |
+
"transformer.h.7.mlp.w1.qweight": "model-00002-of-00005.safetensors",
|
| 810 |
+
"transformer.h.7.mlp.w1.qzeros": "model-00002-of-00005.safetensors",
|
| 811 |
+
"transformer.h.7.mlp.w1.scales": "model-00002-of-00005.safetensors",
|
| 812 |
+
"transformer.h.7.mlp.w2.bias": "model-00002-of-00005.safetensors",
|
| 813 |
+
"transformer.h.7.mlp.w2.g_idx": "model-00002-of-00005.safetensors",
|
| 814 |
+
"transformer.h.7.mlp.w2.qweight": "model-00002-of-00005.safetensors",
|
| 815 |
+
"transformer.h.7.mlp.w2.qzeros": "model-00002-of-00005.safetensors",
|
| 816 |
+
"transformer.h.7.mlp.w2.scales": "model-00002-of-00005.safetensors",
|
| 817 |
+
"transformer.h.8.attn.c_attn.bias": "model-00002-of-00005.safetensors",
|
| 818 |
+
"transformer.h.8.attn.c_attn.g_idx": "model-00002-of-00005.safetensors",
|
| 819 |
+
"transformer.h.8.attn.c_attn.qweight": "model-00002-of-00005.safetensors",
|
| 820 |
+
"transformer.h.8.attn.c_attn.qzeros": "model-00002-of-00005.safetensors",
|
| 821 |
+
"transformer.h.8.attn.c_attn.scales": "model-00002-of-00005.safetensors",
|
| 822 |
+
"transformer.h.8.attn.c_proj.bias": "model-00002-of-00005.safetensors",
|
| 823 |
+
"transformer.h.8.attn.c_proj.g_idx": "model-00002-of-00005.safetensors",
|
| 824 |
+
"transformer.h.8.attn.c_proj.qweight": "model-00002-of-00005.safetensors",
|
| 825 |
+
"transformer.h.8.attn.c_proj.qzeros": "model-00002-of-00005.safetensors",
|
| 826 |
+
"transformer.h.8.attn.c_proj.scales": "model-00002-of-00005.safetensors",
|
| 827 |
+
"transformer.h.8.ln_1.weight": "model-00002-of-00005.safetensors",
|
| 828 |
+
"transformer.h.8.ln_2.weight": "model-00002-of-00005.safetensors",
|
| 829 |
+
"transformer.h.8.mlp.c_proj.bias": "model-00002-of-00005.safetensors",
|
| 830 |
+
"transformer.h.8.mlp.c_proj.g_idx": "model-00002-of-00005.safetensors",
|
| 831 |
+
"transformer.h.8.mlp.c_proj.qweight": "model-00002-of-00005.safetensors",
|
| 832 |
+
"transformer.h.8.mlp.c_proj.qzeros": "model-00002-of-00005.safetensors",
|
| 833 |
+
"transformer.h.8.mlp.c_proj.scales": "model-00002-of-00005.safetensors",
|
| 834 |
+
"transformer.h.8.mlp.w1.bias": "model-00002-of-00005.safetensors",
|
| 835 |
+
"transformer.h.8.mlp.w1.g_idx": "model-00002-of-00005.safetensors",
|
| 836 |
+
"transformer.h.8.mlp.w1.qweight": "model-00002-of-00005.safetensors",
|
| 837 |
+
"transformer.h.8.mlp.w1.qzeros": "model-00002-of-00005.safetensors",
|
| 838 |
+
"transformer.h.8.mlp.w1.scales": "model-00002-of-00005.safetensors",
|
| 839 |
+
"transformer.h.8.mlp.w2.bias": "model-00002-of-00005.safetensors",
|
| 840 |
+
"transformer.h.8.mlp.w2.g_idx": "model-00002-of-00005.safetensors",
|
| 841 |
+
"transformer.h.8.mlp.w2.qweight": "model-00002-of-00005.safetensors",
|
| 842 |
+
"transformer.h.8.mlp.w2.qzeros": "model-00002-of-00005.safetensors",
|
| 843 |
+
"transformer.h.8.mlp.w2.scales": "model-00002-of-00005.safetensors",
|
| 844 |
+
"transformer.h.9.attn.c_attn.bias": "model-00002-of-00005.safetensors",
|
| 845 |
+
"transformer.h.9.attn.c_attn.g_idx": "model-00002-of-00005.safetensors",
|
| 846 |
+
"transformer.h.9.attn.c_attn.qweight": "model-00002-of-00005.safetensors",
|
| 847 |
+
"transformer.h.9.attn.c_attn.qzeros": "model-00002-of-00005.safetensors",
|
| 848 |
+
"transformer.h.9.attn.c_attn.scales": "model-00002-of-00005.safetensors",
|
| 849 |
+
"transformer.h.9.attn.c_proj.bias": "model-00002-of-00005.safetensors",
|
| 850 |
+
"transformer.h.9.attn.c_proj.g_idx": "model-00002-of-00005.safetensors",
|
| 851 |
+
"transformer.h.9.attn.c_proj.qweight": "model-00002-of-00005.safetensors",
|
| 852 |
+
"transformer.h.9.attn.c_proj.qzeros": "model-00002-of-00005.safetensors",
|
| 853 |
+
"transformer.h.9.attn.c_proj.scales": "model-00002-of-00005.safetensors",
|
| 854 |
+
"transformer.h.9.ln_1.weight": "model-00002-of-00005.safetensors",
|
| 855 |
+
"transformer.h.9.ln_2.weight": "model-00002-of-00005.safetensors",
|
| 856 |
+
"transformer.h.9.mlp.c_proj.bias": "model-00002-of-00005.safetensors",
|
| 857 |
+
"transformer.h.9.mlp.c_proj.g_idx": "model-00002-of-00005.safetensors",
|
| 858 |
+
"transformer.h.9.mlp.c_proj.qweight": "model-00002-of-00005.safetensors",
|
| 859 |
+
"transformer.h.9.mlp.c_proj.qzeros": "model-00002-of-00005.safetensors",
|
| 860 |
+
"transformer.h.9.mlp.c_proj.scales": "model-00002-of-00005.safetensors",
|
| 861 |
+
"transformer.h.9.mlp.w1.bias": "model-00002-of-00005.safetensors",
|
| 862 |
+
"transformer.h.9.mlp.w1.g_idx": "model-00002-of-00005.safetensors",
|
| 863 |
+
"transformer.h.9.mlp.w1.qweight": "model-00002-of-00005.safetensors",
|
| 864 |
+
"transformer.h.9.mlp.w1.qzeros": "model-00002-of-00005.safetensors",
|
| 865 |
+
"transformer.h.9.mlp.w1.scales": "model-00002-of-00005.safetensors",
|
| 866 |
+
"transformer.h.9.mlp.w2.bias": "model-00002-of-00005.safetensors",
|
| 867 |
+
"transformer.h.9.mlp.w2.g_idx": "model-00002-of-00005.safetensors",
|
| 868 |
+
"transformer.h.9.mlp.w2.qweight": "model-00002-of-00005.safetensors",
|
| 869 |
+
"transformer.h.9.mlp.w2.qzeros": "model-00002-of-00005.safetensors",
|
| 870 |
+
"transformer.h.9.mlp.w2.scales": "model-00002-of-00005.safetensors",
|
| 871 |
+
"transformer.ln_f.weight": "model-00004-of-00005.safetensors",
|
| 872 |
+
"transformer.wte.weight": "model-00001-of-00005.safetensors"
|
| 873 |
+
}
|
| 874 |
+
}
|
modeling_qwen.py
ADDED
|
@@ -0,0 +1,1416 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Alibaba Cloud.
|
| 2 |
+
#
|
| 3 |
+
# This source code is licensed under the license found in the
|
| 4 |
+
# LICENSE file in the root directory of this source tree.
|
| 5 |
+
|
| 6 |
+
import importlib
|
| 7 |
+
import math
|
| 8 |
+
from typing import TYPE_CHECKING, Optional, Tuple, Union, Callable, List, Any, Generator
|
| 9 |
+
|
| 10 |
+
import torch
|
| 11 |
+
import torch.nn.functional as F
|
| 12 |
+
import torch.utils.checkpoint
|
| 13 |
+
from torch.cuda.amp import autocast
|
| 14 |
+
|
| 15 |
+
from torch.nn import CrossEntropyLoss
|
| 16 |
+
from transformers import PreTrainedTokenizer, GenerationConfig, StoppingCriteriaList
|
| 17 |
+
from transformers.generation.logits_process import LogitsProcessorList
|
| 18 |
+
|
| 19 |
+
if TYPE_CHECKING:
|
| 20 |
+
from transformers.generation.streamers import BaseStreamer
|
| 21 |
+
from transformers.generation.utils import GenerateOutput
|
| 22 |
+
from transformers.modeling_outputs import (
|
| 23 |
+
BaseModelOutputWithPast,
|
| 24 |
+
CausalLMOutputWithPast,
|
| 25 |
+
)
|
| 26 |
+
from transformers.modeling_utils import PreTrainedModel
|
| 27 |
+
from transformers.utils import logging
|
| 28 |
+
|
| 29 |
+
try:
|
| 30 |
+
from einops import rearrange
|
| 31 |
+
except ImportError:
|
| 32 |
+
rearrange = None
|
| 33 |
+
from torch import nn
|
| 34 |
+
|
| 35 |
+
SUPPORT_CUDA = torch.cuda.is_available()
|
| 36 |
+
SUPPORT_BF16 = SUPPORT_CUDA and torch.cuda.is_bf16_supported()
|
| 37 |
+
SUPPORT_FP16 = SUPPORT_CUDA and torch.cuda.get_device_capability(0)[0] >= 7
|
| 38 |
+
|
| 39 |
+
from .configuration_qwen import QWenConfig
|
| 40 |
+
from .qwen_generation_utils import (
|
| 41 |
+
HistoryType,
|
| 42 |
+
make_context,
|
| 43 |
+
decode_tokens,
|
| 44 |
+
get_stop_words_ids,
|
| 45 |
+
StopWordsLogitsProcessor,
|
| 46 |
+
)
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
logger = logging.get_logger(__name__)
|
| 50 |
+
|
| 51 |
+
_CHECKPOINT_FOR_DOC = "qwen"
|
| 52 |
+
_CONFIG_FOR_DOC = "QWenConfig"
|
| 53 |
+
|
| 54 |
+
QWen_PRETRAINED_MODEL_ARCHIVE_LIST = ["qwen-7b"]
|
| 55 |
+
|
| 56 |
+
_ERROR_BAD_CHAT_FORMAT = """\
|
| 57 |
+
We detect you are probably using the pretrained model (rather than chat model) for chatting, since the chat_format in generation_config is not "chatml".
|
| 58 |
+
If you are directly using the model downloaded from Huggingface, please make sure you are using our "Qwen/Qwen-7B-Chat" Huggingface model (rather than "Qwen/Qwen-7B") when you call model.chat().
|
| 59 |
+
我们检测到您可能在使用预训练模型(而非chat模型)进行多轮chat,因为您当前在generation_config指定的chat_format,并未设置为我们在对话中所支持的"chatml"格式。
|
| 60 |
+
如果您在直接使用我们从Huggingface提供的模型,请确保您在调用model.chat()时,使用的是"Qwen/Qwen-7B-Chat"模型(而非"Qwen/Qwen-7B"预训练模型)。
|
| 61 |
+
"""
|
| 62 |
+
|
| 63 |
+
_SENTINEL = object()
|
| 64 |
+
_ERROR_STREAM_IN_CHAT = """\
|
| 65 |
+
Pass argument `stream` to model.chat() is buggy, deprecated, and marked for removal. Please use model.chat_stream(...) instead of model.chat(..., stream=True).
|
| 66 |
+
向model.chat()传入参数stream的用法可能存在Bug,该用法已被废弃,将在未来被移除。请使用model.chat_stream(...)代替model.chat(..., stream=True)。
|
| 67 |
+
"""
|
| 68 |
+
|
| 69 |
+
_ERROR_INPUT_CPU_QUERY_WITH_FLASH_ATTN_ACTIVATED = """\
|
| 70 |
+
We detect you have activated flash attention support, but running model computation on CPU. Please make sure that your input data has been placed on GPU. If you actually want to run CPU computation, please following the readme and set device_map="cpu" to disable flash attention when loading the model (calling AutoModelForCausalLM.from_pretrained).
|
| 71 |
+
检测到您的模型已激活了flash attention支持,但正在执行CPU运算任务。如使用flash attention,请您确认模型输入已经传到GPU上。如果您确认要执行CPU运算,请您在载入模型(调用AutoModelForCausalLM.from_pretrained)时,按照readme说法,指定device_map="cpu"以禁用flash attention。
|
| 72 |
+
"""
|
| 73 |
+
|
| 74 |
+
apply_rotary_emb_func = None
|
| 75 |
+
rms_norm = None
|
| 76 |
+
flash_attn_unpadded_func = None
|
| 77 |
+
|
| 78 |
+
def _import_flash_attn():
|
| 79 |
+
global apply_rotary_emb_func, rms_norm, flash_attn_unpadded_func
|
| 80 |
+
try:
|
| 81 |
+
from flash_attn.layers.rotary import apply_rotary_emb_func as __apply_rotary_emb_func
|
| 82 |
+
apply_rotary_emb_func = __apply_rotary_emb_func
|
| 83 |
+
except ImportError:
|
| 84 |
+
logger.warn(
|
| 85 |
+
"Warning: import flash_attn rotary fail, please install FlashAttention rotary to get higher efficiency "
|
| 86 |
+
"https://github.com/Dao-AILab/flash-attention/tree/main/csrc/rotary"
|
| 87 |
+
)
|
| 88 |
+
|
| 89 |
+
try:
|
| 90 |
+
from flash_attn.ops.rms_norm import rms_norm as __rms_norm
|
| 91 |
+
rms_norm = __rms_norm
|
| 92 |
+
except ImportError:
|
| 93 |
+
logger.warn(
|
| 94 |
+
"Warning: import flash_attn rms_norm fail, please install FlashAttention layer_norm to get higher efficiency "
|
| 95 |
+
"https://github.com/Dao-AILab/flash-attention/tree/main/csrc/layer_norm"
|
| 96 |
+
)
|
| 97 |
+
|
| 98 |
+
try:
|
| 99 |
+
import flash_attn
|
| 100 |
+
if not hasattr(flash_attn, '__version__'):
|
| 101 |
+
from flash_attn.flash_attn_interface import flash_attn_unpadded_func as __flash_attn_unpadded_func
|
| 102 |
+
else:
|
| 103 |
+
if int(flash_attn.__version__.split(".")[0]) >= 2:
|
| 104 |
+
from flash_attn.flash_attn_interface import flash_attn_varlen_func as __flash_attn_unpadded_func
|
| 105 |
+
else:
|
| 106 |
+
from flash_attn.flash_attn_interface import flash_attn_unpadded_func as __flash_attn_unpadded_func
|
| 107 |
+
flash_attn_unpadded_func = __flash_attn_unpadded_func
|
| 108 |
+
except ImportError:
|
| 109 |
+
logger.warn(
|
| 110 |
+
"Warning: import flash_attn fail, please install FlashAttention to get higher efficiency "
|
| 111 |
+
"https://github.com/Dao-AILab/flash-attention"
|
| 112 |
+
)
|
| 113 |
+
|
| 114 |
+
def quantize_cache_v(fdata, bits, qmax, qmin):
|
| 115 |
+
# b, s, head, h-dim->b, head, s, h-dim
|
| 116 |
+
qtype = torch.uint8
|
| 117 |
+
device = fdata.device
|
| 118 |
+
shape = fdata.shape
|
| 119 |
+
|
| 120 |
+
fdata_cal = torch.flatten(fdata, 2)
|
| 121 |
+
fmax = torch.amax(fdata_cal, dim=-1, keepdim=True)
|
| 122 |
+
fmin = torch.amin(fdata_cal, dim=-1, keepdim=True)
|
| 123 |
+
# Compute params
|
| 124 |
+
if qmax.device != fmax.device:
|
| 125 |
+
qmax = qmax.to(device)
|
| 126 |
+
qmin = qmin.to(device)
|
| 127 |
+
scale = (fmax - fmin) / (qmax - qmin)
|
| 128 |
+
zero = qmin - fmin / scale
|
| 129 |
+
scale = scale.unsqueeze(-1).repeat(1,1,shape[2],1).contiguous()
|
| 130 |
+
zero = zero.unsqueeze(-1).repeat(1,1,shape[2],1).contiguous()
|
| 131 |
+
# Quantize
|
| 132 |
+
res_data = fdata / scale + zero
|
| 133 |
+
qdata = torch.clamp(res_data, qmin, qmax).to(qtype)
|
| 134 |
+
return qdata.contiguous(), scale, zero
|
| 135 |
+
|
| 136 |
+
def dequantize_cache_torch(qdata, scale, zero):
|
| 137 |
+
data = scale * (qdata - zero)
|
| 138 |
+
return data
|
| 139 |
+
|
| 140 |
+
class FlashSelfAttention(torch.nn.Module):
|
| 141 |
+
def __init__(
|
| 142 |
+
self,
|
| 143 |
+
causal=False,
|
| 144 |
+
softmax_scale=None,
|
| 145 |
+
attention_dropout=0.0,
|
| 146 |
+
):
|
| 147 |
+
super().__init__()
|
| 148 |
+
assert flash_attn_unpadded_func is not None, (
|
| 149 |
+
"Please install FlashAttention first, " "e.g., with pip install flash-attn"
|
| 150 |
+
)
|
| 151 |
+
assert (
|
| 152 |
+
rearrange is not None
|
| 153 |
+
), "Please install einops first, e.g., with pip install einops"
|
| 154 |
+
self.causal = causal
|
| 155 |
+
self.softmax_scale = softmax_scale
|
| 156 |
+
self.dropout_p = attention_dropout
|
| 157 |
+
|
| 158 |
+
def unpad_input(self, hidden_states, attention_mask):
|
| 159 |
+
valid_mask = attention_mask.squeeze(1).squeeze(1).eq(0)
|
| 160 |
+
seqlens_in_batch = valid_mask.sum(dim=-1, dtype=torch.int32)
|
| 161 |
+
indices = torch.nonzero(valid_mask.flatten(), as_tuple=False).flatten()
|
| 162 |
+
max_seqlen_in_batch = seqlens_in_batch.max().item()
|
| 163 |
+
cu_seqlens = F.pad(torch.cumsum(seqlens_in_batch, dim=0, dtype=torch.torch.int32), (1, 0))
|
| 164 |
+
hidden_states = hidden_states[indices]
|
| 165 |
+
return hidden_states, indices, cu_seqlens, max_seqlen_in_batch
|
| 166 |
+
|
| 167 |
+
def pad_input(self, hidden_states, indices, batch, seqlen):
|
| 168 |
+
output = torch.zeros(batch * seqlen, *hidden_states.shape[1:], device=hidden_states.device,
|
| 169 |
+
dtype=hidden_states.dtype)
|
| 170 |
+
output[indices] = hidden_states
|
| 171 |
+
return rearrange(output, '(b s) ... -> b s ...', b=batch)
|
| 172 |
+
|
| 173 |
+
def forward(self, q, k, v, attention_mask=None):
|
| 174 |
+
assert all((i.dtype in [torch.float16, torch.bfloat16] for i in (q, k, v)))
|
| 175 |
+
assert all((i.is_cuda for i in (q, k, v)))
|
| 176 |
+
batch_size, seqlen_q = q.shape[0], q.shape[1]
|
| 177 |
+
seqlen_k = k.shape[1]
|
| 178 |
+
seqlen_out = seqlen_q
|
| 179 |
+
|
| 180 |
+
q, k, v = [rearrange(x, "b s ... -> (b s) ...") for x in [q, k, v]]
|
| 181 |
+
cu_seqlens_q = torch.arange(
|
| 182 |
+
0,
|
| 183 |
+
(batch_size + 1) * seqlen_q,
|
| 184 |
+
step=seqlen_q,
|
| 185 |
+
dtype=torch.int32,
|
| 186 |
+
device=q.device,
|
| 187 |
+
)
|
| 188 |
+
|
| 189 |
+
if attention_mask is not None:
|
| 190 |
+
k, indices_k, cu_seqlens_k, seqlen_k = self.unpad_input(k, attention_mask)
|
| 191 |
+
if q.size(0) == v.size(0):
|
| 192 |
+
q = q[indices_k]
|
| 193 |
+
cu_seqlens_q = cu_seqlens_k
|
| 194 |
+
seqlen_q = seqlen_k
|
| 195 |
+
v = v[indices_k]
|
| 196 |
+
else:
|
| 197 |
+
cu_seqlens_k = torch.arange(
|
| 198 |
+
0,
|
| 199 |
+
(batch_size + 1) * seqlen_k,
|
| 200 |
+
step=seqlen_k,
|
| 201 |
+
dtype=torch.int32,
|
| 202 |
+
device=q.device,
|
| 203 |
+
)
|
| 204 |
+
|
| 205 |
+
if self.training:
|
| 206 |
+
assert seqlen_k == seqlen_q
|
| 207 |
+
is_causal = self.causal
|
| 208 |
+
dropout_p = self.dropout_p
|
| 209 |
+
else:
|
| 210 |
+
is_causal = seqlen_q == seqlen_k
|
| 211 |
+
dropout_p = 0
|
| 212 |
+
|
| 213 |
+
output = flash_attn_unpadded_func(
|
| 214 |
+
q,
|
| 215 |
+
k,
|
| 216 |
+
v,
|
| 217 |
+
cu_seqlens_q,
|
| 218 |
+
cu_seqlens_k,
|
| 219 |
+
seqlen_q,
|
| 220 |
+
seqlen_k,
|
| 221 |
+
dropout_p,
|
| 222 |
+
softmax_scale=self.softmax_scale,
|
| 223 |
+
causal=is_causal,
|
| 224 |
+
)
|
| 225 |
+
if attention_mask is not None and seqlen_q == seqlen_k:
|
| 226 |
+
output = self.pad_input(output, indices_k, batch_size, seqlen_out)
|
| 227 |
+
else:
|
| 228 |
+
new_shape = (batch_size, output.shape[0] // batch_size) + output.shape[1:]
|
| 229 |
+
output = output.view(new_shape)
|
| 230 |
+
return output
|
| 231 |
+
|
| 232 |
+
|
| 233 |
+
class QWenAttention(nn.Module):
|
| 234 |
+
def __init__(self, config):
|
| 235 |
+
super().__init__()
|
| 236 |
+
|
| 237 |
+
self.register_buffer("masked_bias", torch.tensor(-1e4), persistent=False)
|
| 238 |
+
self.seq_length = config.seq_length
|
| 239 |
+
|
| 240 |
+
self.hidden_size = config.hidden_size
|
| 241 |
+
self.split_size = config.hidden_size
|
| 242 |
+
self.num_heads = config.num_attention_heads
|
| 243 |
+
self.head_dim = self.hidden_size // self.num_heads
|
| 244 |
+
|
| 245 |
+
self.use_flash_attn = config.use_flash_attn
|
| 246 |
+
self.scale_attn_weights = True
|
| 247 |
+
|
| 248 |
+
self.projection_size = config.kv_channels * config.num_attention_heads
|
| 249 |
+
|
| 250 |
+
assert self.projection_size % config.num_attention_heads == 0
|
| 251 |
+
self.hidden_size_per_attention_head = (
|
| 252 |
+
self.projection_size // config.num_attention_heads
|
| 253 |
+
)
|
| 254 |
+
|
| 255 |
+
self.c_attn = nn.Linear(config.hidden_size, 3 * self.projection_size)
|
| 256 |
+
|
| 257 |
+
self.c_proj = nn.Linear(
|
| 258 |
+
config.hidden_size, self.projection_size, bias=not config.no_bias
|
| 259 |
+
)
|
| 260 |
+
|
| 261 |
+
self.is_fp32 = not (config.bf16 or config.fp16)
|
| 262 |
+
if (
|
| 263 |
+
self.use_flash_attn
|
| 264 |
+
and flash_attn_unpadded_func is not None
|
| 265 |
+
and not self.is_fp32
|
| 266 |
+
):
|
| 267 |
+
self.core_attention_flash = FlashSelfAttention(
|
| 268 |
+
causal=True, attention_dropout=config.attn_dropout_prob
|
| 269 |
+
)
|
| 270 |
+
self.bf16 = config.bf16
|
| 271 |
+
|
| 272 |
+
self.use_dynamic_ntk = config.use_dynamic_ntk
|
| 273 |
+
self.use_logn_attn = config.use_logn_attn
|
| 274 |
+
|
| 275 |
+
logn_list = [
|
| 276 |
+
math.log(i, self.seq_length) if i > self.seq_length else 1
|
| 277 |
+
for i in range(1, 32768)
|
| 278 |
+
]
|
| 279 |
+
logn_tensor = torch.tensor(logn_list)[None, :, None, None]
|
| 280 |
+
self.register_buffer("logn_tensor", logn_tensor, persistent=False)
|
| 281 |
+
|
| 282 |
+
self.attn_dropout = nn.Dropout(config.attn_dropout_prob)
|
| 283 |
+
self.softmax_in_fp32 = config.softmax_in_fp32 if hasattr(config, 'softmax_in_fp32') else False
|
| 284 |
+
self.use_cache_quantization = config.use_cache_quantization if hasattr(config, 'use_cache_quantization') else False
|
| 285 |
+
self.use_cache_kernel = config.use_cache_kernel if hasattr(config,'use_cache_kernel') else False
|
| 286 |
+
cache_dtype = torch.float
|
| 287 |
+
if self.bf16:
|
| 288 |
+
cache_dtype=torch.bfloat16
|
| 289 |
+
elif config.fp16:
|
| 290 |
+
cache_dtype = torch.float16
|
| 291 |
+
self.cache_qmax = torch.tensor(torch.iinfo(torch.uint8).max, dtype=cache_dtype)
|
| 292 |
+
self.cache_qmin = torch.tensor(torch.iinfo(torch.uint8).min, dtype=cache_dtype)
|
| 293 |
+
|
| 294 |
+
if config.use_cache_quantization and config.use_cache_kernel:
|
| 295 |
+
from .cpp_kernels import cache_autogptq_cuda_256
|
| 296 |
+
try:
|
| 297 |
+
self.cache_kernels = cache_autogptq_cuda_256
|
| 298 |
+
except ImportError:
|
| 299 |
+
self.cache_kernels = None
|
| 300 |
+
|
| 301 |
+
def _attn(self, query, key, value, registered_causal_mask, attention_mask=None, head_mask=None):
|
| 302 |
+
device = query.device
|
| 303 |
+
if self.use_cache_quantization:
|
| 304 |
+
qk, qk_scale, qk_zero = key
|
| 305 |
+
if self.use_cache_kernel and self.cache_kernels is not None:
|
| 306 |
+
shape = query.shape[:-1] + (qk.shape[-2],)
|
| 307 |
+
attn_weights = torch.zeros(shape, dtype=torch.float16, device=device)
|
| 308 |
+
self.cache_kernels.vecquant8matmul_batched_faster_old(
|
| 309 |
+
query.contiguous() if query.dtype == torch.float16 else query.to(torch.float16).contiguous(),
|
| 310 |
+
qk.transpose(-1, -2).contiguous(),
|
| 311 |
+
attn_weights,
|
| 312 |
+
qk_scale.contiguous() if qk_scale.dtype == torch.float16 else qk_scale.to(torch.float16).contiguous(),
|
| 313 |
+
qk_zero.contiguous()if qk_zero.dtype == torch.float16 else qk_zero.to(torch.float16).contiguous())
|
| 314 |
+
# attn_weights = attn_weights.to(query.dtype).contiguous()
|
| 315 |
+
else:
|
| 316 |
+
key = dequantize_cache_torch(qk, qk_scale, qk_zero)
|
| 317 |
+
attn_weights = torch.matmul(query, key.transpose(-1, -2))
|
| 318 |
+
else:
|
| 319 |
+
attn_weights = torch.matmul(query, key.transpose(-1, -2))
|
| 320 |
+
|
| 321 |
+
if self.scale_attn_weights:
|
| 322 |
+
if self.use_cache_quantization:
|
| 323 |
+
size_temp = value[0].size(-1)
|
| 324 |
+
else:
|
| 325 |
+
size_temp = value.size(-1)
|
| 326 |
+
attn_weights = attn_weights / torch.full(
|
| 327 |
+
[],
|
| 328 |
+
size_temp ** 0.5,
|
| 329 |
+
dtype=attn_weights.dtype,
|
| 330 |
+
device=attn_weights.device,
|
| 331 |
+
)
|
| 332 |
+
if self.use_cache_quantization:
|
| 333 |
+
query_length, key_length = query.size(-2), key[0].size(-2)
|
| 334 |
+
else:
|
| 335 |
+
query_length, key_length = query.size(-2), key.size(-2)
|
| 336 |
+
causal_mask = registered_causal_mask[
|
| 337 |
+
:, :, key_length - query_length : key_length, :key_length
|
| 338 |
+
]
|
| 339 |
+
mask_value = torch.finfo(attn_weights.dtype).min
|
| 340 |
+
mask_value = torch.full([], mask_value, dtype=attn_weights.dtype).to(
|
| 341 |
+
attn_weights.device
|
| 342 |
+
)
|
| 343 |
+
attn_weights = torch.where(
|
| 344 |
+
causal_mask, attn_weights.to(attn_weights.dtype), mask_value
|
| 345 |
+
)
|
| 346 |
+
|
| 347 |
+
if attention_mask is not None:
|
| 348 |
+
attn_weights = attn_weights + attention_mask
|
| 349 |
+
|
| 350 |
+
if self.softmax_in_fp32:
|
| 351 |
+
attn_weights = nn.functional.softmax(attn_weights.float(), dim=-1)
|
| 352 |
+
else:
|
| 353 |
+
attn_weights = nn.functional.softmax(attn_weights, dim=-1)
|
| 354 |
+
|
| 355 |
+
attn_weights = attn_weights.type(query.dtype)
|
| 356 |
+
attn_weights = self.attn_dropout(attn_weights)
|
| 357 |
+
|
| 358 |
+
if head_mask is not None:
|
| 359 |
+
attn_weights = attn_weights * head_mask
|
| 360 |
+
|
| 361 |
+
if self.use_cache_quantization:
|
| 362 |
+
qv, qv_scale, qv_zero = value
|
| 363 |
+
if self.use_cache_kernel and self.cache_kernels is not None:
|
| 364 |
+
shape = attn_weights.shape[:-1] + (query.shape[-1],)
|
| 365 |
+
attn_output = torch.zeros(shape, dtype=torch.float16, device=device)
|
| 366 |
+
self.cache_kernels.vecquant8matmul_batched_column_compression_faster_old(
|
| 367 |
+
attn_weights.contiguous() if attn_weights.dtype == torch.float16 else attn_weights.to(torch.float16).contiguous(),
|
| 368 |
+
qv.contiguous(), # dtype: int32
|
| 369 |
+
attn_output,
|
| 370 |
+
qv_scale.contiguous() if qv_scale.dtype == torch.float16 else qv_scale.to(torch.float16).contiguous(),
|
| 371 |
+
qv_zero.contiguous() if qv_zero.dtype == torch.float16 else qv_zero.to(torch.float16).contiguous())
|
| 372 |
+
if attn_output.dtype != query.dtype:
|
| 373 |
+
attn_output = attn_output.to(query.dtype)
|
| 374 |
+
attn_weights = attn_weights.to(query.dtype)
|
| 375 |
+
else:
|
| 376 |
+
value = dequantize_cache_torch(qv, qv_scale, qv_zero)
|
| 377 |
+
attn_output = torch.matmul(attn_weights, value)
|
| 378 |
+
else:
|
| 379 |
+
attn_output = torch.matmul(attn_weights, value)
|
| 380 |
+
|
| 381 |
+
attn_output = attn_output.transpose(1, 2)
|
| 382 |
+
|
| 383 |
+
return attn_output, attn_weights
|
| 384 |
+
|
| 385 |
+
def _upcast_and_reordered_attn(
|
| 386 |
+
self, query, key, value, registered_causal_mask, attention_mask=None, head_mask=None
|
| 387 |
+
):
|
| 388 |
+
bsz, num_heads, q_seq_len, dk = query.size()
|
| 389 |
+
_, _, k_seq_len, _ = key.size()
|
| 390 |
+
|
| 391 |
+
attn_weights = torch.empty(
|
| 392 |
+
bsz * num_heads,
|
| 393 |
+
q_seq_len,
|
| 394 |
+
k_seq_len,
|
| 395 |
+
dtype=torch.float32,
|
| 396 |
+
device=query.device,
|
| 397 |
+
)
|
| 398 |
+
|
| 399 |
+
scale_factor = 1.0
|
| 400 |
+
if self.scale_attn_weights:
|
| 401 |
+
scale_factor /= float(value.size(-1)) ** 0.5
|
| 402 |
+
|
| 403 |
+
with autocast(enabled=False):
|
| 404 |
+
q, k = query.reshape(-1, q_seq_len, dk), key.transpose(-1, -2).reshape(
|
| 405 |
+
-1, dk, k_seq_len
|
| 406 |
+
)
|
| 407 |
+
attn_weights = torch.baddbmm(
|
| 408 |
+
attn_weights, q.float(), k.float(), beta=0, alpha=scale_factor
|
| 409 |
+
)
|
| 410 |
+
attn_weights = attn_weights.reshape(bsz, num_heads, q_seq_len, k_seq_len)
|
| 411 |
+
|
| 412 |
+
query_length, key_length = query.size(-2), key.size(-2)
|
| 413 |
+
causal_mask = registered_causal_mask[
|
| 414 |
+
:, :, key_length - query_length : key_length, :key_length
|
| 415 |
+
]
|
| 416 |
+
mask_value = torch.finfo(attn_weights.dtype).min
|
| 417 |
+
mask_value = torch.tensor(mask_value, dtype=attn_weights.dtype).to(
|
| 418 |
+
attn_weights.device
|
| 419 |
+
)
|
| 420 |
+
attn_weights = torch.where(causal_mask, attn_weights, mask_value)
|
| 421 |
+
|
| 422 |
+
if attention_mask is not None:
|
| 423 |
+
attn_weights = attn_weights + attention_mask
|
| 424 |
+
|
| 425 |
+
attn_weights = nn.functional.softmax(attn_weights, dim=-1)
|
| 426 |
+
|
| 427 |
+
if attn_weights.dtype != torch.float32:
|
| 428 |
+
raise RuntimeError(
|
| 429 |
+
"Error with upcasting, attn_weights does not have dtype torch.float32"
|
| 430 |
+
)
|
| 431 |
+
attn_weights = attn_weights.type(value.dtype)
|
| 432 |
+
attn_weights = self.attn_dropout(attn_weights)
|
| 433 |
+
|
| 434 |
+
if head_mask is not None:
|
| 435 |
+
attn_weights = attn_weights * head_mask
|
| 436 |
+
|
| 437 |
+
attn_output = torch.matmul(attn_weights, value)
|
| 438 |
+
|
| 439 |
+
return attn_output, attn_weights
|
| 440 |
+
|
| 441 |
+
def _split_heads(self, tensor, num_heads, attn_head_size):
|
| 442 |
+
new_shape = tensor.size()[:-1] + (num_heads, attn_head_size)
|
| 443 |
+
tensor = tensor.view(new_shape)
|
| 444 |
+
return tensor
|
| 445 |
+
|
| 446 |
+
def _merge_heads(self, tensor, num_heads, attn_head_size):
|
| 447 |
+
tensor = tensor.contiguous()
|
| 448 |
+
new_shape = tensor.size()[:-2] + (num_heads * attn_head_size,)
|
| 449 |
+
return tensor.view(new_shape)
|
| 450 |
+
|
| 451 |
+
def forward(
|
| 452 |
+
self,
|
| 453 |
+
hidden_states: Optional[Tuple[torch.FloatTensor]],
|
| 454 |
+
rotary_pos_emb_list: Optional[List[torch.Tensor]] = None,
|
| 455 |
+
registered_causal_mask: Optional[torch.Tensor] = None,
|
| 456 |
+
layer_past: Optional[Tuple[torch.Tensor]] = None,
|
| 457 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 458 |
+
head_mask: Optional[torch.FloatTensor] = None,
|
| 459 |
+
encoder_hidden_states: Optional[torch.Tensor] = None,
|
| 460 |
+
encoder_attention_mask: Optional[torch.FloatTensor] = None,
|
| 461 |
+
output_attentions: Optional[bool] = False,
|
| 462 |
+
use_cache: Optional[bool] = False,
|
| 463 |
+
):
|
| 464 |
+
mixed_x_layer = self.c_attn(hidden_states)
|
| 465 |
+
|
| 466 |
+
query, key, value = mixed_x_layer.split(self.split_size, dim=2)
|
| 467 |
+
|
| 468 |
+
query = self._split_heads(query, self.num_heads, self.head_dim)
|
| 469 |
+
key = self._split_heads(key, self.num_heads, self.head_dim)
|
| 470 |
+
value = self._split_heads(value, self.num_heads, self.head_dim)
|
| 471 |
+
|
| 472 |
+
if rotary_pos_emb_list is not None:
|
| 473 |
+
cur_len = query.shape[1]
|
| 474 |
+
if len(rotary_pos_emb_list) == 1:
|
| 475 |
+
rotary_pos_emb = rotary_pos_emb_list[0]
|
| 476 |
+
rotary_pos_emb = [i[:, -cur_len:, :, :] for i in rotary_pos_emb]
|
| 477 |
+
rotary_pos_emb = (rotary_pos_emb,) * 2
|
| 478 |
+
q_pos_emb, k_pos_emb = rotary_pos_emb
|
| 479 |
+
# Slice the pos emb for current inference
|
| 480 |
+
query = apply_rotary_pos_emb(query, q_pos_emb)
|
| 481 |
+
key = apply_rotary_pos_emb(key, k_pos_emb)
|
| 482 |
+
else:
|
| 483 |
+
query_list = []
|
| 484 |
+
key_list = []
|
| 485 |
+
for i, rotary_pos_emb in enumerate(rotary_pos_emb_list):
|
| 486 |
+
rotary_pos_emb = [i[:, -cur_len:, :, :] for i in rotary_pos_emb]
|
| 487 |
+
rotary_pos_emb = (rotary_pos_emb,) * 2
|
| 488 |
+
q_pos_emb, k_pos_emb = rotary_pos_emb
|
| 489 |
+
# Slice the pos emb for current inference
|
| 490 |
+
query_list += [apply_rotary_pos_emb(query[i:i+1, :, :], q_pos_emb)]
|
| 491 |
+
key_list += [apply_rotary_pos_emb(key[i:i+1, :, :], k_pos_emb)]
|
| 492 |
+
query = torch.cat(query_list, dim=0)
|
| 493 |
+
key = torch.cat(key_list, dim=0)
|
| 494 |
+
|
| 495 |
+
if self.use_cache_quantization:
|
| 496 |
+
key = quantize_cache_v(key.permute(0, 2, 1, 3),
|
| 497 |
+
bits=8,
|
| 498 |
+
qmin=self.cache_qmin,
|
| 499 |
+
qmax=self.cache_qmax)
|
| 500 |
+
value = quantize_cache_v(value.permute(0, 2, 1, 3),
|
| 501 |
+
bits=8,
|
| 502 |
+
qmin=self.cache_qmin,
|
| 503 |
+
qmax=self.cache_qmax)
|
| 504 |
+
|
| 505 |
+
|
| 506 |
+
if layer_past is not None:
|
| 507 |
+
past_key, past_value = layer_past[0], layer_past[1]
|
| 508 |
+
if self.use_cache_quantization:
|
| 509 |
+
# use_cache_quantization:
|
| 510 |
+
# present=((q_key,key_scale,key_zero_point),
|
| 511 |
+
# (q_value,value_scale,value_zero_point))
|
| 512 |
+
key = (torch.cat((past_key[0], key[0]), dim=2),
|
| 513 |
+
torch.cat((past_key[1], key[1]), dim=2),
|
| 514 |
+
torch.cat((past_key[2], key[2]), dim=2))
|
| 515 |
+
value = (torch.cat((past_value[0], value[0]), dim=2),
|
| 516 |
+
torch.cat((past_value[1], value[1]), dim=2),
|
| 517 |
+
torch.cat((past_value[2], value[2]), dim=2))
|
| 518 |
+
else:
|
| 519 |
+
# not use_cache_quantization:
|
| 520 |
+
# present=(key,value)
|
| 521 |
+
key = torch.cat((past_key, key), dim=1)
|
| 522 |
+
value = torch.cat((past_value, value), dim=1)
|
| 523 |
+
|
| 524 |
+
if use_cache:
|
| 525 |
+
present = (key, value)
|
| 526 |
+
else:
|
| 527 |
+
present = None
|
| 528 |
+
|
| 529 |
+
if self.use_logn_attn and not self.training:
|
| 530 |
+
if self.use_cache_quantization:
|
| 531 |
+
seq_start = key[0].size(2) - query.size(1)
|
| 532 |
+
seq_end = key[0].size(2)
|
| 533 |
+
else:
|
| 534 |
+
seq_start = key.size(1) - query.size(1)
|
| 535 |
+
seq_end = key.size(1)
|
| 536 |
+
logn_tensor = self.logn_tensor[:, seq_start:seq_end, :, :]
|
| 537 |
+
query = query * logn_tensor.expand_as(query)
|
| 538 |
+
|
| 539 |
+
if (
|
| 540 |
+
self.use_flash_attn
|
| 541 |
+
and flash_attn_unpadded_func is not None
|
| 542 |
+
and not self.is_fp32
|
| 543 |
+
and query.is_cuda
|
| 544 |
+
):
|
| 545 |
+
q, k, v = query, key, value
|
| 546 |
+
context_layer = self.core_attention_flash(q, k, v, attention_mask=attention_mask)
|
| 547 |
+
|
| 548 |
+
# b s h d -> b s (h d)
|
| 549 |
+
context_layer = context_layer.flatten(2,3).contiguous()
|
| 550 |
+
|
| 551 |
+
else:
|
| 552 |
+
query = query.permute(0, 2, 1, 3)
|
| 553 |
+
if not self.use_cache_quantization:
|
| 554 |
+
key = key.permute(0, 2, 1, 3)
|
| 555 |
+
value = value.permute(0, 2, 1, 3)
|
| 556 |
+
if (
|
| 557 |
+
registered_causal_mask is None
|
| 558 |
+
and self.use_flash_attn
|
| 559 |
+
and flash_attn_unpadded_func is not None
|
| 560 |
+
and not self.is_fp32
|
| 561 |
+
and not query.is_cuda
|
| 562 |
+
):
|
| 563 |
+
raise Exception(_ERROR_INPUT_CPU_QUERY_WITH_FLASH_ATTN_ACTIVATED)
|
| 564 |
+
attn_output, attn_weight = self._attn(
|
| 565 |
+
query, key, value, registered_causal_mask, attention_mask, head_mask
|
| 566 |
+
)
|
| 567 |
+
context_layer = self._merge_heads(
|
| 568 |
+
attn_output, self.num_heads, self.head_dim
|
| 569 |
+
)
|
| 570 |
+
|
| 571 |
+
attn_output = self.c_proj(context_layer)
|
| 572 |
+
|
| 573 |
+
outputs = (attn_output, present)
|
| 574 |
+
if output_attentions:
|
| 575 |
+
if (
|
| 576 |
+
self.use_flash_attn
|
| 577 |
+
and flash_attn_unpadded_func is not None
|
| 578 |
+
and not self.is_fp32
|
| 579 |
+
):
|
| 580 |
+
raise ValueError("Cannot output attentions while using flash-attn")
|
| 581 |
+
else:
|
| 582 |
+
outputs += (attn_weight,)
|
| 583 |
+
|
| 584 |
+
return outputs
|
| 585 |
+
|
| 586 |
+
|
| 587 |
+
class QWenMLP(nn.Module):
|
| 588 |
+
def __init__(self, config):
|
| 589 |
+
super().__init__()
|
| 590 |
+
self.w1 = nn.Linear(
|
| 591 |
+
config.hidden_size, config.intermediate_size // 2, bias=not config.no_bias
|
| 592 |
+
)
|
| 593 |
+
self.w2 = nn.Linear(
|
| 594 |
+
config.hidden_size, config.intermediate_size // 2, bias=not config.no_bias
|
| 595 |
+
)
|
| 596 |
+
ff_dim_in = config.intermediate_size // 2
|
| 597 |
+
self.c_proj = nn.Linear(ff_dim_in, config.hidden_size, bias=not config.no_bias)
|
| 598 |
+
|
| 599 |
+
def forward(self, hidden_states):
|
| 600 |
+
a1 = self.w1(hidden_states)
|
| 601 |
+
a2 = self.w2(hidden_states)
|
| 602 |
+
intermediate_parallel = a1 * F.silu(a2)
|
| 603 |
+
output = self.c_proj(intermediate_parallel)
|
| 604 |
+
return output
|
| 605 |
+
|
| 606 |
+
class QWenBlock(nn.Module):
|
| 607 |
+
def __init__(self, config):
|
| 608 |
+
super().__init__()
|
| 609 |
+
hidden_size = config.hidden_size
|
| 610 |
+
self.bf16 = config.bf16
|
| 611 |
+
|
| 612 |
+
self.ln_1 = RMSNorm(
|
| 613 |
+
hidden_size,
|
| 614 |
+
eps=config.layer_norm_epsilon,
|
| 615 |
+
)
|
| 616 |
+
self.attn = QWenAttention(config)
|
| 617 |
+
self.ln_2 = RMSNorm(
|
| 618 |
+
hidden_size,
|
| 619 |
+
eps=config.layer_norm_epsilon,
|
| 620 |
+
)
|
| 621 |
+
|
| 622 |
+
self.mlp = QWenMLP(config)
|
| 623 |
+
|
| 624 |
+
def forward(
|
| 625 |
+
self,
|
| 626 |
+
hidden_states: Optional[Tuple[torch.FloatTensor]],
|
| 627 |
+
rotary_pos_emb_list: Optional[List[torch.Tensor]] = None,
|
| 628 |
+
registered_causal_mask: Optional[torch.Tensor] = None,
|
| 629 |
+
layer_past: Optional[Tuple[torch.Tensor]] = None,
|
| 630 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 631 |
+
head_mask: Optional[torch.FloatTensor] = None,
|
| 632 |
+
encoder_hidden_states: Optional[torch.Tensor] = None,
|
| 633 |
+
encoder_attention_mask: Optional[torch.FloatTensor] = None,
|
| 634 |
+
use_cache: Optional[bool] = False,
|
| 635 |
+
output_attentions: Optional[bool] = False,
|
| 636 |
+
):
|
| 637 |
+
layernorm_output = self.ln_1(hidden_states)
|
| 638 |
+
|
| 639 |
+
attn_outputs = self.attn(
|
| 640 |
+
layernorm_output,
|
| 641 |
+
rotary_pos_emb_list,
|
| 642 |
+
registered_causal_mask=registered_causal_mask,
|
| 643 |
+
layer_past=layer_past,
|
| 644 |
+
attention_mask=attention_mask,
|
| 645 |
+
head_mask=head_mask,
|
| 646 |
+
use_cache=use_cache,
|
| 647 |
+
output_attentions=output_attentions,
|
| 648 |
+
)
|
| 649 |
+
attn_output = attn_outputs[0]
|
| 650 |
+
|
| 651 |
+
outputs = attn_outputs[1:]
|
| 652 |
+
|
| 653 |
+
residual = hidden_states
|
| 654 |
+
layernorm_input = attn_output + residual
|
| 655 |
+
|
| 656 |
+
layernorm_output = self.ln_2(layernorm_input)
|
| 657 |
+
|
| 658 |
+
residual = layernorm_input
|
| 659 |
+
mlp_output = self.mlp(layernorm_output)
|
| 660 |
+
hidden_states = residual + mlp_output
|
| 661 |
+
|
| 662 |
+
if use_cache:
|
| 663 |
+
outputs = (hidden_states,) + outputs
|
| 664 |
+
else:
|
| 665 |
+
outputs = (hidden_states,) + outputs[1:]
|
| 666 |
+
|
| 667 |
+
return outputs
|
| 668 |
+
|
| 669 |
+
|
| 670 |
+
class QWenPreTrainedModel(PreTrainedModel):
|
| 671 |
+
config_class = QWenConfig
|
| 672 |
+
base_model_prefix = "transformer"
|
| 673 |
+
is_parallelizable = False
|
| 674 |
+
supports_gradient_checkpointing = True
|
| 675 |
+
_no_split_modules = ["QWenBlock"]
|
| 676 |
+
|
| 677 |
+
def __init__(self, *inputs, **kwargs):
|
| 678 |
+
super().__init__(*inputs, **kwargs)
|
| 679 |
+
|
| 680 |
+
def _init_weights(self, module):
|
| 681 |
+
"""Initialize the weights."""
|
| 682 |
+
if isinstance(module, nn.Linear):
|
| 683 |
+
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
|
| 684 |
+
if module.bias is not None:
|
| 685 |
+
module.bias.data.zero_()
|
| 686 |
+
elif isinstance(module, nn.Embedding):
|
| 687 |
+
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
|
| 688 |
+
if module.padding_idx is not None:
|
| 689 |
+
module.weight.data[module.padding_idx].zero_()
|
| 690 |
+
elif isinstance(module, RMSNorm):
|
| 691 |
+
module.weight.data.fill_(1.0)
|
| 692 |
+
|
| 693 |
+
for name, p in module.named_parameters():
|
| 694 |
+
if name == "c_proj.weight":
|
| 695 |
+
p.data.normal_(
|
| 696 |
+
mean=0.0,
|
| 697 |
+
std=(
|
| 698 |
+
self.config.initializer_range
|
| 699 |
+
/ math.sqrt(2 * self.config.num_hidden_layers)
|
| 700 |
+
),
|
| 701 |
+
)
|
| 702 |
+
|
| 703 |
+
def _set_gradient_checkpointing(self, module, value=False):
|
| 704 |
+
if isinstance(module, QWenModel):
|
| 705 |
+
module.gradient_checkpointing = value
|
| 706 |
+
|
| 707 |
+
|
| 708 |
+
class QWenModel(QWenPreTrainedModel):
|
| 709 |
+
_keys_to_ignore_on_load_missing = ["attn.masked_bias"]
|
| 710 |
+
|
| 711 |
+
def __init__(self, config):
|
| 712 |
+
super().__init__(config)
|
| 713 |
+
self.vocab_size = config.vocab_size
|
| 714 |
+
self.num_hidden_layers = config.num_hidden_layers
|
| 715 |
+
self.embed_dim = config.hidden_size
|
| 716 |
+
self.use_cache_quantization = self.config.use_cache_quantization if hasattr(self.config, 'use_cache_quantization') else False
|
| 717 |
+
|
| 718 |
+
self.gradient_checkpointing = False
|
| 719 |
+
self.use_dynamic_ntk = config.use_dynamic_ntk
|
| 720 |
+
self.seq_length = config.seq_length
|
| 721 |
+
|
| 722 |
+
self.wte = nn.Embedding(self.vocab_size, self.embed_dim)
|
| 723 |
+
|
| 724 |
+
self.drop = nn.Dropout(config.emb_dropout_prob)
|
| 725 |
+
|
| 726 |
+
if config.rotary_pct == 1.0:
|
| 727 |
+
self.rotary_ndims = None
|
| 728 |
+
else:
|
| 729 |
+
assert config.rotary_pct < 1
|
| 730 |
+
self.rotary_ndims = int(
|
| 731 |
+
config.kv_channels * config.rotary_pct
|
| 732 |
+
)
|
| 733 |
+
dim = (
|
| 734 |
+
self.rotary_ndims
|
| 735 |
+
if self.rotary_ndims is not None
|
| 736 |
+
else config.kv_channels
|
| 737 |
+
)
|
| 738 |
+
self.rotary_emb = RotaryEmbedding(dim, base=config.rotary_emb_base)
|
| 739 |
+
|
| 740 |
+
self.use_flash_attn = config.use_flash_attn
|
| 741 |
+
self.is_fp32 = not (config.bf16 or config.fp16)
|
| 742 |
+
if (
|
| 743 |
+
self.use_flash_attn
|
| 744 |
+
and flash_attn_unpadded_func is not None
|
| 745 |
+
and not self.is_fp32
|
| 746 |
+
):
|
| 747 |
+
self.registered_causal_mask = None
|
| 748 |
+
else:
|
| 749 |
+
max_positions = config.max_position_embeddings
|
| 750 |
+
self.register_buffer(
|
| 751 |
+
"registered_causal_mask",
|
| 752 |
+
torch.tril(
|
| 753 |
+
torch.ones((max_positions, max_positions), dtype=torch.bool)
|
| 754 |
+
).view(1, 1, max_positions, max_positions),
|
| 755 |
+
persistent=False,
|
| 756 |
+
)
|
| 757 |
+
|
| 758 |
+
self.h = nn.ModuleList(
|
| 759 |
+
[
|
| 760 |
+
QWenBlock(
|
| 761 |
+
config
|
| 762 |
+
)
|
| 763 |
+
for i in range(config.num_hidden_layers)
|
| 764 |
+
]
|
| 765 |
+
)
|
| 766 |
+
self.ln_f = RMSNorm(
|
| 767 |
+
self.embed_dim,
|
| 768 |
+
eps=config.layer_norm_epsilon,
|
| 769 |
+
)
|
| 770 |
+
|
| 771 |
+
self.post_init()
|
| 772 |
+
|
| 773 |
+
def get_input_embeddings(self):
|
| 774 |
+
return self.wte
|
| 775 |
+
|
| 776 |
+
def set_input_embeddings(self, new_embeddings):
|
| 777 |
+
self.wte = new_embeddings
|
| 778 |
+
|
| 779 |
+
def get_ntk_alpha(self, true_seq_len):
|
| 780 |
+
context_value = math.log(true_seq_len / self.seq_length, 2) + 1
|
| 781 |
+
ntk_alpha = 2 ** math.ceil(context_value) - 1
|
| 782 |
+
ntk_alpha = max(ntk_alpha, 1)
|
| 783 |
+
return ntk_alpha
|
| 784 |
+
|
| 785 |
+
def forward(
|
| 786 |
+
self,
|
| 787 |
+
input_ids: Optional[torch.LongTensor] = None,
|
| 788 |
+
past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None,
|
| 789 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 790 |
+
token_type_ids: Optional[torch.LongTensor] = None,
|
| 791 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 792 |
+
head_mask: Optional[torch.FloatTensor] = None,
|
| 793 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 794 |
+
encoder_hidden_states: Optional[torch.Tensor] = None,
|
| 795 |
+
encoder_attention_mask: Optional[torch.FloatTensor] = None,
|
| 796 |
+
use_cache: Optional[bool] = None,
|
| 797 |
+
output_attentions: Optional[bool] = None,
|
| 798 |
+
output_hidden_states: Optional[bool] = None,
|
| 799 |
+
return_dict: Optional[bool] = None,
|
| 800 |
+
):
|
| 801 |
+
output_attentions = (
|
| 802 |
+
output_attentions
|
| 803 |
+
if output_attentions is not None
|
| 804 |
+
else self.config.output_attentions
|
| 805 |
+
)
|
| 806 |
+
output_hidden_states = (
|
| 807 |
+
output_hidden_states
|
| 808 |
+
if output_hidden_states is not None
|
| 809 |
+
else self.config.output_hidden_states
|
| 810 |
+
)
|
| 811 |
+
use_cache = use_cache if use_cache is not None else self.config.use_cache
|
| 812 |
+
return_dict = (
|
| 813 |
+
return_dict if return_dict is not None else self.config.use_return_dict
|
| 814 |
+
)
|
| 815 |
+
|
| 816 |
+
if input_ids is not None and inputs_embeds is not None:
|
| 817 |
+
raise ValueError(
|
| 818 |
+
"You cannot specify both input_ids and inputs_embeds at the same time"
|
| 819 |
+
)
|
| 820 |
+
elif input_ids is not None:
|
| 821 |
+
input_shape = input_ids.size()
|
| 822 |
+
input_ids = input_ids.view(-1, input_shape[-1])
|
| 823 |
+
batch_size = input_ids.shape[0]
|
| 824 |
+
elif inputs_embeds is not None:
|
| 825 |
+
input_shape = inputs_embeds.size()[:-1]
|
| 826 |
+
batch_size = inputs_embeds.shape[0]
|
| 827 |
+
else:
|
| 828 |
+
raise ValueError("You have to specify either input_ids or inputs_embeds")
|
| 829 |
+
|
| 830 |
+
device = input_ids.device if input_ids is not None else inputs_embeds.device
|
| 831 |
+
|
| 832 |
+
if token_type_ids is not None:
|
| 833 |
+
token_type_ids = token_type_ids.view(-1, input_shape[-1])
|
| 834 |
+
if position_ids is not None:
|
| 835 |
+
position_ids = position_ids.view(-1, input_shape[-1])
|
| 836 |
+
|
| 837 |
+
if past_key_values is None:
|
| 838 |
+
past_length = 0
|
| 839 |
+
past_key_values = tuple([None] * len(self.h))
|
| 840 |
+
else:
|
| 841 |
+
if self.use_cache_quantization:
|
| 842 |
+
past_length = past_key_values[0][0][0].size(2)
|
| 843 |
+
else:
|
| 844 |
+
past_length = past_key_values[0][0].size(-2)
|
| 845 |
+
if position_ids is None:
|
| 846 |
+
position_ids = torch.arange(
|
| 847 |
+
past_length,
|
| 848 |
+
input_shape[-1] + past_length,
|
| 849 |
+
dtype=torch.long,
|
| 850 |
+
device=device,
|
| 851 |
+
)
|
| 852 |
+
position_ids = position_ids.unsqueeze(0).view(-1, input_shape[-1])
|
| 853 |
+
|
| 854 |
+
if attention_mask is not None:
|
| 855 |
+
if batch_size <= 0:
|
| 856 |
+
raise ValueError("batch_size has to be defined and > 0")
|
| 857 |
+
attention_mask = attention_mask.view(batch_size, -1)
|
| 858 |
+
attention_mask = attention_mask[:, None, None, :]
|
| 859 |
+
attention_mask = attention_mask.to(dtype=self.dtype)
|
| 860 |
+
attention_mask = (1.0 - attention_mask) * torch.finfo(self.dtype).min
|
| 861 |
+
|
| 862 |
+
encoder_attention_mask = None
|
| 863 |
+
head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
|
| 864 |
+
|
| 865 |
+
if inputs_embeds is None:
|
| 866 |
+
inputs_embeds = self.wte(input_ids)
|
| 867 |
+
hidden_states = inputs_embeds
|
| 868 |
+
|
| 869 |
+
kv_seq_len = hidden_states.size()[1]
|
| 870 |
+
if past_key_values[0] is not None:
|
| 871 |
+
# past key values[0][0] shape: bs * seq_len * head_num * dim
|
| 872 |
+
if self.use_cache_quantization:
|
| 873 |
+
kv_seq_len += past_key_values[0][0][0].shape[2]
|
| 874 |
+
else:
|
| 875 |
+
kv_seq_len += past_key_values[0][0].shape[1]
|
| 876 |
+
|
| 877 |
+
if self.training or not self.use_dynamic_ntk:
|
| 878 |
+
ntk_alpha_list = [1.0]
|
| 879 |
+
elif kv_seq_len != hidden_states.size()[1]:
|
| 880 |
+
ntk_alpha_list = self.rotary_emb._ntk_alpha_cached_list
|
| 881 |
+
else:
|
| 882 |
+
ntk_alpha_list = []
|
| 883 |
+
if attention_mask is not None and kv_seq_len > self.seq_length:
|
| 884 |
+
true_seq_lens = attention_mask.squeeze(1).squeeze(1).eq(0).sum(dim=-1, dtype=torch.int32)
|
| 885 |
+
for i in range(hidden_states.size()[0]):
|
| 886 |
+
true_seq_len = true_seq_lens[i].item()
|
| 887 |
+
ntk_alpha = self.get_ntk_alpha(true_seq_len)
|
| 888 |
+
ntk_alpha_list.append(ntk_alpha)
|
| 889 |
+
else:
|
| 890 |
+
ntk_alpha = self.get_ntk_alpha(kv_seq_len)
|
| 891 |
+
ntk_alpha_list.append(ntk_alpha)
|
| 892 |
+
self.rotary_emb._ntk_alpha_cached_list = ntk_alpha_list
|
| 893 |
+
|
| 894 |
+
rotary_pos_emb_list = []
|
| 895 |
+
for ntk_alpha in ntk_alpha_list:
|
| 896 |
+
rotary_pos_emb = self.rotary_emb(kv_seq_len, ntk_alpha=ntk_alpha)
|
| 897 |
+
rotary_pos_emb_list.append(rotary_pos_emb)
|
| 898 |
+
|
| 899 |
+
hidden_states = self.drop(hidden_states)
|
| 900 |
+
output_shape = input_shape + (hidden_states.size(-1),)
|
| 901 |
+
|
| 902 |
+
if self.gradient_checkpointing and self.training:
|
| 903 |
+
if use_cache:
|
| 904 |
+
logger.warning_once(
|
| 905 |
+
"`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
|
| 906 |
+
)
|
| 907 |
+
use_cache = False
|
| 908 |
+
|
| 909 |
+
presents = () if use_cache else None
|
| 910 |
+
all_self_attentions = () if output_attentions else None
|
| 911 |
+
all_hidden_states = () if output_hidden_states else None
|
| 912 |
+
for i, (block, layer_past) in enumerate(zip(self.h, past_key_values)):
|
| 913 |
+
|
| 914 |
+
if output_hidden_states:
|
| 915 |
+
all_hidden_states = all_hidden_states + (hidden_states,)
|
| 916 |
+
|
| 917 |
+
if self.gradient_checkpointing and self.training:
|
| 918 |
+
|
| 919 |
+
def create_custom_forward(module):
|
| 920 |
+
def custom_forward(*inputs):
|
| 921 |
+
# None for past_key_value
|
| 922 |
+
return module(*inputs, use_cache, output_attentions)
|
| 923 |
+
|
| 924 |
+
return custom_forward
|
| 925 |
+
|
| 926 |
+
outputs = torch.utils.checkpoint.checkpoint(
|
| 927 |
+
create_custom_forward(block),
|
| 928 |
+
hidden_states,
|
| 929 |
+
rotary_pos_emb_list,
|
| 930 |
+
self.registered_causal_mask,
|
| 931 |
+
None,
|
| 932 |
+
attention_mask,
|
| 933 |
+
head_mask[i],
|
| 934 |
+
encoder_hidden_states,
|
| 935 |
+
encoder_attention_mask,
|
| 936 |
+
)
|
| 937 |
+
else:
|
| 938 |
+
outputs = block(
|
| 939 |
+
hidden_states,
|
| 940 |
+
layer_past=layer_past,
|
| 941 |
+
rotary_pos_emb_list=rotary_pos_emb_list,
|
| 942 |
+
registered_causal_mask=self.registered_causal_mask,
|
| 943 |
+
attention_mask=attention_mask,
|
| 944 |
+
head_mask=head_mask[i],
|
| 945 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 946 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 947 |
+
use_cache=use_cache,
|
| 948 |
+
output_attentions=output_attentions,
|
| 949 |
+
)
|
| 950 |
+
|
| 951 |
+
hidden_states = outputs[0]
|
| 952 |
+
if use_cache is True:
|
| 953 |
+
presents = presents + (outputs[1],)
|
| 954 |
+
|
| 955 |
+
if output_attentions:
|
| 956 |
+
all_self_attentions = all_self_attentions + (outputs[2 if use_cache else 1],)
|
| 957 |
+
|
| 958 |
+
hidden_states = self.ln_f(hidden_states)
|
| 959 |
+
hidden_states = hidden_states.view(output_shape)
|
| 960 |
+
# Add last hidden state
|
| 961 |
+
if output_hidden_states:
|
| 962 |
+
all_hidden_states = all_hidden_states + (hidden_states,)
|
| 963 |
+
|
| 964 |
+
if not return_dict:
|
| 965 |
+
return tuple(
|
| 966 |
+
v for v in [hidden_states, presents, all_hidden_states] if v is not None
|
| 967 |
+
)
|
| 968 |
+
|
| 969 |
+
return BaseModelOutputWithPast(
|
| 970 |
+
last_hidden_state=hidden_states,
|
| 971 |
+
past_key_values=presents,
|
| 972 |
+
hidden_states=all_hidden_states,
|
| 973 |
+
attentions=all_self_attentions,
|
| 974 |
+
)
|
| 975 |
+
|
| 976 |
+
|
| 977 |
+
class QWenLMHeadModel(QWenPreTrainedModel):
|
| 978 |
+
_keys_to_ignore_on_load_missing = [r"h\.\d+\.attn\.rotary_emb\.inv_freq"]
|
| 979 |
+
_keys_to_ignore_on_load_unexpected = [r"h\.\d+\.attn\.masked_bias"]
|
| 980 |
+
|
| 981 |
+
def __init__(self, config):
|
| 982 |
+
super().__init__(config)
|
| 983 |
+
assert (
|
| 984 |
+
config.bf16 + config.fp16 + config.fp32 <= 1
|
| 985 |
+
), "Only one of \"bf16\", \"fp16\", \"fp32\" can be true"
|
| 986 |
+
logger.warn(
|
| 987 |
+
"Warning: please make sure that you are using the latest codes and checkpoints, "
|
| 988 |
+
"especially if you used Qwen-7B before 09.25.2023."
|
| 989 |
+
"请使用最新模型和代码,尤其如果���在9月25日前已经开始使用Qwen-7B,千万注意不要使用错误代码和模型。"
|
| 990 |
+
)
|
| 991 |
+
|
| 992 |
+
autoset_precision = config.bf16 + config.fp16 + config.fp32 == 0
|
| 993 |
+
|
| 994 |
+
if autoset_precision:
|
| 995 |
+
if SUPPORT_BF16:
|
| 996 |
+
logger.warn(
|
| 997 |
+
"The model is automatically converting to bf16 for faster inference. "
|
| 998 |
+
"If you want to disable the automatic precision, please manually add bf16/fp16/fp32=True to \"AutoModelForCausalLM.from_pretrained\"."
|
| 999 |
+
)
|
| 1000 |
+
config.bf16 = True
|
| 1001 |
+
elif SUPPORT_FP16:
|
| 1002 |
+
logger.warn(
|
| 1003 |
+
"The model is automatically converting to fp16 for faster inference. "
|
| 1004 |
+
"If you want to disable the automatic precision, please manually add bf16/fp16/fp32=True to \"AutoModelForCausalLM.from_pretrained\"."
|
| 1005 |
+
)
|
| 1006 |
+
config.fp16 = True
|
| 1007 |
+
else:
|
| 1008 |
+
config.fp32 = True
|
| 1009 |
+
|
| 1010 |
+
if config.bf16 and SUPPORT_CUDA and not SUPPORT_BF16:
|
| 1011 |
+
logger.warn("Your device does NOT seem to support bf16, you can switch to fp16 or fp32 by by passing fp16/fp32=True in \"AutoModelForCausalLM.from_pretrained\".")
|
| 1012 |
+
if config.fp16 and SUPPORT_CUDA and not SUPPORT_FP16:
|
| 1013 |
+
logger.warn("Your device does NOT support faster inference with fp16, please switch to fp32 which is likely to be faster")
|
| 1014 |
+
if config.fp32:
|
| 1015 |
+
if SUPPORT_BF16:
|
| 1016 |
+
logger.warn("Your device support faster inference by passing bf16=True in \"AutoModelForCausalLM.from_pretrained\".")
|
| 1017 |
+
elif SUPPORT_FP16:
|
| 1018 |
+
logger.warn("Your device support faster inference by passing fp16=True in \"AutoModelForCausalLM.from_pretrained\".")
|
| 1019 |
+
|
| 1020 |
+
if config.use_flash_attn == "auto":
|
| 1021 |
+
if config.bf16 or config.fp16:
|
| 1022 |
+
logger.warn("Try importing flash-attention for faster inference...")
|
| 1023 |
+
config.use_flash_attn = True
|
| 1024 |
+
else:
|
| 1025 |
+
config.use_flash_attn = False
|
| 1026 |
+
if config.use_flash_attn and config.fp32:
|
| 1027 |
+
logger.warn("Flash attention will be disabled because it does NOT support fp32.")
|
| 1028 |
+
|
| 1029 |
+
if config.use_flash_attn:
|
| 1030 |
+
_import_flash_attn()
|
| 1031 |
+
|
| 1032 |
+
self.transformer = QWenModel(config)
|
| 1033 |
+
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
|
| 1034 |
+
|
| 1035 |
+
if config.bf16:
|
| 1036 |
+
self.transformer.bfloat16()
|
| 1037 |
+
self.lm_head.bfloat16()
|
| 1038 |
+
if config.fp16:
|
| 1039 |
+
self.transformer.half()
|
| 1040 |
+
self.lm_head.half()
|
| 1041 |
+
self.post_init()
|
| 1042 |
+
|
| 1043 |
+
|
| 1044 |
+
def get_output_embeddings(self):
|
| 1045 |
+
return self.lm_head
|
| 1046 |
+
|
| 1047 |
+
def set_output_embeddings(self, new_embeddings):
|
| 1048 |
+
self.lm_head = new_embeddings
|
| 1049 |
+
|
| 1050 |
+
def prepare_inputs_for_generation(
|
| 1051 |
+
self, input_ids, past_key_values=None, inputs_embeds=None, **kwargs
|
| 1052 |
+
):
|
| 1053 |
+
token_type_ids = kwargs.get("token_type_ids", None)
|
| 1054 |
+
if past_key_values:
|
| 1055 |
+
input_ids = input_ids[:, -1].unsqueeze(-1)
|
| 1056 |
+
if token_type_ids is not None:
|
| 1057 |
+
token_type_ids = token_type_ids[:, -1].unsqueeze(-1)
|
| 1058 |
+
|
| 1059 |
+
attention_mask = kwargs.get("attention_mask", None)
|
| 1060 |
+
position_ids = kwargs.get("position_ids", None)
|
| 1061 |
+
|
| 1062 |
+
if attention_mask is not None and position_ids is None:
|
| 1063 |
+
position_ids = attention_mask.long().cumsum(-1) - 1
|
| 1064 |
+
position_ids.masked_fill_(attention_mask == 0, 1)
|
| 1065 |
+
if past_key_values:
|
| 1066 |
+
position_ids = position_ids[:, -1].unsqueeze(-1)
|
| 1067 |
+
else:
|
| 1068 |
+
position_ids = None
|
| 1069 |
+
|
| 1070 |
+
if inputs_embeds is not None and past_key_values is None:
|
| 1071 |
+
model_inputs = {"inputs_embeds": inputs_embeds}
|
| 1072 |
+
else:
|
| 1073 |
+
model_inputs = {"input_ids": input_ids}
|
| 1074 |
+
|
| 1075 |
+
model_inputs.update(
|
| 1076 |
+
{
|
| 1077 |
+
"past_key_values": past_key_values,
|
| 1078 |
+
"use_cache": kwargs.get("use_cache"),
|
| 1079 |
+
"position_ids": position_ids,
|
| 1080 |
+
"attention_mask": attention_mask,
|
| 1081 |
+
"token_type_ids": token_type_ids,
|
| 1082 |
+
}
|
| 1083 |
+
)
|
| 1084 |
+
return model_inputs
|
| 1085 |
+
|
| 1086 |
+
def forward(
|
| 1087 |
+
self,
|
| 1088 |
+
input_ids: Optional[torch.LongTensor] = None,
|
| 1089 |
+
past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None,
|
| 1090 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 1091 |
+
token_type_ids: Optional[torch.LongTensor] = None,
|
| 1092 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 1093 |
+
head_mask: Optional[torch.FloatTensor] = None,
|
| 1094 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 1095 |
+
encoder_hidden_states: Optional[torch.Tensor] = None,
|
| 1096 |
+
encoder_attention_mask: Optional[torch.FloatTensor] = None,
|
| 1097 |
+
labels: Optional[torch.LongTensor] = None,
|
| 1098 |
+
use_cache: Optional[bool] = None,
|
| 1099 |
+
output_attentions: Optional[bool] = None,
|
| 1100 |
+
output_hidden_states: Optional[bool] = None,
|
| 1101 |
+
return_dict: Optional[bool] = None,
|
| 1102 |
+
) -> Union[Tuple, CausalLMOutputWithPast]:
|
| 1103 |
+
|
| 1104 |
+
return_dict = (
|
| 1105 |
+
return_dict if return_dict is not None else self.config.use_return_dict
|
| 1106 |
+
)
|
| 1107 |
+
|
| 1108 |
+
transformer_outputs = self.transformer(
|
| 1109 |
+
input_ids,
|
| 1110 |
+
past_key_values=past_key_values,
|
| 1111 |
+
attention_mask=attention_mask,
|
| 1112 |
+
token_type_ids=token_type_ids,
|
| 1113 |
+
position_ids=position_ids,
|
| 1114 |
+
head_mask=head_mask,
|
| 1115 |
+
inputs_embeds=inputs_embeds,
|
| 1116 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 1117 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 1118 |
+
use_cache=use_cache,
|
| 1119 |
+
output_attentions=output_attentions,
|
| 1120 |
+
output_hidden_states=output_hidden_states,
|
| 1121 |
+
return_dict=return_dict,
|
| 1122 |
+
)
|
| 1123 |
+
hidden_states = transformer_outputs[0]
|
| 1124 |
+
|
| 1125 |
+
lm_logits = self.lm_head(hidden_states)
|
| 1126 |
+
|
| 1127 |
+
loss = None
|
| 1128 |
+
if labels is not None:
|
| 1129 |
+
labels = labels.to(lm_logits.device)
|
| 1130 |
+
shift_logits = lm_logits[..., :-1, :].contiguous()
|
| 1131 |
+
shift_labels = labels[..., 1:].contiguous()
|
| 1132 |
+
loss_fct = CrossEntropyLoss()
|
| 1133 |
+
loss = loss_fct(
|
| 1134 |
+
shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1)
|
| 1135 |
+
)
|
| 1136 |
+
|
| 1137 |
+
if not return_dict:
|
| 1138 |
+
output = (lm_logits,) + transformer_outputs[1:]
|
| 1139 |
+
return ((loss,) + output) if loss is not None else output
|
| 1140 |
+
|
| 1141 |
+
return CausalLMOutputWithPast(
|
| 1142 |
+
loss=loss,
|
| 1143 |
+
logits=lm_logits,
|
| 1144 |
+
past_key_values=transformer_outputs.past_key_values,
|
| 1145 |
+
hidden_states=transformer_outputs.hidden_states,
|
| 1146 |
+
attentions=transformer_outputs.attentions,
|
| 1147 |
+
)
|
| 1148 |
+
|
| 1149 |
+
@staticmethod
|
| 1150 |
+
def _reorder_cache(
|
| 1151 |
+
past_key_values: Tuple[Tuple[torch.Tensor]], beam_idx: torch.Tensor
|
| 1152 |
+
) -> Tuple[Tuple[torch.Tensor]]:
|
| 1153 |
+
|
| 1154 |
+
return tuple(
|
| 1155 |
+
tuple(
|
| 1156 |
+
past_state.index_select(0, beam_idx.to(past_state.device))
|
| 1157 |
+
for past_state in layer_past
|
| 1158 |
+
)
|
| 1159 |
+
for layer_past in past_key_values
|
| 1160 |
+
)
|
| 1161 |
+
|
| 1162 |
+
def chat(
|
| 1163 |
+
self,
|
| 1164 |
+
tokenizer: PreTrainedTokenizer,
|
| 1165 |
+
query: str,
|
| 1166 |
+
history: Optional[HistoryType],
|
| 1167 |
+
system: str = "You are a helpful assistant.",
|
| 1168 |
+
append_history: bool = True,
|
| 1169 |
+
stream: Optional[bool] = _SENTINEL,
|
| 1170 |
+
stop_words_ids: Optional[List[List[int]]] = None,
|
| 1171 |
+
generation_config: Optional[GenerationConfig] = None,
|
| 1172 |
+
**kwargs,
|
| 1173 |
+
) -> Tuple[str, HistoryType]:
|
| 1174 |
+
generation_config = generation_config if generation_config is not None else self.generation_config
|
| 1175 |
+
|
| 1176 |
+
assert stream is _SENTINEL, _ERROR_STREAM_IN_CHAT
|
| 1177 |
+
assert generation_config.chat_format == 'chatml', _ERROR_BAD_CHAT_FORMAT
|
| 1178 |
+
if history is None:
|
| 1179 |
+
history = []
|
| 1180 |
+
if stop_words_ids is None:
|
| 1181 |
+
stop_words_ids = []
|
| 1182 |
+
|
| 1183 |
+
max_window_size = kwargs.get('max_window_size', None)
|
| 1184 |
+
if max_window_size is None:
|
| 1185 |
+
max_window_size = generation_config.max_window_size
|
| 1186 |
+
raw_text, context_tokens = make_context(
|
| 1187 |
+
tokenizer,
|
| 1188 |
+
query,
|
| 1189 |
+
history=history,
|
| 1190 |
+
system=system,
|
| 1191 |
+
max_window_size=max_window_size,
|
| 1192 |
+
chat_format=generation_config.chat_format,
|
| 1193 |
+
)
|
| 1194 |
+
|
| 1195 |
+
stop_words_ids.extend(get_stop_words_ids(
|
| 1196 |
+
generation_config.chat_format, tokenizer
|
| 1197 |
+
))
|
| 1198 |
+
input_ids = torch.tensor([context_tokens]).to(self.device)
|
| 1199 |
+
outputs = self.generate(
|
| 1200 |
+
input_ids,
|
| 1201 |
+
stop_words_ids=stop_words_ids,
|
| 1202 |
+
return_dict_in_generate=False,
|
| 1203 |
+
generation_config=generation_config,
|
| 1204 |
+
**kwargs,
|
| 1205 |
+
)
|
| 1206 |
+
|
| 1207 |
+
response = decode_tokens(
|
| 1208 |
+
outputs[0],
|
| 1209 |
+
tokenizer,
|
| 1210 |
+
raw_text_len=len(raw_text),
|
| 1211 |
+
context_length=len(context_tokens),
|
| 1212 |
+
chat_format=generation_config.chat_format,
|
| 1213 |
+
verbose=False,
|
| 1214 |
+
errors='replace'
|
| 1215 |
+
)
|
| 1216 |
+
|
| 1217 |
+
if append_history:
|
| 1218 |
+
history.append((query, response))
|
| 1219 |
+
|
| 1220 |
+
return response, history
|
| 1221 |
+
|
| 1222 |
+
def chat_stream(
|
| 1223 |
+
self,
|
| 1224 |
+
tokenizer: PreTrainedTokenizer,
|
| 1225 |
+
query: str,
|
| 1226 |
+
history: Optional[HistoryType],
|
| 1227 |
+
system: str = "You are a helpful assistant.",
|
| 1228 |
+
stop_words_ids: Optional[List[List[int]]] = None,
|
| 1229 |
+
logits_processor: Optional[LogitsProcessorList] = None,
|
| 1230 |
+
generation_config: Optional[GenerationConfig] = None,
|
| 1231 |
+
**kwargs,
|
| 1232 |
+
) -> Generator[str, Any, None]:
|
| 1233 |
+
generation_config = generation_config if generation_config is not None else self.generation_config
|
| 1234 |
+
assert generation_config.chat_format == 'chatml', _ERROR_BAD_CHAT_FORMAT
|
| 1235 |
+
if history is None:
|
| 1236 |
+
history = []
|
| 1237 |
+
if stop_words_ids is None:
|
| 1238 |
+
stop_words_ids = []
|
| 1239 |
+
|
| 1240 |
+
max_window_size = kwargs.get('max_window_size', None)
|
| 1241 |
+
if max_window_size is None:
|
| 1242 |
+
max_window_size = generation_config.max_window_size
|
| 1243 |
+
raw_text, context_tokens = make_context(
|
| 1244 |
+
tokenizer,
|
| 1245 |
+
query,
|
| 1246 |
+
history=history,
|
| 1247 |
+
system=system,
|
| 1248 |
+
max_window_size=max_window_size,
|
| 1249 |
+
chat_format=generation_config.chat_format,
|
| 1250 |
+
)
|
| 1251 |
+
|
| 1252 |
+
stop_words_ids.extend(get_stop_words_ids(
|
| 1253 |
+
generation_config.chat_format, tokenizer
|
| 1254 |
+
))
|
| 1255 |
+
if stop_words_ids is not None:
|
| 1256 |
+
stop_words_logits_processor = StopWordsLogitsProcessor(
|
| 1257 |
+
stop_words_ids=stop_words_ids,
|
| 1258 |
+
eos_token_id=generation_config.eos_token_id,
|
| 1259 |
+
)
|
| 1260 |
+
if logits_processor is None:
|
| 1261 |
+
logits_processor = LogitsProcessorList([stop_words_logits_processor])
|
| 1262 |
+
else:
|
| 1263 |
+
logits_processor.append(stop_words_logits_processor)
|
| 1264 |
+
input_ids = torch.tensor([context_tokens]).to(self.device)
|
| 1265 |
+
|
| 1266 |
+
from transformers_stream_generator.main import NewGenerationMixin, StreamGenerationConfig
|
| 1267 |
+
self.__class__.generate_stream = NewGenerationMixin.generate
|
| 1268 |
+
self.__class__.sample_stream = NewGenerationMixin.sample_stream
|
| 1269 |
+
stream_config = StreamGenerationConfig(**generation_config.to_dict(), do_stream=True)
|
| 1270 |
+
|
| 1271 |
+
def stream_generator():
|
| 1272 |
+
outputs = []
|
| 1273 |
+
for token in self.generate_stream(
|
| 1274 |
+
input_ids,
|
| 1275 |
+
return_dict_in_generate=False,
|
| 1276 |
+
generation_config=stream_config,
|
| 1277 |
+
logits_processor=logits_processor,
|
| 1278 |
+
seed=-1,
|
| 1279 |
+
**kwargs):
|
| 1280 |
+
outputs.append(token.item())
|
| 1281 |
+
yield tokenizer.decode(outputs, skip_special_tokens=True, errors='ignore')
|
| 1282 |
+
|
| 1283 |
+
return stream_generator()
|
| 1284 |
+
|
| 1285 |
+
def generate(
|
| 1286 |
+
self,
|
| 1287 |
+
inputs: Optional[torch.Tensor] = None,
|
| 1288 |
+
generation_config: Optional[GenerationConfig] = None,
|
| 1289 |
+
logits_processor: Optional[LogitsProcessorList] = None,
|
| 1290 |
+
stopping_criteria: Optional[StoppingCriteriaList] = None,
|
| 1291 |
+
prefix_allowed_tokens_fn: Optional[
|
| 1292 |
+
Callable[[int, torch.Tensor], List[int]]
|
| 1293 |
+
] = None,
|
| 1294 |
+
synced_gpus: Optional[bool] = None,
|
| 1295 |
+
assistant_model: Optional["PreTrainedModel"] = None,
|
| 1296 |
+
streamer: Optional["BaseStreamer"] = None,
|
| 1297 |
+
**kwargs,
|
| 1298 |
+
) -> Union[GenerateOutput, torch.LongTensor]:
|
| 1299 |
+
generation_config = generation_config if generation_config is not None else self.generation_config
|
| 1300 |
+
|
| 1301 |
+
# Process stop_words_ids.
|
| 1302 |
+
stop_words_ids = kwargs.pop("stop_words_ids", None)
|
| 1303 |
+
if stop_words_ids is None and generation_config is not None:
|
| 1304 |
+
stop_words_ids = getattr(generation_config, "stop_words_ids", None)
|
| 1305 |
+
if stop_words_ids is None:
|
| 1306 |
+
stop_words_ids = getattr(generation_config, "stop_words_ids", None)
|
| 1307 |
+
|
| 1308 |
+
if stop_words_ids is not None:
|
| 1309 |
+
stop_words_logits_processor = StopWordsLogitsProcessor(
|
| 1310 |
+
stop_words_ids=stop_words_ids,
|
| 1311 |
+
eos_token_id=generation_config.eos_token_id,
|
| 1312 |
+
)
|
| 1313 |
+
if logits_processor is None:
|
| 1314 |
+
logits_processor = LogitsProcessorList([stop_words_logits_processor])
|
| 1315 |
+
else:
|
| 1316 |
+
logits_processor.append(stop_words_logits_processor)
|
| 1317 |
+
|
| 1318 |
+
return super().generate(
|
| 1319 |
+
inputs,
|
| 1320 |
+
generation_config=generation_config,
|
| 1321 |
+
logits_processor=logits_processor,
|
| 1322 |
+
stopping_criteria=stopping_criteria,
|
| 1323 |
+
prefix_allowed_tokens_fn=prefix_allowed_tokens_fn,
|
| 1324 |
+
synced_gpus=synced_gpus,
|
| 1325 |
+
assistant_model=assistant_model,
|
| 1326 |
+
streamer=streamer,
|
| 1327 |
+
**kwargs,
|
| 1328 |
+
)
|
| 1329 |
+
|
| 1330 |
+
|
| 1331 |
+
class RotaryEmbedding(torch.nn.Module):
|
| 1332 |
+
def __init__(self, dim, base=10000):
|
| 1333 |
+
super().__init__()
|
| 1334 |
+
self.dim = dim
|
| 1335 |
+
self.base = base
|
| 1336 |
+
inv_freq = 1.0 / (base ** (torch.arange(0, dim, 2).float() / dim))
|
| 1337 |
+
self.register_buffer("inv_freq", inv_freq, persistent=False)
|
| 1338 |
+
if importlib.util.find_spec("einops") is None:
|
| 1339 |
+
raise RuntimeError("einops is required for Rotary Embedding")
|
| 1340 |
+
|
| 1341 |
+
self._rotary_pos_emb_cache = None
|
| 1342 |
+
self._seq_len_cached = 0
|
| 1343 |
+
self._ntk_alpha_cached = 1.0
|
| 1344 |
+
self._ntk_alpha_cached_list = [1.0]
|
| 1345 |
+
|
| 1346 |
+
def update_rotary_pos_emb_cache(self, max_seq_len, offset=0, ntk_alpha=1.0):
|
| 1347 |
+
seqlen = max_seq_len + offset
|
| 1348 |
+
if seqlen > self._seq_len_cached or ntk_alpha != self._ntk_alpha_cached:
|
| 1349 |
+
base = self.base * ntk_alpha ** (self.dim / (self.dim - 2))
|
| 1350 |
+
self.inv_freq = 1.0 / (
|
| 1351 |
+
base
|
| 1352 |
+
** (
|
| 1353 |
+
torch.arange(0, self.dim, 2, device=self.inv_freq.device).float()
|
| 1354 |
+
/ self.dim
|
| 1355 |
+
)
|
| 1356 |
+
)
|
| 1357 |
+
self._seq_len_cached = max(2 * seqlen, 16)
|
| 1358 |
+
self._ntk_alpha_cached = ntk_alpha
|
| 1359 |
+
seq = torch.arange(self._seq_len_cached, device=self.inv_freq.device)
|
| 1360 |
+
freqs = torch.outer(seq.type_as(self.inv_freq), self.inv_freq)
|
| 1361 |
+
|
| 1362 |
+
emb = torch.cat((freqs, freqs), dim=-1)
|
| 1363 |
+
from einops import rearrange
|
| 1364 |
+
|
| 1365 |
+
emb = rearrange(emb, "n d -> 1 n 1 d")
|
| 1366 |
+
|
| 1367 |
+
cos, sin = emb.cos(), emb.sin()
|
| 1368 |
+
self._rotary_pos_emb_cache = [cos, sin]
|
| 1369 |
+
|
| 1370 |
+
def forward(self, max_seq_len, offset=0, ntk_alpha=1.0):
|
| 1371 |
+
self.update_rotary_pos_emb_cache(max_seq_len, offset, ntk_alpha)
|
| 1372 |
+
cos, sin = self._rotary_pos_emb_cache
|
| 1373 |
+
return [cos[:, offset : offset + max_seq_len], sin[:, offset : offset + max_seq_len]]
|
| 1374 |
+
|
| 1375 |
+
|
| 1376 |
+
def _rotate_half(x):
|
| 1377 |
+
from einops import rearrange
|
| 1378 |
+
|
| 1379 |
+
x = rearrange(x, "... (j d) -> ... j d", j=2)
|
| 1380 |
+
x1, x2 = x.unbind(dim=-2)
|
| 1381 |
+
return torch.cat((-x2, x1), dim=-1)
|
| 1382 |
+
|
| 1383 |
+
|
| 1384 |
+
def apply_rotary_pos_emb(t, freqs):
|
| 1385 |
+
cos, sin = freqs
|
| 1386 |
+
if apply_rotary_emb_func is not None and t.is_cuda:
|
| 1387 |
+
t_ = t.float()
|
| 1388 |
+
cos = cos.squeeze(0).squeeze(1)[:, : cos.shape[-1] // 2]
|
| 1389 |
+
sin = sin.squeeze(0).squeeze(1)[:, : sin.shape[-1] // 2]
|
| 1390 |
+
output = apply_rotary_emb_func(t_, cos, sin).type_as(t)
|
| 1391 |
+
return output
|
| 1392 |
+
else:
|
| 1393 |
+
rot_dim = freqs[0].shape[-1]
|
| 1394 |
+
cos, sin = freqs
|
| 1395 |
+
t_, t_pass_ = t[..., :rot_dim], t[..., rot_dim:]
|
| 1396 |
+
t_ = t_.float()
|
| 1397 |
+
t_pass_ = t_pass_.float()
|
| 1398 |
+
t_ = (t_ * cos) + (_rotate_half(t_) * sin)
|
| 1399 |
+
return torch.cat((t_, t_pass_), dim=-1).type_as(t)
|
| 1400 |
+
|
| 1401 |
+
|
| 1402 |
+
class RMSNorm(torch.nn.Module):
|
| 1403 |
+
def __init__(self, dim: int, eps: float = 1e-6):
|
| 1404 |
+
super().__init__()
|
| 1405 |
+
self.eps = eps
|
| 1406 |
+
self.weight = nn.Parameter(torch.ones(dim))
|
| 1407 |
+
|
| 1408 |
+
def _norm(self, x):
|
| 1409 |
+
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
|
| 1410 |
+
|
| 1411 |
+
def forward(self, x):
|
| 1412 |
+
if rms_norm is not None and x.is_cuda:
|
| 1413 |
+
return rms_norm(x, self.weight, self.eps)
|
| 1414 |
+
else:
|
| 1415 |
+
output = self._norm(x.float()).type_as(x)
|
| 1416 |
+
return output * self.weight
|
quantize_config.json
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bits": 8,
|
| 3 |
+
"group_size": 128,
|
| 4 |
+
"damp_percent": 0.01,
|
| 5 |
+
"desc_act": false,
|
| 6 |
+
"static_groups": false,
|
| 7 |
+
"sym": true,
|
| 8 |
+
"true_sequential": true,
|
| 9 |
+
"model_name_or_path": null,
|
| 10 |
+
"model_file_base_name": null
|
| 11 |
+
}
|
qwen.tiktoken
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
qwen_generation_utils.py
ADDED
|
@@ -0,0 +1,416 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Alibaba Cloud.
|
| 2 |
+
#
|
| 3 |
+
# This source code is licensed under the license found in the
|
| 4 |
+
# LICENSE file in the root directory of this source tree.
|
| 5 |
+
|
| 6 |
+
"""Generation support."""
|
| 7 |
+
|
| 8 |
+
from typing import Tuple, List, Union, Iterable
|
| 9 |
+
|
| 10 |
+
import numpy as np
|
| 11 |
+
import torch
|
| 12 |
+
import torch.nn.functional as F
|
| 13 |
+
from transformers import PreTrainedTokenizer
|
| 14 |
+
from transformers import logging
|
| 15 |
+
from transformers.generation import LogitsProcessor
|
| 16 |
+
|
| 17 |
+
logger = logging.get_logger(__name__)
|
| 18 |
+
|
| 19 |
+
# Types.
|
| 20 |
+
HistoryType = List[Tuple[str, str]]
|
| 21 |
+
TokensType = List[int]
|
| 22 |
+
BatchTokensType = List[List[int]]
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def pad_batch(batch: BatchTokensType, pad_id: int, seq_length: int) -> BatchTokensType:
|
| 26 |
+
for tokens in batch:
|
| 27 |
+
context_length = len(tokens)
|
| 28 |
+
if context_length < seq_length:
|
| 29 |
+
tokens.extend([pad_id] * (seq_length - context_length))
|
| 30 |
+
return batch
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def get_ltor_masks_and_position_ids(
|
| 34 |
+
data,
|
| 35 |
+
eod_token,
|
| 36 |
+
reset_position_ids,
|
| 37 |
+
reset_attention_mask,
|
| 38 |
+
eod_mask_loss,
|
| 39 |
+
):
|
| 40 |
+
"""Build masks and position id for left to right model."""
|
| 41 |
+
|
| 42 |
+
# Extract batch size and sequence length.
|
| 43 |
+
micro_batch_size, seq_length = data.size()
|
| 44 |
+
|
| 45 |
+
# Attention mask (lower triangular).
|
| 46 |
+
if reset_attention_mask:
|
| 47 |
+
att_mask_batch = micro_batch_size
|
| 48 |
+
else:
|
| 49 |
+
att_mask_batch = 1
|
| 50 |
+
attention_mask = torch.tril(
|
| 51 |
+
torch.ones((att_mask_batch, seq_length, seq_length), device=data.device)
|
| 52 |
+
).view(att_mask_batch, 1, seq_length, seq_length)
|
| 53 |
+
|
| 54 |
+
# Loss mask.
|
| 55 |
+
loss_mask = torch.ones(data.size(), dtype=torch.float, device=data.device)
|
| 56 |
+
if eod_mask_loss:
|
| 57 |
+
loss_mask[data == eod_token] = 0.0
|
| 58 |
+
|
| 59 |
+
# Position ids.
|
| 60 |
+
position_ids = torch.arange(seq_length, dtype=torch.long, device=data.device)
|
| 61 |
+
position_ids = position_ids.unsqueeze(0).expand_as(data)
|
| 62 |
+
# We need to clone as the ids will be modifed based on batch index.
|
| 63 |
+
if reset_position_ids:
|
| 64 |
+
position_ids = position_ids.clone()
|
| 65 |
+
|
| 66 |
+
if reset_position_ids or reset_attention_mask:
|
| 67 |
+
# Loop through the batches:
|
| 68 |
+
for b in range(micro_batch_size):
|
| 69 |
+
|
| 70 |
+
# Find indecies where EOD token is.
|
| 71 |
+
eod_index = position_ids[b, data[b] == eod_token]
|
| 72 |
+
# Detach indecies from positions if going to modify positions.
|
| 73 |
+
if reset_position_ids:
|
| 74 |
+
eod_index = eod_index.clone()
|
| 75 |
+
|
| 76 |
+
# Loop through EOD indecies:
|
| 77 |
+
prev_index = 0
|
| 78 |
+
for j in range(eod_index.size()[0]):
|
| 79 |
+
i = eod_index[j]
|
| 80 |
+
# Mask attention loss.
|
| 81 |
+
if reset_attention_mask:
|
| 82 |
+
attention_mask[b, 0, (i + 1) :, : (i + 1)] = 0
|
| 83 |
+
# Reset positions.
|
| 84 |
+
if reset_position_ids:
|
| 85 |
+
position_ids[b, (i + 1) :] -= i + 1 - prev_index
|
| 86 |
+
prev_index = i + 1
|
| 87 |
+
|
| 88 |
+
# Convert attention mask to binary:
|
| 89 |
+
attention_mask = attention_mask < 0.5
|
| 90 |
+
|
| 91 |
+
return attention_mask, loss_mask, position_ids
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
def get_batch(context_tokens: torch.LongTensor, eod_id: int):
|
| 95 |
+
"""Generate batch from context tokens."""
|
| 96 |
+
# Move to GPU.
|
| 97 |
+
tokens = context_tokens.contiguous().to(context_tokens.device)
|
| 98 |
+
# Get the attention mask and postition ids.
|
| 99 |
+
attention_mask, _, position_ids = get_ltor_masks_and_position_ids(
|
| 100 |
+
tokens,
|
| 101 |
+
eod_id,
|
| 102 |
+
reset_position_ids=False,
|
| 103 |
+
reset_attention_mask=False,
|
| 104 |
+
eod_mask_loss=False,
|
| 105 |
+
)
|
| 106 |
+
return tokens, attention_mask, position_ids
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
def get_stop_words_ids(chat_format, tokenizer):
|
| 110 |
+
if chat_format == "raw":
|
| 111 |
+
stop_words_ids = [tokenizer.encode("Human:"), [tokenizer.eod_id]]
|
| 112 |
+
elif chat_format == "chatml":
|
| 113 |
+
stop_words_ids = [[tokenizer.im_end_id], [tokenizer.im_start_id]]
|
| 114 |
+
else:
|
| 115 |
+
raise NotImplementedError(f"Unknown chat format {chat_format!r}")
|
| 116 |
+
return stop_words_ids
|
| 117 |
+
|
| 118 |
+
|
| 119 |
+
def make_context(
|
| 120 |
+
tokenizer: PreTrainedTokenizer,
|
| 121 |
+
query: str,
|
| 122 |
+
history: List[Tuple[str, str]] = None,
|
| 123 |
+
system: str = "",
|
| 124 |
+
max_window_size: int = 6144,
|
| 125 |
+
chat_format: str = "chatml",
|
| 126 |
+
):
|
| 127 |
+
if history is None:
|
| 128 |
+
history = []
|
| 129 |
+
|
| 130 |
+
if chat_format == "chatml":
|
| 131 |
+
im_start, im_end = "<|im_start|>", "<|im_end|>"
|
| 132 |
+
im_start_tokens = [tokenizer.im_start_id]
|
| 133 |
+
im_end_tokens = [tokenizer.im_end_id]
|
| 134 |
+
nl_tokens = tokenizer.encode("\n")
|
| 135 |
+
|
| 136 |
+
def _tokenize_str(role, content):
|
| 137 |
+
return f"{role}\n{content}", tokenizer.encode(
|
| 138 |
+
role, allowed_special=set()
|
| 139 |
+
) + nl_tokens + tokenizer.encode(content, allowed_special=set())
|
| 140 |
+
|
| 141 |
+
system_text, system_tokens_part = _tokenize_str("system", system)
|
| 142 |
+
system_tokens = im_start_tokens + system_tokens_part + im_end_tokens
|
| 143 |
+
|
| 144 |
+
raw_text = ""
|
| 145 |
+
context_tokens = []
|
| 146 |
+
|
| 147 |
+
for turn_query, turn_response in reversed(history):
|
| 148 |
+
query_text, query_tokens_part = _tokenize_str("user", turn_query)
|
| 149 |
+
query_tokens = im_start_tokens + query_tokens_part + im_end_tokens
|
| 150 |
+
response_text, response_tokens_part = _tokenize_str(
|
| 151 |
+
"assistant", turn_response
|
| 152 |
+
)
|
| 153 |
+
response_tokens = im_start_tokens + response_tokens_part + im_end_tokens
|
| 154 |
+
|
| 155 |
+
next_context_tokens = nl_tokens + query_tokens + nl_tokens + response_tokens
|
| 156 |
+
prev_chat = (
|
| 157 |
+
f"\n{im_start}{query_text}{im_end}\n{im_start}{response_text}{im_end}"
|
| 158 |
+
)
|
| 159 |
+
|
| 160 |
+
current_context_size = (
|
| 161 |
+
len(system_tokens) + len(next_context_tokens) + len(context_tokens)
|
| 162 |
+
)
|
| 163 |
+
if current_context_size < max_window_size:
|
| 164 |
+
context_tokens = next_context_tokens + context_tokens
|
| 165 |
+
raw_text = prev_chat + raw_text
|
| 166 |
+
else:
|
| 167 |
+
break
|
| 168 |
+
|
| 169 |
+
context_tokens = system_tokens + context_tokens
|
| 170 |
+
raw_text = f"{im_start}{system_text}{im_end}" + raw_text
|
| 171 |
+
context_tokens += (
|
| 172 |
+
nl_tokens
|
| 173 |
+
+ im_start_tokens
|
| 174 |
+
+ _tokenize_str("user", query)[1]
|
| 175 |
+
+ im_end_tokens
|
| 176 |
+
+ nl_tokens
|
| 177 |
+
+ im_start_tokens
|
| 178 |
+
+ tokenizer.encode("assistant")
|
| 179 |
+
+ nl_tokens
|
| 180 |
+
)
|
| 181 |
+
raw_text += f"\n{im_start}user\n{query}{im_end}\n{im_start}assistant\n"
|
| 182 |
+
|
| 183 |
+
elif chat_format == "raw":
|
| 184 |
+
raw_text = query
|
| 185 |
+
context_tokens = tokenizer.encode(raw_text)
|
| 186 |
+
else:
|
| 187 |
+
raise NotImplementedError(f"Unknown chat format {chat_format!r}")
|
| 188 |
+
|
| 189 |
+
return raw_text, context_tokens
|
| 190 |
+
|
| 191 |
+
|
| 192 |
+
def _decode_default(
|
| 193 |
+
tokens: List[int],
|
| 194 |
+
*,
|
| 195 |
+
stop_words: List[str],
|
| 196 |
+
eod_words: List[str],
|
| 197 |
+
tokenizer: PreTrainedTokenizer,
|
| 198 |
+
raw_text_len: int,
|
| 199 |
+
verbose: bool = False,
|
| 200 |
+
return_end_reason: bool = False,
|
| 201 |
+
errors: str='replace',
|
| 202 |
+
):
|
| 203 |
+
trim_decode_tokens = tokenizer.decode(tokens, errors=errors)[raw_text_len:]
|
| 204 |
+
if verbose:
|
| 205 |
+
print("\nRaw Generate: ", trim_decode_tokens)
|
| 206 |
+
|
| 207 |
+
end_reason = f"Gen length {len(tokens)}"
|
| 208 |
+
for stop_word in stop_words:
|
| 209 |
+
trim_decode_tokens = trim_decode_tokens.replace(stop_word, "").strip()
|
| 210 |
+
for eod_word in eod_words:
|
| 211 |
+
if eod_word in trim_decode_tokens:
|
| 212 |
+
end_reason = f"Gen {eod_word!r}"
|
| 213 |
+
trim_decode_tokens = trim_decode_tokens.split(eod_word)[0]
|
| 214 |
+
trim_decode_tokens = trim_decode_tokens.strip()
|
| 215 |
+
if verbose:
|
| 216 |
+
print("\nEnd Reason:", end_reason)
|
| 217 |
+
print("\nGenerate: ", trim_decode_tokens)
|
| 218 |
+
|
| 219 |
+
if return_end_reason:
|
| 220 |
+
return trim_decode_tokens, end_reason
|
| 221 |
+
else:
|
| 222 |
+
return trim_decode_tokens
|
| 223 |
+
|
| 224 |
+
|
| 225 |
+
def _decode_chatml(
|
| 226 |
+
tokens: List[int],
|
| 227 |
+
*,
|
| 228 |
+
stop_words: List[str],
|
| 229 |
+
eod_token_ids: List[int],
|
| 230 |
+
tokenizer: PreTrainedTokenizer,
|
| 231 |
+
raw_text_len: int,
|
| 232 |
+
context_length: int,
|
| 233 |
+
verbose: bool = False,
|
| 234 |
+
return_end_reason: bool = False,
|
| 235 |
+
errors: str='replace'
|
| 236 |
+
):
|
| 237 |
+
end_reason = f"Gen length {len(tokens)}"
|
| 238 |
+
eod_token_idx = context_length
|
| 239 |
+
for eod_token_idx in range(context_length, len(tokens)):
|
| 240 |
+
if tokens[eod_token_idx] in eod_token_ids:
|
| 241 |
+
end_reason = f"Gen {tokenizer.decode([tokens[eod_token_idx]])!r}"
|
| 242 |
+
break
|
| 243 |
+
|
| 244 |
+
trim_decode_tokens = tokenizer.decode(tokens[:eod_token_idx], errors=errors)[raw_text_len:]
|
| 245 |
+
if verbose:
|
| 246 |
+
print("\nRaw Generate w/o EOD:", tokenizer.decode(tokens, errors=errors)[raw_text_len:])
|
| 247 |
+
print("\nRaw Generate:", trim_decode_tokens)
|
| 248 |
+
print("\nEnd Reason:", end_reason)
|
| 249 |
+
for stop_word in stop_words:
|
| 250 |
+
trim_decode_tokens = trim_decode_tokens.replace(stop_word, "").strip()
|
| 251 |
+
trim_decode_tokens = trim_decode_tokens.strip()
|
| 252 |
+
if verbose:
|
| 253 |
+
print("\nGenerate:", trim_decode_tokens)
|
| 254 |
+
|
| 255 |
+
if return_end_reason:
|
| 256 |
+
return trim_decode_tokens, end_reason
|
| 257 |
+
else:
|
| 258 |
+
return trim_decode_tokens
|
| 259 |
+
|
| 260 |
+
|
| 261 |
+
def decode_tokens(
|
| 262 |
+
tokens: Union[torch.LongTensor, TokensType],
|
| 263 |
+
tokenizer: PreTrainedTokenizer,
|
| 264 |
+
raw_text_len: int,
|
| 265 |
+
context_length: int,
|
| 266 |
+
chat_format: str,
|
| 267 |
+
verbose: bool = False,
|
| 268 |
+
return_end_reason: bool = False,
|
| 269 |
+
errors: str="replace",
|
| 270 |
+
) -> str:
|
| 271 |
+
if torch.is_tensor(tokens):
|
| 272 |
+
tokens = tokens.cpu().numpy().tolist()
|
| 273 |
+
|
| 274 |
+
if chat_format == "chatml":
|
| 275 |
+
return _decode_chatml(
|
| 276 |
+
tokens,
|
| 277 |
+
stop_words=[],
|
| 278 |
+
eod_token_ids=[tokenizer.im_start_id, tokenizer.im_end_id],
|
| 279 |
+
tokenizer=tokenizer,
|
| 280 |
+
raw_text_len=raw_text_len,
|
| 281 |
+
context_length=context_length,
|
| 282 |
+
verbose=verbose,
|
| 283 |
+
return_end_reason=return_end_reason,
|
| 284 |
+
errors=errors,
|
| 285 |
+
)
|
| 286 |
+
elif chat_format == "raw":
|
| 287 |
+
return _decode_default(
|
| 288 |
+
tokens,
|
| 289 |
+
stop_words=["<|endoftext|>"],
|
| 290 |
+
eod_words=["<|endoftext|>"],
|
| 291 |
+
tokenizer=tokenizer,
|
| 292 |
+
raw_text_len=raw_text_len,
|
| 293 |
+
verbose=verbose,
|
| 294 |
+
return_end_reason=return_end_reason,
|
| 295 |
+
errors=errors,
|
| 296 |
+
)
|
| 297 |
+
else:
|
| 298 |
+
raise NotImplementedError(f"Unknown chat format {chat_format!r}")
|
| 299 |
+
|
| 300 |
+
|
| 301 |
+
class StopWordsLogitsProcessor(LogitsProcessor):
|
| 302 |
+
"""
|
| 303 |
+
:class:`transformers.LogitsProcessor` that enforces that when specified sequences appear, stop geration.
|
| 304 |
+
|
| 305 |
+
Args:
|
| 306 |
+
stop_words_ids (:obj:`List[List[int]]`):
|
| 307 |
+
List of list of token ids of stop ids. In order to get the tokens of the words
|
| 308 |
+
that should not appear in the generated text, use :obj:`tokenizer(bad_word,
|
| 309 |
+
add_prefix_space=True).input_ids`.
|
| 310 |
+
eos_token_id (:obj:`int`):
|
| 311 |
+
The id of the `end-of-sequence` token.
|
| 312 |
+
"""
|
| 313 |
+
|
| 314 |
+
def __init__(self, stop_words_ids: Iterable[Iterable[int]], eos_token_id: int):
|
| 315 |
+
|
| 316 |
+
if not isinstance(stop_words_ids, List) or len(stop_words_ids) == 0:
|
| 317 |
+
raise ValueError(
|
| 318 |
+
f"`stop_words_ids` has to be a non-emtpy list, but is {stop_words_ids}."
|
| 319 |
+
)
|
| 320 |
+
if any(not isinstance(bad_word_ids, list) for bad_word_ids in stop_words_ids):
|
| 321 |
+
raise ValueError(
|
| 322 |
+
f"`stop_words_ids` has to be a list of lists, but is {stop_words_ids}."
|
| 323 |
+
)
|
| 324 |
+
if any(
|
| 325 |
+
any(
|
| 326 |
+
(not isinstance(token_id, (int, np.integer)) or token_id < 0)
|
| 327 |
+
for token_id in stop_word_ids
|
| 328 |
+
)
|
| 329 |
+
for stop_word_ids in stop_words_ids
|
| 330 |
+
):
|
| 331 |
+
raise ValueError(
|
| 332 |
+
f"Each list in `stop_words_ids` has to be a list of positive integers, but is {stop_words_ids}."
|
| 333 |
+
)
|
| 334 |
+
|
| 335 |
+
self.stop_words_ids = list(
|
| 336 |
+
filter(
|
| 337 |
+
lambda bad_token_seq: bad_token_seq != [eos_token_id], stop_words_ids
|
| 338 |
+
)
|
| 339 |
+
)
|
| 340 |
+
self.eos_token_id = eos_token_id
|
| 341 |
+
for stop_token_seq in self.stop_words_ids:
|
| 342 |
+
assert (
|
| 343 |
+
len(stop_token_seq) > 0
|
| 344 |
+
), "Stop words token sequences {} cannot have an empty list".format(
|
| 345 |
+
stop_words_ids
|
| 346 |
+
)
|
| 347 |
+
|
| 348 |
+
def __call__(
|
| 349 |
+
self, input_ids: torch.LongTensor, scores: torch.FloatTensor
|
| 350 |
+
) -> torch.FloatTensor:
|
| 351 |
+
stopped_samples = self._calc_stopped_samples(input_ids)
|
| 352 |
+
for i, should_stop in enumerate(stopped_samples):
|
| 353 |
+
if should_stop:
|
| 354 |
+
scores[i, self.eos_token_id] = float(2**15)
|
| 355 |
+
return scores
|
| 356 |
+
|
| 357 |
+
def _tokens_match(self, prev_tokens: torch.LongTensor, tokens: List[int]) -> bool:
|
| 358 |
+
if len(tokens) == 0:
|
| 359 |
+
# if bad word tokens is just one token always ban it
|
| 360 |
+
return True
|
| 361 |
+
elif len(tokens) > len(prev_tokens):
|
| 362 |
+
# if bad word tokens are longer then prev input_ids they can't be equal
|
| 363 |
+
return False
|
| 364 |
+
elif prev_tokens[-len(tokens) :].tolist() == tokens:
|
| 365 |
+
# if tokens match
|
| 366 |
+
return True
|
| 367 |
+
else:
|
| 368 |
+
return False
|
| 369 |
+
|
| 370 |
+
def _calc_stopped_samples(self, prev_input_ids: Iterable[int]) -> Iterable[int]:
|
| 371 |
+
stopped_samples = []
|
| 372 |
+
for prev_input_ids_slice in prev_input_ids:
|
| 373 |
+
match = False
|
| 374 |
+
for stop_token_seq in self.stop_words_ids:
|
| 375 |
+
if self._tokens_match(prev_input_ids_slice, stop_token_seq):
|
| 376 |
+
# if tokens do not match continue
|
| 377 |
+
match = True
|
| 378 |
+
break
|
| 379 |
+
stopped_samples.append(match)
|
| 380 |
+
|
| 381 |
+
return stopped_samples
|
| 382 |
+
|
| 383 |
+
|
| 384 |
+
def top_k_logits(logits, top_k=0, top_p=0.0, filter_value=-float("Inf")):
|
| 385 |
+
"""This function has been mostly taken from huggingface conversational
|
| 386 |
+
ai code at
|
| 387 |
+
https://medium.com/huggingface/how-to-build-a-state-of-the-art-
|
| 388 |
+
conversational-ai-with-transfer-learning-2d818ac26313"""
|
| 389 |
+
|
| 390 |
+
if top_k > 0:
|
| 391 |
+
# Remove all tokens with a probability less than the
|
| 392 |
+
# last token of the top-k
|
| 393 |
+
indices_to_remove = logits < torch.topk(logits, top_k)[0][..., -1, None]
|
| 394 |
+
logits[indices_to_remove] = filter_value
|
| 395 |
+
|
| 396 |
+
if top_p > 0.0:
|
| 397 |
+
# Cconvert to 1D
|
| 398 |
+
sorted_logits, sorted_indices = torch.sort(logits, descending=True, dim=-1)
|
| 399 |
+
cumulative_probs = torch.cumsum(F.softmax(sorted_logits, dim=-1), dim=-1)
|
| 400 |
+
|
| 401 |
+
# Remove tokens with cumulative probability above the threshold
|
| 402 |
+
sorted_indices_to_remove = cumulative_probs > top_p
|
| 403 |
+
# Shift the indices to the right to keep also the first token
|
| 404 |
+
# above the threshold
|
| 405 |
+
sorted_indices_to_remove[..., 1:] = sorted_indices_to_remove[..., :-1].clone()
|
| 406 |
+
sorted_indices_to_remove[..., 0] = 0
|
| 407 |
+
for i in range(sorted_indices.size(0)):
|
| 408 |
+
indices_to_remove = sorted_indices[i][sorted_indices_to_remove[i]]
|
| 409 |
+
logits[i][indices_to_remove] = filter_value
|
| 410 |
+
|
| 411 |
+
return logits
|
| 412 |
+
|
| 413 |
+
|
| 414 |
+
def switch(val1, val2, boolean):
|
| 415 |
+
boolean = boolean.type_as(val1)
|
| 416 |
+
return (1 - boolean) * val1 + boolean * val2
|
tokenization_qwen.py
ADDED
|
@@ -0,0 +1,276 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Alibaba Cloud.
|
| 2 |
+
#
|
| 3 |
+
# This source code is licensed under the license found in the
|
| 4 |
+
# LICENSE file in the root directory of this source tree.
|
| 5 |
+
|
| 6 |
+
"""Tokenization classes for QWen."""
|
| 7 |
+
|
| 8 |
+
import base64
|
| 9 |
+
import logging
|
| 10 |
+
import os
|
| 11 |
+
import unicodedata
|
| 12 |
+
from typing import Collection, Dict, List, Set, Tuple, Union
|
| 13 |
+
|
| 14 |
+
import tiktoken
|
| 15 |
+
from transformers import PreTrainedTokenizer, AddedToken
|
| 16 |
+
|
| 17 |
+
logger = logging.getLogger(__name__)
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
VOCAB_FILES_NAMES = {"vocab_file": "qwen.tiktoken"}
|
| 21 |
+
|
| 22 |
+
PAT_STR = r"""(?i:'s|'t|'re|'ve|'m|'ll|'d)|[^\r\n\p{L}\p{N}]?\p{L}+|\p{N}| ?[^\s\p{L}\p{N}]+[\r\n]*|\s*[\r\n]+|\s+(?!\S)|\s+"""
|
| 23 |
+
ENDOFTEXT = "<|endoftext|>"
|
| 24 |
+
IMSTART = "<|im_start|>"
|
| 25 |
+
IMEND = "<|im_end|>"
|
| 26 |
+
# as the default behavior is changed to allow special tokens in
|
| 27 |
+
# regular texts, the surface forms of special tokens need to be
|
| 28 |
+
# as different as possible to minimize the impact
|
| 29 |
+
EXTRAS = tuple((f"<|extra_{i}|>" for i in range(205)))
|
| 30 |
+
# changed to use actual index to avoid misconfiguration with vocabulary expansion
|
| 31 |
+
SPECIAL_START_ID = 151643
|
| 32 |
+
SPECIAL_TOKENS = tuple(
|
| 33 |
+
enumerate(
|
| 34 |
+
(
|
| 35 |
+
(
|
| 36 |
+
ENDOFTEXT,
|
| 37 |
+
IMSTART,
|
| 38 |
+
IMEND,
|
| 39 |
+
)
|
| 40 |
+
+ EXTRAS
|
| 41 |
+
),
|
| 42 |
+
start=SPECIAL_START_ID,
|
| 43 |
+
)
|
| 44 |
+
)
|
| 45 |
+
SPECIAL_TOKENS_SET = set(t for i, t in SPECIAL_TOKENS)
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
def _load_tiktoken_bpe(tiktoken_bpe_file: str) -> Dict[bytes, int]:
|
| 49 |
+
with open(tiktoken_bpe_file, "rb") as f:
|
| 50 |
+
contents = f.read()
|
| 51 |
+
return {
|
| 52 |
+
base64.b64decode(token): int(rank)
|
| 53 |
+
for token, rank in (line.split() for line in contents.splitlines() if line)
|
| 54 |
+
}
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
class QWenTokenizer(PreTrainedTokenizer):
|
| 58 |
+
"""QWen tokenizer."""
|
| 59 |
+
|
| 60 |
+
vocab_files_names = VOCAB_FILES_NAMES
|
| 61 |
+
|
| 62 |
+
def __init__(
|
| 63 |
+
self,
|
| 64 |
+
vocab_file,
|
| 65 |
+
errors="replace",
|
| 66 |
+
extra_vocab_file=None,
|
| 67 |
+
**kwargs,
|
| 68 |
+
):
|
| 69 |
+
super().__init__(**kwargs)
|
| 70 |
+
|
| 71 |
+
# how to handle errors in decoding UTF-8 byte sequences
|
| 72 |
+
# use ignore if you are in streaming inference
|
| 73 |
+
self.errors = errors
|
| 74 |
+
|
| 75 |
+
self.mergeable_ranks = _load_tiktoken_bpe(vocab_file) # type: Dict[bytes, int]
|
| 76 |
+
self.special_tokens = {
|
| 77 |
+
token: index
|
| 78 |
+
for index, token in SPECIAL_TOKENS
|
| 79 |
+
}
|
| 80 |
+
|
| 81 |
+
# try load extra vocab from file
|
| 82 |
+
if extra_vocab_file is not None:
|
| 83 |
+
used_ids = set(self.mergeable_ranks.values()) | set(self.special_tokens.values())
|
| 84 |
+
extra_mergeable_ranks = _load_tiktoken_bpe(extra_vocab_file)
|
| 85 |
+
for token, index in extra_mergeable_ranks.items():
|
| 86 |
+
if token in self.mergeable_ranks:
|
| 87 |
+
logger.info(f"extra token {token} exists, skipping")
|
| 88 |
+
continue
|
| 89 |
+
if index in used_ids:
|
| 90 |
+
logger.info(f'the index {index} for extra token {token} exists, skipping')
|
| 91 |
+
continue
|
| 92 |
+
self.mergeable_ranks[token] = index
|
| 93 |
+
# the index may be sparse after this, but don't worry tiktoken.Encoding will handle this
|
| 94 |
+
|
| 95 |
+
enc = tiktoken.Encoding(
|
| 96 |
+
"Qwen",
|
| 97 |
+
pat_str=PAT_STR,
|
| 98 |
+
mergeable_ranks=self.mergeable_ranks,
|
| 99 |
+
special_tokens=self.special_tokens,
|
| 100 |
+
)
|
| 101 |
+
assert (
|
| 102 |
+
len(self.mergeable_ranks) + len(self.special_tokens) == enc.n_vocab
|
| 103 |
+
), f"{len(self.mergeable_ranks) + len(self.special_tokens)} != {enc.n_vocab} in encoding"
|
| 104 |
+
|
| 105 |
+
self.decoder = {
|
| 106 |
+
v: k for k, v in self.mergeable_ranks.items()
|
| 107 |
+
} # type: dict[int, bytes|str]
|
| 108 |
+
self.decoder.update({v: k for k, v in self.special_tokens.items()})
|
| 109 |
+
|
| 110 |
+
self.tokenizer = enc # type: tiktoken.Encoding
|
| 111 |
+
|
| 112 |
+
self.eod_id = self.tokenizer.eot_token
|
| 113 |
+
self.im_start_id = self.special_tokens[IMSTART]
|
| 114 |
+
self.im_end_id = self.special_tokens[IMEND]
|
| 115 |
+
|
| 116 |
+
def __getstate__(self):
|
| 117 |
+
# for pickle lovers
|
| 118 |
+
state = self.__dict__.copy()
|
| 119 |
+
del state["tokenizer"]
|
| 120 |
+
return state
|
| 121 |
+
|
| 122 |
+
def __setstate__(self, state):
|
| 123 |
+
# tokenizer is not python native; don't pass it; rebuild it
|
| 124 |
+
self.__dict__.update(state)
|
| 125 |
+
enc = tiktoken.Encoding(
|
| 126 |
+
"Qwen",
|
| 127 |
+
pat_str=PAT_STR,
|
| 128 |
+
mergeable_ranks=self.mergeable_ranks,
|
| 129 |
+
special_tokens=self.special_tokens,
|
| 130 |
+
)
|
| 131 |
+
self.tokenizer = enc
|
| 132 |
+
|
| 133 |
+
def __len__(self) -> int:
|
| 134 |
+
return self.tokenizer.n_vocab
|
| 135 |
+
|
| 136 |
+
def get_vocab(self) -> Dict[bytes, int]:
|
| 137 |
+
return self.mergeable_ranks
|
| 138 |
+
|
| 139 |
+
def convert_tokens_to_ids(
|
| 140 |
+
self, tokens: Union[bytes, str, List[Union[bytes, str]]]
|
| 141 |
+
) -> List[int]:
|
| 142 |
+
ids = []
|
| 143 |
+
if isinstance(tokens, (str, bytes)):
|
| 144 |
+
if tokens in self.special_tokens:
|
| 145 |
+
return self.special_tokens[tokens]
|
| 146 |
+
else:
|
| 147 |
+
return self.mergeable_ranks.get(tokens)
|
| 148 |
+
for token in tokens:
|
| 149 |
+
if token in self.special_tokens:
|
| 150 |
+
ids.append(self.special_tokens[token])
|
| 151 |
+
else:
|
| 152 |
+
ids.append(self.mergeable_ranks.get(token))
|
| 153 |
+
return ids
|
| 154 |
+
|
| 155 |
+
def _add_tokens(
|
| 156 |
+
self,
|
| 157 |
+
new_tokens: Union[List[str], List[AddedToken]],
|
| 158 |
+
special_tokens: bool = False,
|
| 159 |
+
) -> int:
|
| 160 |
+
if not special_tokens and new_tokens:
|
| 161 |
+
raise ValueError("Adding regular tokens is not supported")
|
| 162 |
+
for token in new_tokens:
|
| 163 |
+
surface_form = token.content if isinstance(token, AddedToken) else token
|
| 164 |
+
if surface_form not in SPECIAL_TOKENS_SET:
|
| 165 |
+
raise ValueError("Adding unknown special tokens is not supported")
|
| 166 |
+
return 0
|
| 167 |
+
|
| 168 |
+
def save_vocabulary(self, save_directory: str, **kwargs) -> Tuple[str]:
|
| 169 |
+
"""
|
| 170 |
+
Save only the vocabulary of the tokenizer (vocabulary).
|
| 171 |
+
|
| 172 |
+
Returns:
|
| 173 |
+
`Tuple(str)`: Paths to the files saved.
|
| 174 |
+
"""
|
| 175 |
+
file_path = os.path.join(save_directory, "qwen.tiktoken")
|
| 176 |
+
with open(file_path, "w", encoding="utf8") as w:
|
| 177 |
+
for k, v in self.mergeable_ranks.items():
|
| 178 |
+
line = base64.b64encode(k).decode("utf8") + " " + str(v) + "\n"
|
| 179 |
+
w.write(line)
|
| 180 |
+
return (file_path,)
|
| 181 |
+
|
| 182 |
+
def tokenize(
|
| 183 |
+
self,
|
| 184 |
+
text: str,
|
| 185 |
+
allowed_special: Union[Set, str] = "all",
|
| 186 |
+
disallowed_special: Union[Collection, str] = (),
|
| 187 |
+
**kwargs,
|
| 188 |
+
) -> List[Union[bytes, str]]:
|
| 189 |
+
"""
|
| 190 |
+
Converts a string in a sequence of tokens.
|
| 191 |
+
|
| 192 |
+
Args:
|
| 193 |
+
text (`str`):
|
| 194 |
+
The sequence to be encoded.
|
| 195 |
+
allowed_special (`Literal["all"]` or `set`):
|
| 196 |
+
The surface forms of the tokens to be encoded as special tokens in regular texts.
|
| 197 |
+
Default to "all".
|
| 198 |
+
disallowed_special (`Literal["all"]` or `Collection`):
|
| 199 |
+
The surface forms of the tokens that should not be in regular texts and trigger errors.
|
| 200 |
+
Default to an empty tuple.
|
| 201 |
+
|
| 202 |
+
kwargs (additional keyword arguments, *optional*):
|
| 203 |
+
Will be passed to the underlying model specific encode method.
|
| 204 |
+
|
| 205 |
+
Returns:
|
| 206 |
+
`List[bytes|str]`: The list of tokens.
|
| 207 |
+
"""
|
| 208 |
+
tokens = []
|
| 209 |
+
text = unicodedata.normalize("NFC", text)
|
| 210 |
+
|
| 211 |
+
# this implementation takes a detour: text -> token id -> token surface forms
|
| 212 |
+
for t in self.tokenizer.encode(
|
| 213 |
+
text, allowed_special=allowed_special, disallowed_special=disallowed_special
|
| 214 |
+
):
|
| 215 |
+
tokens.append(self.decoder[t])
|
| 216 |
+
return tokens
|
| 217 |
+
|
| 218 |
+
def convert_tokens_to_string(self, tokens: List[Union[bytes, str]]) -> str:
|
| 219 |
+
"""
|
| 220 |
+
Converts a sequence of tokens in a single string.
|
| 221 |
+
"""
|
| 222 |
+
text = ""
|
| 223 |
+
temp = b""
|
| 224 |
+
for t in tokens:
|
| 225 |
+
if isinstance(t, str):
|
| 226 |
+
if temp:
|
| 227 |
+
text += temp.decode("utf-8", errors=self.errors)
|
| 228 |
+
temp = b""
|
| 229 |
+
text += t
|
| 230 |
+
elif isinstance(t, bytes):
|
| 231 |
+
temp += t
|
| 232 |
+
else:
|
| 233 |
+
raise TypeError("token should only be of type types or str")
|
| 234 |
+
if temp:
|
| 235 |
+
text += temp.decode("utf-8", errors=self.errors)
|
| 236 |
+
return text
|
| 237 |
+
|
| 238 |
+
@property
|
| 239 |
+
def vocab_size(self):
|
| 240 |
+
return self.tokenizer.n_vocab
|
| 241 |
+
|
| 242 |
+
def _convert_id_to_token(self, index: int) -> Union[bytes, str]:
|
| 243 |
+
"""Converts an id to a token, special tokens included"""
|
| 244 |
+
if index in self.decoder:
|
| 245 |
+
return self.decoder[index]
|
| 246 |
+
raise ValueError("unknown ids")
|
| 247 |
+
|
| 248 |
+
def _convert_token_to_id(self, token: Union[bytes, str]) -> int:
|
| 249 |
+
"""Converts a token to an id using the vocab, special tokens included"""
|
| 250 |
+
if token in self.special_tokens:
|
| 251 |
+
return self.special_tokens[token]
|
| 252 |
+
if token in self.mergeable_ranks:
|
| 253 |
+
return self.mergeable_ranks[token]
|
| 254 |
+
raise ValueError("unknown token")
|
| 255 |
+
|
| 256 |
+
def _tokenize(self, text: str, **kwargs):
|
| 257 |
+
"""
|
| 258 |
+
Converts a string in a sequence of tokens (string), using the tokenizer. Split in words for word-based
|
| 259 |
+
vocabulary or sub-words for sub-word-based vocabularies (BPE/SentencePieces/WordPieces).
|
| 260 |
+
|
| 261 |
+
Do NOT take care of added tokens.
|
| 262 |
+
"""
|
| 263 |
+
raise NotImplementedError
|
| 264 |
+
|
| 265 |
+
def _decode(
|
| 266 |
+
self,
|
| 267 |
+
token_ids: Union[int, List[int]],
|
| 268 |
+
skip_special_tokens: bool = False,
|
| 269 |
+
errors: str = None,
|
| 270 |
+
**kwargs,
|
| 271 |
+
) -> str:
|
| 272 |
+
if isinstance(token_ids, int):
|
| 273 |
+
token_ids = [token_ids]
|
| 274 |
+
if skip_special_tokens:
|
| 275 |
+
token_ids = [i for i in token_ids if i < self.eod_id]
|
| 276 |
+
return self.tokenizer.decode(token_ids, errors=errors or self.errors)
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"model_max_length": 8192,
|
| 3 |
+
"tokenizer_class": "QWenTokenizer",
|
| 4 |
+
"auto_map": {
|
| 5 |
+
"AutoTokenizer": [
|
| 6 |
+
"tokenization_qwen.QWenTokenizer",
|
| 7 |
+
null
|
| 8 |
+
]
|
| 9 |
+
}
|
| 10 |
+
}
|