

update
Browse files- LICENSE +55 -0
- NOTICE +280 -0
- README.md +299 -0
- assets/logo.jpg +0 -0
- assets/qwen_tokenizer.png +0 -0
- assets/wechat.png +0 -0
- cache_autogptq_cuda_256.cpp +198 -0
- cache_autogptq_cuda_kernel_256.cu +1708 -0
- modeling_qwen.py +62 -69
LICENSE
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Tongyi Qianwen RESEARCH LICENSE AGREEMENT
|
| 2 |
+
|
| 3 |
+
Tongyi Qianwen Release Date: November 30, 2023
|
| 4 |
+
|
| 5 |
+
By clicking to agree or by using or distributing any portion or element of the Tongyi Qianwen Materials, you will be deemed to have recognized and accepted the content of this Agreement, which is effective immediately.
|
| 6 |
+
|
| 7 |
+
1. Definitions
|
| 8 |
+
a. This Tongyi Qianwen RESEARCH LICENSE AGREEMENT (this "Agreement") shall mean the terms and conditions for use, reproduction, distribution and modification of the Materials as defined by this Agreement.
|
| 9 |
+
b. "We"(or "Us") shall mean Alibaba Cloud.
|
| 10 |
+
c. "You" (or "Your") shall mean a natural person or legal entity exercising the rights granted by this Agreement and/or using the Materials for any purpose and in any field of use.
|
| 11 |
+
d. "Third Parties" shall mean individuals or legal entities that are not under common control with Us or You.
|
| 12 |
+
e. "Tongyi Qianwen" shall mean the large language models, and software and algorithms, consisting of trained model weights, parameters (including optimizer states), machine-learning model code, inference-enabling code, training-enabling code, fine-tuning enabling code and other elements of the foregoing distributed by Us.
|
| 13 |
+
f. "Materials" shall mean, collectively, Alibaba Cloud's proprietary Tongyi Qianwen and Documentation (and any portion thereof) made available under this Agreement.
|
| 14 |
+
g. "Source" form shall mean the preferred form for making modifications, including but not limited to model source code, documentation source, and configuration files.
|
| 15 |
+
h. "Object" form shall mean any form resulting from mechanical transformation or translation of a Source form, including but not limited to compiled object code, generated documentation,
|
| 16 |
+
and conversions to other media types.
|
| 17 |
+
i. "Non-Commercial" shall mean for research or evaluation purposes only.
|
| 18 |
+
|
| 19 |
+
2. Grant of Rights
|
| 20 |
+
a. You are granted a non-exclusive, worldwide, non-transferable and royalty-free limited license under Alibaba Cloud's intellectual property or other rights owned by Us embodied in the Materials to use, reproduce, distribute, copy, create derivative works of, and make modifications to the Materials FOR NON-COMMERCIAL PURPOSES ONLY.
|
| 21 |
+
b. If you are commercially using the Materials, You shall request a license from Us.
|
| 22 |
+
|
| 23 |
+
3. Redistribution
|
| 24 |
+
You may reproduce and distribute copies of the Materials or derivative works thereof in any medium, with or without modifications, and in Source or Object form, provided that You meet the following conditions:
|
| 25 |
+
a. You shall give any other recipients of the Materials or derivative works a copy of this Agreement;
|
| 26 |
+
b. You shall cause any modified files to carry prominent notices stating that You changed the files;
|
| 27 |
+
c. You shall retain in all copies of the Materials that You distribute the following attribution notices within a "Notice" text file distributed as a part of such copies: "Tongyi Qianwen is licensed under the Tongyi Qianwen RESEARCH LICENSE AGREEMENT, Copyright (c) Alibaba Cloud. All Rights Reserved."; and
|
| 28 |
+
d. You may add Your own copyright statement to Your modifications and may provide additional or different license terms and conditions for use, reproduction, or distribution of Your modifications, or for any such derivative works as a whole, provided Your use, reproduction, and distribution of the work otherwise complies with the terms and conditions of this Agreement.
|
| 29 |
+
|
| 30 |
+
4. Rules of use
|
| 31 |
+
a. The Materials may be subject to export controls or restrictions in China, the United States or other countries or regions. You shall comply with applicable laws and regulations in your use of the Materials.
|
| 32 |
+
b. You can not use the Materials or any output therefrom to improve any other large language model (excluding Tongyi Qianwen or derivative works thereof).
|
| 33 |
+
|
| 34 |
+
5. Intellectual Property
|
| 35 |
+
a. We retain ownership of all intellectual property rights in and to the Materials and derivatives made by or for Us. Conditioned upon compliance with the terms and conditions of this Agreement, with respect to any derivative works and modifications of the Materials that are made by you, you are and will be the owner of such derivative works and modifications.
|
| 36 |
+
b. No trademark license is granted to use the trade names, trademarks, service marks, or product names of Us, except as required to fulfill notice requirements under this Agreement or as required for reasonable and customary use in describing and redistributing the Materials.
|
| 37 |
+
c. If you commence a lawsuit or other proceedings (including a cross-claim or counterclaim in a lawsuit) against Us or any entity alleging that the Materials or any output therefrom, or any part of the foregoing, infringe any intellectual property or other right owned or licensable by you, then all licences granted to you under this Agreement shall terminate as of the date such lawsuit or other proceeding is commenced or brought.
|
| 38 |
+
|
| 39 |
+
6. Disclaimer of Warranty and Limitation of Liability
|
| 40 |
+
a. We are not obligated to support, update, provide training for, or develop any further version of the Tongyi Qianwen Materials or to grant any license thereto.
|
| 41 |
+
b. THE MATERIALS ARE PROVIDED "AS IS" WITHOUT ANY EXPRESS OR IMPLIED WARRANTY OF ANY KIND INCLUDING WARRANTIES OF MERCHANTABILITY, NONINFRINGEMENT, OR FITNESS FOR A PARTICULAR PURPOSE. WE MAKE NO WARRANTY AND ASSUME NO RESPONSIBILITY FOR THE SAFETY OR STABILITY OF THE MATERIALS AND ANY OUTPUT THEREFROM.
|
| 42 |
+
c. IN NO EVENT SHALL WE BE LIABLE TO YOU FOR ANY DAMAGES, INCLUDING, BUT NOT LIMITED TO ANY DIRECT, OR INDIRECT, SPECIAL OR CONSEQUENTIAL DAMAGES ARISING FROM YOUR USE OR INABILITY TO USE THE MATERIALS OR ANY OUTPUT OF IT, NO MATTER HOW IT’S CAUSED.
|
| 43 |
+
d. You will defend, indemnify and hold harmless Us from and against any claim by any third party arising out of or related to your use or distribution of the Materials.
|
| 44 |
+
|
| 45 |
+
7. Survival and Termination.
|
| 46 |
+
a. The term of this Agreement shall commence upon your acceptance of this Agreement or access to the Materials and will continue in full force and effect until terminated in accordance with the terms and conditions herein.
|
| 47 |
+
b. We may terminate this Agreement if you breach any of the terms or conditions of this Agreement. Upon termination of this Agreement, you must delete and cease use of the Materials. Sections 6 and 8 shall survive the termination of this Agreement.
|
| 48 |
+
|
| 49 |
+
8. Governing Law and Jurisdiction.
|
| 50 |
+
a. This Agreement and any dispute arising out of or relating to it will be governed by the laws of China, without regard to conflict of law principles, and the UN Convention on Contracts for the International Sale of Goods does not apply to this Agreement.
|
| 51 |
+
b. The People's Courts in Hangzhou City shall have exclusive jurisdiction over any dispute arising out of this Agreement.
|
| 52 |
+
|
| 53 |
+
9. Other Terms and Conditions.
|
| 54 |
+
a. Any arrangements, understandings, or agreements regarding the Material not stated herein are separate from and independent of the terms and conditions of this Agreement. You shall request a seperate license from Us, if You use the Materials in ways not expressly agreed to in this Agreement.
|
| 55 |
+
b. We shall not be bound by any additional or different terms or conditions communicated by You unless expressly agreed.
|
NOTICE
ADDED
|
@@ -0,0 +1,280 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
------------- LICENSE FOR NVIDIA Megatron-LM code --------------
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
|
| 4 |
+
|
| 5 |
+
Redistribution and use in source and binary forms, with or without
|
| 6 |
+
modification, are permitted provided that the following conditions
|
| 7 |
+
are met:
|
| 8 |
+
* Redistributions of source code must retain the above copyright
|
| 9 |
+
notice, this list of conditions and the following disclaimer.
|
| 10 |
+
* Redistributions in binary form must reproduce the above copyright
|
| 11 |
+
notice, this list of conditions and the following disclaimer in the
|
| 12 |
+
documentation and/or other materials provided with the distribution.
|
| 13 |
+
* Neither the name of NVIDIA CORPORATION nor the names of its
|
| 14 |
+
contributors may be used to endorse or promote products derived
|
| 15 |
+
from this software without specific prior written permission.
|
| 16 |
+
|
| 17 |
+
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS ``AS IS'' AND ANY
|
| 18 |
+
EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
|
| 19 |
+
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
|
| 20 |
+
PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR
|
| 21 |
+
CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL,
|
| 22 |
+
EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO,
|
| 23 |
+
PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR
|
| 24 |
+
PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY
|
| 25 |
+
OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
|
| 26 |
+
(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
|
| 27 |
+
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
------------- LICENSE FOR OpenAI tiktoken code --------------
|
| 31 |
+
|
| 32 |
+
MIT License
|
| 33 |
+
|
| 34 |
+
Copyright (c) 2022 OpenAI, Shantanu Jain
|
| 35 |
+
|
| 36 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 37 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 38 |
+
in the Software without restriction, including without limitation the rights
|
| 39 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 40 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 41 |
+
furnished to do so, subject to the following conditions:
|
| 42 |
+
|
| 43 |
+
The above copyright notice and this permission notice shall be included in all
|
| 44 |
+
copies or substantial portions of the Software.
|
| 45 |
+
|
| 46 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 47 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 48 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 49 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 50 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 51 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 52 |
+
SOFTWARE.
|
| 53 |
+
|
| 54 |
+
------------- LICENSE FOR stanford_alpaca code --------------
|
| 55 |
+
|
| 56 |
+
Apache License
|
| 57 |
+
Version 2.0, January 2004
|
| 58 |
+
http://www.apache.org/licenses/
|
| 59 |
+
|
| 60 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 61 |
+
|
| 62 |
+
1. Definitions.
|
| 63 |
+
|
| 64 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 65 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 66 |
+
|
| 67 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 68 |
+
the copyright owner that is granting the License.
|
| 69 |
+
|
| 70 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 71 |
+
other entities that control, are controlled by, or are under common
|
| 72 |
+
control with that entity. For the purposes of this definition,
|
| 73 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 74 |
+
direction or management of such entity, whether by contract or
|
| 75 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 76 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 77 |
+
|
| 78 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 79 |
+
exercising permissions granted by this License.
|
| 80 |
+
|
| 81 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 82 |
+
including but not limited to software source code, documentation
|
| 83 |
+
source, and configuration files.
|
| 84 |
+
|
| 85 |
+
"Object" form shall mean any form resulting from mechanical
|
| 86 |
+
transformation or translation of a Source form, including but
|
| 87 |
+
not limited to compiled object code, generated documentation,
|
| 88 |
+
and conversions to other media types.
|
| 89 |
+
|
| 90 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 91 |
+
Object form, made available under the License, as indicated by a
|
| 92 |
+
copyright notice that is included in or attached to the work
|
| 93 |
+
(an example is provided in the Appendix below).
|
| 94 |
+
|
| 95 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 96 |
+
form, that is based on (or derived from) the Work and for which the
|
| 97 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 98 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 99 |
+
of this License, Derivative Works shall not include works that remain
|
| 100 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 101 |
+
the Work and Derivative Works thereof.
|
| 102 |
+
|
| 103 |
+
"Contribution" shall mean any work of authorship, including
|
| 104 |
+
the original version of the Work and any modifications or additions
|
| 105 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 106 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 107 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 108 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 109 |
+
means any form of electronic, verbal, or written communication sent
|
| 110 |
+
to the Licensor or its representatives, including but not limited to
|
| 111 |
+
communication on electronic mailing lists, source code control systems,
|
| 112 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 113 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 114 |
+
excluding communication that is conspicuously marked or otherwise
|
| 115 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 116 |
+
|
| 117 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 118 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 119 |
+
subsequently incorporated within the Work.
|
| 120 |
+
|
| 121 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 122 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 123 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 124 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 125 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 126 |
+
Work and such Derivative Works in Source or Object form.
|
| 127 |
+
|
| 128 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 129 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 130 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 131 |
+
(except as stated in this section) patent license to make, have made,
|
| 132 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 133 |
+
where such license applies only to those patent claims licensable
|
| 134 |
+
by such Contributor that are necessarily infringed by their
|
| 135 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 136 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 137 |
+
institute patent litigation against any entity (including a
|
| 138 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 139 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 140 |
+
or contributory patent infringement, then any patent licenses
|
| 141 |
+
granted to You under this License for that Work shall terminate
|
| 142 |
+
as of the date such litigation is filed.
|
| 143 |
+
|
| 144 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 145 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 146 |
+
modifications, and in Source or Object form, provided that You
|
| 147 |
+
meet the following conditions:
|
| 148 |
+
|
| 149 |
+
(a) You must give any other recipients of the Work or
|
| 150 |
+
Derivative Works a copy of this License; and
|
| 151 |
+
|
| 152 |
+
(b) You must cause any modified files to carry prominent notices
|
| 153 |
+
stating that You changed the files; and
|
| 154 |
+
|
| 155 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 156 |
+
that You distribute, all copyright, patent, trademark, and
|
| 157 |
+
attribution notices from the Source form of the Work,
|
| 158 |
+
excluding those notices that do not pertain to any part of
|
| 159 |
+
the Derivative Works; and
|
| 160 |
+
|
| 161 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 162 |
+
distribution, then any Derivative Works that You distribute must
|
| 163 |
+
include a readable copy of the attribution notices contained
|
| 164 |
+
within such NOTICE file, excluding those notices that do not
|
| 165 |
+
pertain to any part of the Derivative Works, in at least one
|
| 166 |
+
of the following places: within a NOTICE text file distributed
|
| 167 |
+
as part of the Derivative Works; within the Source form or
|
| 168 |
+
documentation, if provided along with the Derivative Works; or,
|
| 169 |
+
within a display generated by the Derivative Works, if and
|
| 170 |
+
wherever such third-party notices normally appear. The contents
|
| 171 |
+
of the NOTICE file are for informational purposes only and
|
| 172 |
+
do not modify the License. You may add Your own attribution
|
| 173 |
+
notices within Derivative Works that You distribute, alongside
|
| 174 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 175 |
+
that such additional attribution notices cannot be construed
|
| 176 |
+
as modifying the License.
|
| 177 |
+
|
| 178 |
+
You may add Your own copyright statement to Your modifications and
|
| 179 |
+
may provide additional or different license terms and conditions
|
| 180 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 181 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 182 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 183 |
+
the conditions stated in this License.
|
| 184 |
+
|
| 185 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 186 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 187 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 188 |
+
this License, without any additional terms or conditions.
|
| 189 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 190 |
+
the terms of any separate license agreement you may have executed
|
| 191 |
+
with Licensor regarding such Contributions.
|
| 192 |
+
|
| 193 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 194 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 195 |
+
except as required for reasonable and customary use in describing the
|
| 196 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 197 |
+
|
| 198 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 199 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 200 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 201 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 202 |
+
implied, including, without limitation, any warranties or conditions
|
| 203 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 204 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 205 |
+
appropriateness of using or redistributing the Work and assume any
|
| 206 |
+
risks associated with Your exercise of permissions under this License.
|
| 207 |
+
|
| 208 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 209 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 210 |
+
unless required by applicable law (such as deliberate and grossly
|
| 211 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 212 |
+
liable to You for damages, including any direct, indirect, special,
|
| 213 |
+
incidental, or consequential damages of any character arising as a
|
| 214 |
+
result of this License or out of the use or inability to use the
|
| 215 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 216 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 217 |
+
other commercial damages or losses), even if such Contributor
|
| 218 |
+
has been advised of the possibility of such damages.
|
| 219 |
+
|
| 220 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 221 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 222 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 223 |
+
or other liability obligations and/or rights consistent with this
|
| 224 |
+
License. However, in accepting such obligations, You may act only
|
| 225 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 226 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 227 |
+
defend, and hold each Contributor harmless for any liability
|
| 228 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 229 |
+
of your accepting any such warranty or additional liability.
|
| 230 |
+
|
| 231 |
+
END OF TERMS AND CONDITIONS
|
| 232 |
+
|
| 233 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 234 |
+
|
| 235 |
+
To apply the Apache License to your work, attach the following
|
| 236 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 237 |
+
replaced with your own identifying information. (Don't include
|
| 238 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 239 |
+
comment syntax for the file format. We also recommend that a
|
| 240 |
+
file or class name and description of purpose be included on the
|
| 241 |
+
same "printed page" as the copyright notice for easier
|
| 242 |
+
identification within third-party archives.
|
| 243 |
+
|
| 244 |
+
Copyright 2023 Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li
|
| 245 |
+
|
| 246 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 247 |
+
you may not use this file except in compliance with the License.
|
| 248 |
+
You may obtain a copy of the License at
|
| 249 |
+
|
| 250 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 251 |
+
|
| 252 |
+
Unless required by applicable law or agreed to in writing, software
|
| 253 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 254 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 255 |
+
See the License for the specific language governing permissions and
|
| 256 |
+
limitations under the License.
|
| 257 |
+
|
| 258 |
+
------------- LICENSE FOR PanQiWei AutoGPTQ code --------------
|
| 259 |
+
|
| 260 |
+
MIT License
|
| 261 |
+
|
| 262 |
+
Copyright (c) 2023 潘其威(William)
|
| 263 |
+
|
| 264 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 265 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 266 |
+
in the Software without restriction, including without limitation the rights
|
| 267 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 268 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 269 |
+
furnished to do so, subject to the following conditions:
|
| 270 |
+
|
| 271 |
+
The above copyright notice and this permission notice shall be included in all
|
| 272 |
+
copies or substantial portions of the Software.
|
| 273 |
+
|
| 274 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 275 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 276 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 277 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 278 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 279 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 280 |
+
SOFTWARE.
|
README.md
ADDED
|
@@ -0,0 +1,299 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
language:
|
| 3 |
+
- zh
|
| 4 |
+
- en
|
| 5 |
+
tags:
|
| 6 |
+
- qwen
|
| 7 |
+
pipeline_tag: text-generation
|
| 8 |
+
inference: false
|
| 9 |
+
---
|
| 10 |
+
|
| 11 |
+
# Qwen-1.8B
|
| 12 |
+
|
| 13 |
+
<p align="center">
|
| 14 |
+
<img src="https://qianwen-res.oss-cn-beijing.aliyuncs.com/logo_qwen.jpg" width="400"/>
|
| 15 |
+
<p>
|
| 16 |
+
<br>
|
| 17 |
+
|
| 18 |
+
<p align="center">
|
| 19 |
+
🤗 <a href="https://huggingface.co/Qwen">Hugging Face</a>   |   🤖 <a href="https://modelscope.cn/organization/qwen">ModelScope</a>   |    📑 <a href="https://arxiv.org/abs/2309.16609">Paper</a>    |   🖥️ <a href="https://modelscope.cn/studios/qwen/Qwen-14B-Chat-Demo/summary">Demo</a>
|
| 20 |
+
<br>
|
| 21 |
+
<a href="assets/wechat.png">WeChat (微信)</a>   |   <a href="https://discord.gg/z3GAxXZ9Ce">Discord</a>   |   <a href="https://dashscope.aliyun.com">API</a>
|
| 22 |
+
</p>
|
| 23 |
+
<br>
|
| 24 |
+
|
| 25 |
+
## 介绍 (Introduction)
|
| 26 |
+
|
| 27 |
+
**通义千问-1.8B(Qwen-1.8B)**是阿里云研发的通义千问大模型系列的18亿参数规模的模型。Qwen-1.8B是基于Transformer的大语言模型, 在超大规模的预训练数据上进行训练得到。预训练数据类型多样,覆盖广泛,包括大量网络文本、专业书籍、代码等。同时,在Qwen-1.8B的基础上,我们使用对齐机制打造了基于大语言模型的AI助手Qwen-1.8B-Chat。本仓库为Qwen-1.8B的仓库。
|
| 28 |
+
|
| 29 |
+
通义千问-1.8B(Qwen-1.8B)主要有以下特点:
|
| 30 |
+
1. **低成本部署**:提供int8和int4量化版本,推理最低仅需不到2GB显存,生成2048 tokens仅需3GB显存占用。微调最低仅需6GB。
|
| 31 |
+
2. **大规模高质量训练语料**:使用超过2.2万亿tokens的数据进行预训练,包含高质量中、英、多语言、代码、数学等数据,涵盖通用及专业领域的训练语料。通过大量对比实验对预训练语料分布进行了优化。
|
| 32 |
+
3. **优秀的性能**:Qwen-1.8B支持8192上下文长度,在多个中英文下游评测任务上(涵盖常识推理、代码、数学、翻译等),效果显著超越现有的相近规模开源模型,具体评测结果请详见下文。
|
| 33 |
+
4. **覆盖更全面的词表**:相比目前以中英词表为主的开源模型,Qwen-1.8B使用了约15万大小的词表。该词表对多语言更加友好,方便用户在不扩展词表的情况下对部分语种进行能力增强和扩展。
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
如果您想了解更多关于通义千问1.8B开源模型的细节,我们建议您参阅[GitHub代码库](https://github.com/QwenLM/Qwen)。
|
| 37 |
+
|
| 38 |
+
**Qwen-1.8B** is the 1.8B-parameter version of the large language model series, Qwen (abbr. Tongyi Qianwen), proposed by Aibaba Cloud. Qwen-1.8B is a Transformer-based large language model, which is pretrained on a large volume of data, including web texts, books, codes, etc. Additionally, based on the pretrained Qwen-1.8B, we release Qwen-1.8B-Chat, a large-model-based AI assistant, which is trained with alignment techniques. This repository is the one for Qwen-1.8B.
|
| 39 |
+
|
| 40 |
+
The features of Qwen-1.8B include:
|
| 41 |
+
1. **Low-cost deployment**: We provide int4 and int8 quantized versions, the minimum memory requirment for inference is less than 2GB, generating 2048 tokens only 3GB of memory usage. The minimum memory requirment of finetuning is only 6GB.
|
| 42 |
+
2. **Large-scale high-quality training corpora**: It is pretrained on over 2.2 trillion tokens, including Chinese, English, multilingual texts, code, and mathematics, covering general and professional fields. The distribution of the pre-training corpus has been optimized through a large number of ablation experiments.
|
| 43 |
+
3. **Good performance**: It supports 8192 context length and significantly surpasses existing open-source models of similar scale on multiple Chinese and English downstream evaluation tasks (including commonsense, reasoning, code, mathematics, etc.), and even surpasses some larger-scale models in several benchmarks. See below for specific evaluation results.
|
| 44 |
+
4. **More comprehensive vocabulary coverage**: Compared with other open-source models based on Chinese and English vocabularies, Qwen-1.8B uses a vocabulary of over 150K tokens. This vocabulary is more friendly to multiple languages, enabling users to directly further enhance the capability for certain languages without expanding the vocabulary.
|
| 45 |
+
|
| 46 |
+
For more details about the open-source model of Qwen-1.8B, please refer to the [GitHub](https://github.com/QwenLM/Qwen) code repository.
|
| 47 |
+
<br>
|
| 48 |
+
|
| 49 |
+
## 要求(Requirements)
|
| 50 |
+
|
| 51 |
+
* python 3.8及以上版本
|
| 52 |
+
* pytorch 1.12及以上版本,推荐2.0及以上版本
|
| 53 |
+
* 建议使用CUDA 11.4及以上(GPU用户、flash-attention用户等需考虑此选项)
|
| 54 |
+
* python 3.8 and above
|
| 55 |
+
* pytorch 1.12 and above, 2.0 and above are recommended
|
| 56 |
+
* CUDA 11.4 and above are recommended (this is for GPU users, flash-attention users, etc.)
|
| 57 |
+
|
| 58 |
+
## 依赖项 (Dependency)
|
| 59 |
+
|
| 60 |
+
运行Qwen-1.8B,请确保满足上述要求,再执行以下pip命令安装依赖库
|
| 61 |
+
|
| 62 |
+
To run Qwen-1.8B, please make sure you meet the above requirements, and then execute the following pip commands to install the dependent libraries.
|
| 63 |
+
|
| 64 |
+
```bash
|
| 65 |
+
pip install transformers==4.32.0 accelerate tiktoken einops
|
| 66 |
+
```
|
| 67 |
+
|
| 68 |
+
另外,推荐安装`flash-attention`库(**当前已支持flash attention 2**),以实现更高的效率和更低的显存占用。
|
| 69 |
+
|
| 70 |
+
In addition, it is recommended to install the `flash-attention` library (**we support flash attention 2 now.**) for higher efficiency and lower memory usage.
|
| 71 |
+
|
| 72 |
+
```bash
|
| 73 |
+
git clone https://github.com/Dao-AILab/flash-attention
|
| 74 |
+
cd flash-attention && pip install .
|
| 75 |
+
# 下方安装可选,安装可能比较缓慢。
|
| 76 |
+
# pip install csrc/layer_norm
|
| 77 |
+
# pip install csrc/rotary
|
| 78 |
+
```
|
| 79 |
+
<br>
|
| 80 |
+
|
| 81 |
+
## 快速使用(Quickstart)
|
| 82 |
+
|
| 83 |
+
您可以通过以下代码轻松调用:
|
| 84 |
+
|
| 85 |
+
You can easily call the model with the following code:
|
| 86 |
+
|
| 87 |
+
```python
|
| 88 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 89 |
+
from transformers.generation import GenerationConfig
|
| 90 |
+
|
| 91 |
+
# Note: The default behavior now has injection attack prevention off.
|
| 92 |
+
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-1_8B", trust_remote_code=True)
|
| 93 |
+
|
| 94 |
+
# use bf16
|
| 95 |
+
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-1_8B", device_map="auto", trust_remote_code=True, bf16=True).eval()
|
| 96 |
+
# use fp16
|
| 97 |
+
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-1_8B", device_map="auto", trust_remote_code=True, fp16=True).eval()
|
| 98 |
+
# use cpu only
|
| 99 |
+
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-1_8B", device_map="cpu", trust_remote_code=True).eval()
|
| 100 |
+
# use auto mode, automatically select precision based on the device.
|
| 101 |
+
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-1_8B", device_map="auto", trust_remote_code=True).eval()
|
| 102 |
+
|
| 103 |
+
# Specify hyperparameters for generation. But if you use transformers>=4.32.0, there is no need to do this.
|
| 104 |
+
# model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-1_8B", trust_remote_code=True)
|
| 105 |
+
|
| 106 |
+
inputs = tokenizer('蒙古国的首都是乌兰巴托(Ulaanbaatar)\n冰岛的首都是雷克雅未克(Reykjavik)\n埃塞俄比亚的首都是', return_tensors='pt')
|
| 107 |
+
inputs = inputs.to(model.device)
|
| 108 |
+
pred = model.generate(**inputs)
|
| 109 |
+
print(tokenizer.decode(pred.cpu()[0], skip_special_tokens=True))
|
| 110 |
+
# 蒙古国的首都是乌兰巴托(Ulaanbaatar)\n冰岛的首都是雷克雅未克(Reykjavik)\n埃塞俄比亚的首都是亚的斯亚贝巴(Addis Ababa)...
|
| 111 |
+
```
|
| 112 |
+
|
| 113 |
+
关于更多的使用说明,请参考我们的[GitHub repo](https://github.com/QwenLM/Qwen)获取更多信息。
|
| 114 |
+
|
| 115 |
+
For more information, please refer to our [GitHub repo](https://github.com/QwenLM/Qwen) for more information.
|
| 116 |
+
<br>
|
| 117 |
+
|
| 118 |
+
## Tokenizer
|
| 119 |
+
|
| 120 |
+
> 注:作为术语的“tokenization”在中文中尚无共识的概念对应,本文档采用英文表达以利说明。
|
| 121 |
+
|
| 122 |
+
基于tiktoken的分词器有别于其他分词器,比如sentencepiece分词器。尤其在微调阶段,需要特别注意特殊token的使用。关于tokenizer的更多信息,以及微调时涉及的相关使用,请参阅[文档](https://github.com/QwenLM/Qwen/blob/main/tokenization_note_zh.md)。
|
| 123 |
+
|
| 124 |
+
Our tokenizer based on tiktoken is different from other tokenizers, e.g., sentencepiece tokenizer. You need to pay attention to special tokens, especially in finetuning. For more detailed information on the tokenizer and related use in fine-tuning, please refer to the [documentation](https://github.com/QwenLM/Qwen/blob/main/tokenization_note.md).
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
## 模型细节 (Model)
|
| 128 |
+
|
| 129 |
+
Qwen-1.8B模型规模基本情况如下所示:
|
| 130 |
+
|
| 131 |
+
The details of the model architecture of Qwen-1.8B are listed as follows:
|
| 132 |
+
|
| 133 |
+
| Hyperparameter | Value |
|
| 134 |
+
|:----------------|:-------|
|
| 135 |
+
| n_layers | 24 |
|
| 136 |
+
| n_heads | 16 |
|
| 137 |
+
| d_model | 2048 |
|
| 138 |
+
| vocab size | 151851 |
|
| 139 |
+
| sequence length | 8192 |
|
| 140 |
+
|
| 141 |
+
在位置编码、FFN激活函数和normalization的实现方式上,我们也采用了目前最流行的做法,
|
| 142 |
+
即RoPE相对位置编码、SwiGLU激活函数、RMSNorm(可选安装flash-attention加速)。
|
| 143 |
+
|
| 144 |
+
在分词器方面,相比目前主流开源模型以中英词表为主,Qwen-1.8B使用了超过15万token大小的词表。 该词表在GPT-4使用的BPE词表`cl100k_base`基础上,对中文、多语言进行了优化,在对中、英、代码数据的高效编解码的基础上,对部分多语言更加友好,方便用户在不扩展词表的情况下对部分语种进行能力增强。
|
| 145 |
+
词表对数字按单个数字位切分。调用较为高效的[tiktoken分词库](https://github.com/openai/tiktoken)进行分词。
|
| 146 |
+
|
| 147 |
+
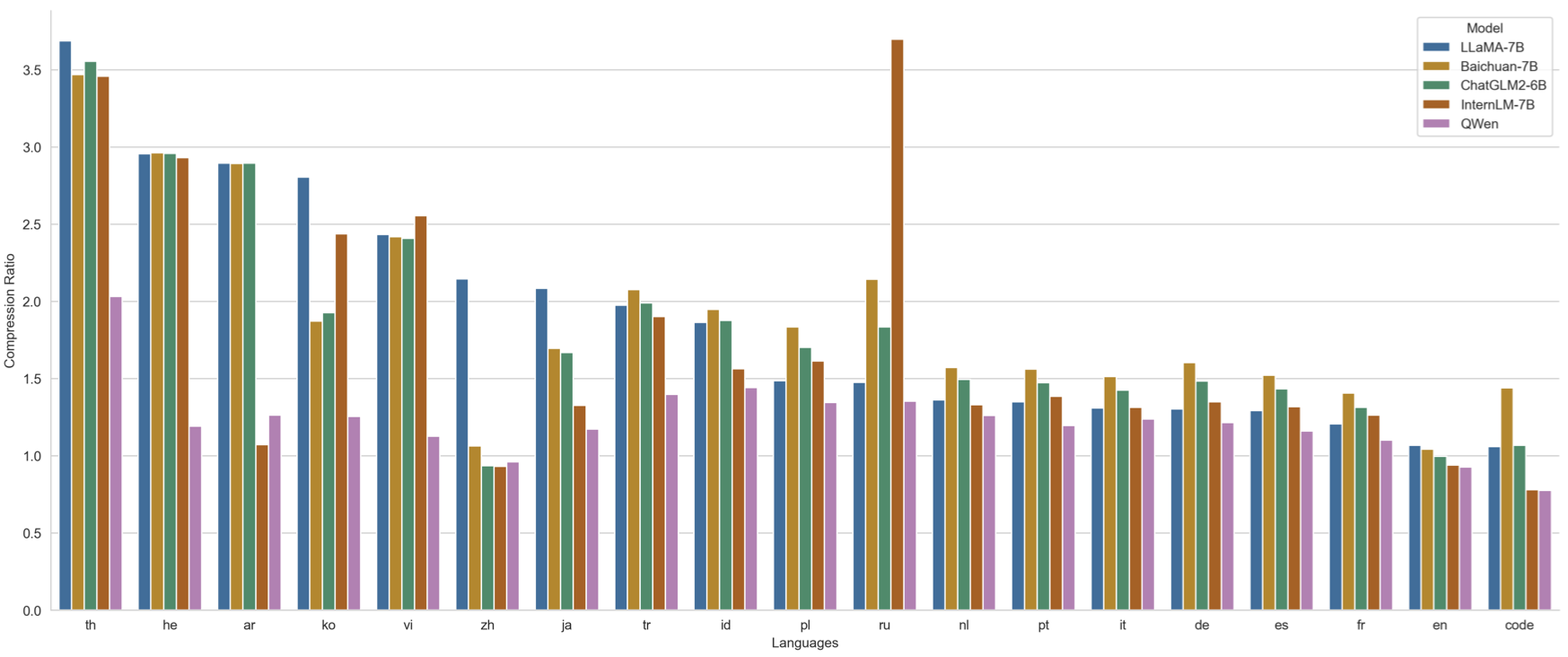
我们从部分语种各随机抽取100万个文档语料,以对比不同模型的编码压缩率(以支持100语种的XLM-R为基准值1,越低越好),具体性能见图。
|
| 148 |
+
|
| 149 |
+
可以看到Qwen-1.8B在保持中英代码高效解码的前提下,对部分使用人群较多的语种(泰语th、希伯来语he、阿拉伯语ar、韩语ko、越南语vi、日语ja、土耳其语tr、印尼语id、波兰语pl、俄语ru、荷兰语nl、葡萄牙语pt、意大利语it、德语de、西班牙语es、法语fr等)上也实现了较高的压缩率,使得模型在这些语种上也具备较强的可扩展性和较高的训练和推理效率。
|
| 150 |
+
|
| 151 |
+
在预训练数据方面,Qwen-1.8B模型一方面利用了部分开源通用语料,
|
| 152 |
+
另一方面也积累了海量全网语料以及高质量文本内容,去重及过滤后的语料超过2.2T tokens。
|
| 153 |
+
囊括全网文本、百科、书籍、代码、数学及各个领域垂类。
|
| 154 |
+
|
| 155 |
+
<p align="center">
|
| 156 |
+
<img src="assets/tokenizer.png" style="width: 1200px"/>
|
| 157 |
+
<p>
|
| 158 |
+
|
| 159 |
+
For position encoding, FFN activation function, and normalization methods, we adopt the prevalent practices, i.e., RoPE relative position encoding, SwiGLU for activation function, and RMSNorm for normalization (optional installation of flash-attention for acceleration).
|
| 160 |
+
|
| 161 |
+
For tokenization, compared to the current mainstream open-source models based on Chinese and English vocabularies, Qwen-1.8B uses a vocabulary of over 150K tokens. It first considers efficient encoding of Chinese, English, and code data, and is also more friendly to multilingual languages, enabling users to directly enhance the capability of some languages without expanding the vocabulary. It segments numbers by single digit, and calls the [tiktoken](https://github.com/openai/tiktoken) tokenizer library for efficient tokenization.
|
| 162 |
+
|
| 163 |
+
We randomly selected 1 million document corpus of each language to test and compare the encoding compression rates of different models (with XLM-R, which supports 100 languages, as the base value 1). The specific performance is shown in the figure above.
|
| 164 |
+
|
| 165 |
+
As can be seen, while ensuring the efficient decoding of Chinese, English, and code, Qwen-1.8B also achieves a high compression rate for many other languages (such as th, he, ar, ko, vi, ja, tr, id, pl, ru, nl, pt, it, de, es, fr etc.), equipping the model with strong scalability as well as high training and inference efficiency in these languages.
|
| 166 |
+
|
| 167 |
+
For pre-training data, on the one hand, Qwen-1.8B uses part of the open-source generic corpus. On the other hand, it uses a massive amount of accumulated web corpus and high-quality text content. The scale of corpus reaches over 2.2T tokens after deduplication and filtration, encompassing web text, encyclopedias, books, code, mathematics, and various domain.
|
| 168 |
+
<br>
|
| 169 |
+
|
| 170 |
+
## 评测效果(Evaluation)
|
| 171 |
+
|
| 172 |
+
### 中文评测(Chinese Evaluation)
|
| 173 |
+
|
| 174 |
+
#### C-Eval
|
| 175 |
+
|
| 176 |
+
[C-Eval](https://arxiv.org/abs/2305.08322)是评测预训练模型中文常识能力的常用测评框架,覆盖人文、社科、理工、其他专业四个大方向共52个学科。
|
| 177 |
+
我们按照标准做法,以开发集样本作为few-shot来源,评价Qwen-1.8B预训练模型的5-shot验证集与测试集准确率。
|
| 178 |
+
|
| 179 |
+
[C-Eval](https://arxiv.org/abs/2305.08322) is a common evaluation benchmark for testing the common sense capability of pre-trained models in Chinese. It covers 52 subjects in four major directions: humanities, social sciences, STEM, and other specialties. According to the standard practice, we use the development set samples as the source of few-shot, to evaluate the 5-shot validation set and test set accuracy of the Qwen-1.8B pre-trained model.
|
| 180 |
+
|
| 181 |
+
在C-Eval验证集、测试集上,Qwen-1.8B模型和其他模型的准确率对比如下:
|
| 182 |
+
|
| 183 |
+
The accuracy comparison of Qwen-1.8B and the other models on the C-Eval validation set is shown as follows:
|
| 184 |
+
|
| 185 |
+
| Model | Avg. (Val) | Avg. (Test) |
|
| 186 |
+
|:--------------|:----------:|:-----------:|
|
| 187 |
+
| Bloom-1B7 | 23.8 | - |
|
| 188 |
+
| Bloomz-1B7 | 29.6 | - |
|
| 189 |
+
| Bloom-3B | 25.8 | - |
|
| 190 |
+
| Bloomz-3B | 32.5 | - |
|
| 191 |
+
| MiLM-1.3B | - | 45.8 |
|
| 192 |
+
| **Qwen-1.8B** | **56.1** | **56.2** |
|
| 193 |
+
|
| 194 |
+
|
| 195 |
+
### 英文评测(English Evaluation)
|
| 196 |
+
|
| 197 |
+
#### MMLU
|
| 198 |
+
|
| 199 |
+
[MMLU](https://arxiv.org/abs/2009.03300)是目前评测英文综合能力最权威的基准评测之一,同样覆盖了不同学科领域、不同难度层级的57个子任务。
|
| 200 |
+
|
| 201 |
+
Qwen-1.8B在MMLU 5-shot准确率表现如下表:
|
| 202 |
+
|
| 203 |
+
[MMLU](https://arxiv.org/abs/2009.03300) is currently one of the most recognized benchmarks for evaluating English comprehension abilities, covering 57 subtasks across different academic fields and difficulty levels. The MMLU 5-shot accuracy performance of Qwen-1.8B is shown in the following table:
|
| 204 |
+
|
| 205 |
+
| Model | Avg. |
|
| 206 |
+
|:--------------|:--------:|
|
| 207 |
+
| GPT-Neo-1.3B | 24.6 |
|
| 208 |
+
| OPT-1.3B | 25.1 |
|
| 209 |
+
| Pythia-1B | 26.6 |
|
| 210 |
+
| Bloom-1.1B | 26.7 |
|
| 211 |
+
| Bloom-1.7B | 27.7 |
|
| 212 |
+
| Bloomz-1.7B | 30.7 |
|
| 213 |
+
| Bloomz-3B | 33.3 |
|
| 214 |
+
| **Qwen-1.8B** | **45.3** |
|
| 215 |
+
|
| 216 |
+
|
| 217 |
+
### 代码评测(Coding Evaluation)
|
| 218 |
+
|
| 219 |
+
我们在[HumanEval](https://github.com/openai/human-eval)(0-shot)上对比预训练模型的代码能力,结果如下:
|
| 220 |
+
|
| 221 |
+
We compared the code capabilities of pre-trained models on [HumanEval](https://github.com/openai/human-eval), and the results are as follows:
|
| 222 |
+
|
| 223 |
+
| Model | Pass@1 |
|
| 224 |
+
|:--------------|:--------:|
|
| 225 |
+
| GPT-Neo-1.3B | 3.66 |
|
| 226 |
+
| GPT-Neo-2.7B | 7.93 |
|
| 227 |
+
| Pythia-1B | 3.67 |
|
| 228 |
+
| Pythia-2.8B | 5.49 |
|
| 229 |
+
| Bloom-1.1B | 2.48 |
|
| 230 |
+
| Bloom-1.7B | 4.03 |
|
| 231 |
+
| Bloom-3B | 6.48 |
|
| 232 |
+
| Bloomz-1.7B | 4.38 |
|
| 233 |
+
| Bloomz-3B | 6.71 |
|
| 234 |
+
| **Qwen-1.8B** | **15.2** |
|
| 235 |
+
|
| 236 |
+
### 数学评测(Mathematics Evaluation)
|
| 237 |
+
|
| 238 |
+
数学能力使用常用的[GSM8K](https://github.com/openai/grade-school-math)数据集(8-shot)评价:
|
| 239 |
+
|
| 240 |
+
We compared the math capabilities of pre-trained models on [GSM8K](https://github.com/openai/grade-school-math) (8-shot), and the results are as follows:
|
| 241 |
+
|
| 242 |
+
| Model | Acc. |
|
| 243 |
+
|:--------------|:--------:|
|
| 244 |
+
| GPT-Neo-1.3B | 1.97 |
|
| 245 |
+
| GPT-Neo-2.7B | 1.74 |
|
| 246 |
+
| Pythia-1B | 2.20 |
|
| 247 |
+
| Pythia-2.8B | 3.11 |
|
| 248 |
+
| Openllama-3B | 3.11 |
|
| 249 |
+
| Bloom-1.1B | 1.82 |
|
| 250 |
+
| Bloom-1.7B | 2.05 |
|
| 251 |
+
| Bloom-3B | 1.82 |
|
| 252 |
+
| Bloomz-1.7B | 2.05 |
|
| 253 |
+
| Bloomz-3B | 3.03 |
|
| 254 |
+
| **Qwen-1.8B** | **32.3** |
|
| 255 |
+
|
| 256 |
+
|
| 257 |
+
## 评测复现(Reproduction)
|
| 258 |
+
|
| 259 |
+
我们提供了评测脚本,方便大家复现模型效果,详见[链接](https://github.com/QwenLM/Qwen/tree/main/eval)。提示:由于硬件和框架造成的舍入误差,复现结果如有小幅波动属于正常现象。
|
| 260 |
+
|
| 261 |
+
We have provided evaluation scripts to reproduce the performance of our model, details as [link](https://github.com/QwenLM/Qwen/tree/main/eval).
|
| 262 |
+
<br>
|
| 263 |
+
|
| 264 |
+
## FAQ
|
| 265 |
+
|
| 266 |
+
如遇到问题,敬请查阅[FAQ](https://github.com/QwenLM/Qwen/blob/main/FAQ_zh.md)以及issue区,如仍无法解决再提交issue。
|
| 267 |
+
|
| 268 |
+
If you meet problems, please refer to [FAQ](https://github.com/QwenLM/Qwen/blob/main/FAQ.md) and the issues first to search a solution before you launch a new issue.
|
| 269 |
+
<br>
|
| 270 |
+
|
| 271 |
+
## 引用 (Citation)
|
| 272 |
+
|
| 273 |
+
如果你觉得我们的工作对你有帮助,欢迎引用!
|
| 274 |
+
|
| 275 |
+
If you find our work helpful, feel free to give us a cite.
|
| 276 |
+
|
| 277 |
+
```
|
| 278 |
+
@article{qwen,
|
| 279 |
+
title={Qwen Technical Report},
|
| 280 |
+
author={Jinze Bai and Shuai Bai and Yunfei Chu and Zeyu Cui and Kai Dang and Xiaodong Deng and Yang Fan and Wenbin Ge and Yu Han and Fei Huang and Binyuan Hui and Luo Ji and Mei Li and Junyang Lin and Runji Lin and Dayiheng Liu and Gao Liu and Chengqiang Lu and Keming Lu and Jianxin Ma and Rui Men and Xingzhang Ren and Xuancheng Ren and Chuanqi Tan and Sinan Tan and Jianhong Tu and Peng Wang and Shijie Wang and Wei Wang and Shengguang Wu and Benfeng Xu and Jin Xu and An Yang and Hao Yang and Jian Yang and Shusheng Yang and Yang Yao and Bowen Yu and Hongyi Yuan and Zheng Yuan and Jianwei Zhang and Xingxuan Zhang and Yichang Zhang and Zhenru Zhang and Chang Zhou and Jingren Zhou and Xiaohuan Zhou and Tianhang Zhu},
|
| 281 |
+
journal={arXiv preprint arXiv:2309.16609},
|
| 282 |
+
year={2023}
|
| 283 |
+
}
|
| 284 |
+
```
|
| 285 |
+
<br>
|
| 286 |
+
|
| 287 |
+
## 使用协议(License Agreement)
|
| 288 |
+
|
| 289 |
+
我们的代码和模型权重对学术研究完全开放。请查看[LICENSE](https://github.com/QwenLM/Qwen/blob/main/Tongyi%20Qianwen%20RESEARCH%20LICENSE%20AGREEMENT)文件了解具体的开源协议细节。如需商用,请联系我们。
|
| 290 |
+
|
| 291 |
+
Our code and checkpoints are open to research purpose. Check the [LICENSE](https://github.com/QwenLM/Qwen/blob/main/Tongyi%20Qianwen%20RESEARCH%20LICENSE%20AGREEMENT) for more details about the license. For commercial use, please contact us.
|
| 292 |
+
<br>
|
| 293 |
+
|
| 294 |
+
## 联系我们(Contact Us)
|
| 295 |
+
|
| 296 |
+
如果你想给我们的研发团队和产品团队留言,欢迎加入我们的微信群、钉钉群以及Discord!同时,也欢迎通过邮件([email protected])联系我们。
|
| 297 |
+
|
| 298 |
+
If you are interested to leave a message to either our research team or product team, join our Discord or WeChat groups! Also, feel free to send an email to [email protected].
|
| 299 |
+
|
assets/logo.jpg
ADDED
|
|
assets/qwen_tokenizer.png
ADDED
|
assets/wechat.png
ADDED

|
cache_autogptq_cuda_256.cpp
ADDED
|
@@ -0,0 +1,198 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#include <torch/all.h>
|
| 2 |
+
#include <torch/python.h>
|
| 3 |
+
#include <c10/cuda/CUDAGuard.h>
|
| 4 |
+
|
| 5 |
+
// adapted from https://github.com/PanQiWei/AutoGPTQ/blob/main/autogptq_extension/cuda_256/autogptq_cuda_256.cpp
|
| 6 |
+
void vecquant8matmul_cuda(
|
| 7 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 8 |
+
torch::Tensor scales, torch::Tensor zeros,
|
| 9 |
+
torch::Tensor g_idx
|
| 10 |
+
);
|
| 11 |
+
|
| 12 |
+
void vecquant8matmul(
|
| 13 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 14 |
+
torch::Tensor scales, torch::Tensor zeros,
|
| 15 |
+
torch::Tensor g_idx
|
| 16 |
+
) {
|
| 17 |
+
const at::cuda::OptionalCUDAGuard device_guard(device_of(vec));
|
| 18 |
+
vecquant8matmul_cuda(vec, mat, mul, scales, zeros, g_idx);
|
| 19 |
+
}
|
| 20 |
+
|
| 21 |
+
void vecquant8matmul_batched_cuda(
|
| 22 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 23 |
+
torch::Tensor scales, torch::Tensor zeros
|
| 24 |
+
);
|
| 25 |
+
|
| 26 |
+
void vecquant8matmul_batched(
|
| 27 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 28 |
+
torch::Tensor scales, torch::Tensor zeros
|
| 29 |
+
) {
|
| 30 |
+
const at::cuda::OptionalCUDAGuard device_guard(device_of(vec));
|
| 31 |
+
vecquant8matmul_batched_cuda(vec, mat, mul, scales, zeros);
|
| 32 |
+
}
|
| 33 |
+
|
| 34 |
+
void vecquant8matmul_batched_column_compression_cuda(
|
| 35 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 36 |
+
torch::Tensor scales, torch::Tensor zeros
|
| 37 |
+
);
|
| 38 |
+
|
| 39 |
+
void vecquant8matmul_batched_column_compression(
|
| 40 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 41 |
+
torch::Tensor scales, torch::Tensor zeros
|
| 42 |
+
) {
|
| 43 |
+
const at::cuda::OptionalCUDAGuard device_guard(device_of(vec));
|
| 44 |
+
vecquant8matmul_batched_column_compression_cuda(vec, mat, mul, scales, zeros);
|
| 45 |
+
}
|
| 46 |
+
|
| 47 |
+
void vecquant4matmul_batched_cuda(
|
| 48 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 49 |
+
torch::Tensor scales, torch::Tensor zeros
|
| 50 |
+
);
|
| 51 |
+
|
| 52 |
+
void vecquant4matmul_batched(
|
| 53 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 54 |
+
torch::Tensor scales, torch::Tensor zeros
|
| 55 |
+
) {
|
| 56 |
+
const at::cuda::OptionalCUDAGuard device_guard(device_of(vec));
|
| 57 |
+
vecquant4matmul_batched_cuda(vec, mat, mul, scales, zeros);
|
| 58 |
+
}
|
| 59 |
+
|
| 60 |
+
void vecquant4matmul_batched_column_compression_cuda(
|
| 61 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 62 |
+
torch::Tensor scales, torch::Tensor zeros
|
| 63 |
+
);
|
| 64 |
+
|
| 65 |
+
void vecquant4matmul_batched_column_compression(
|
| 66 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 67 |
+
torch::Tensor scales, torch::Tensor zeros
|
| 68 |
+
) {
|
| 69 |
+
const at::cuda::OptionalCUDAGuard device_guard(device_of(vec));
|
| 70 |
+
vecquant4matmul_batched_column_compression_cuda(vec, mat, mul, scales, zeros);
|
| 71 |
+
}
|
| 72 |
+
|
| 73 |
+
void vecquant8matmul_batched_old_cuda(
|
| 74 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 75 |
+
torch::Tensor scales, torch::Tensor zeros
|
| 76 |
+
);
|
| 77 |
+
|
| 78 |
+
void vecquant8matmul_batched_old(
|
| 79 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 80 |
+
torch::Tensor scales, torch::Tensor zeros
|
| 81 |
+
) {
|
| 82 |
+
const at::cuda::OptionalCUDAGuard device_guard(device_of(vec));
|
| 83 |
+
vecquant8matmul_batched_old_cuda(vec, mat, mul, scales, zeros);
|
| 84 |
+
}
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
void vecquant4matmul_batched_old_cuda(
|
| 88 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 89 |
+
torch::Tensor scales, torch::Tensor zeros
|
| 90 |
+
);
|
| 91 |
+
|
| 92 |
+
void vecquant4matmul_batched_old(
|
| 93 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 94 |
+
torch::Tensor scales, torch::Tensor zeros
|
| 95 |
+
) {
|
| 96 |
+
const at::cuda::OptionalCUDAGuard device_guard(device_of(vec));
|
| 97 |
+
vecquant4matmul_batched_old_cuda(vec, mat, mul, scales, zeros);
|
| 98 |
+
}
|
| 99 |
+
|
| 100 |
+
void vecquant8matmul_batched_column_compression_old_cuda(
|
| 101 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 102 |
+
torch::Tensor scales, torch::Tensor zeros
|
| 103 |
+
);
|
| 104 |
+
|
| 105 |
+
void vecquant8matmul_batched_column_compression_old(
|
| 106 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 107 |
+
torch::Tensor scales, torch::Tensor zeros
|
| 108 |
+
) {
|
| 109 |
+
const at::cuda::OptionalCUDAGuard device_guard(device_of(vec));
|
| 110 |
+
vecquant8matmul_batched_column_compression_old_cuda(vec, mat, mul, scales, zeros);
|
| 111 |
+
}
|
| 112 |
+
|
| 113 |
+
void vecquant4matmul_batched_column_compression_old_cuda(
|
| 114 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 115 |
+
torch::Tensor scales, torch::Tensor zeros
|
| 116 |
+
);
|
| 117 |
+
|
| 118 |
+
void vecquant4matmul_batched_column_compression_old(
|
| 119 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 120 |
+
torch::Tensor scales, torch::Tensor zeros
|
| 121 |
+
) {
|
| 122 |
+
const at::cuda::OptionalCUDAGuard device_guard(device_of(vec));
|
| 123 |
+
vecquant4matmul_batched_column_compression_old_cuda(vec, mat, mul, scales, zeros);
|
| 124 |
+
}
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
void vecquant8matmul_batched_faster_cuda(
|
| 129 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 130 |
+
torch::Tensor scales, torch::Tensor zeros
|
| 131 |
+
);
|
| 132 |
+
|
| 133 |
+
void vecquant8matmul_batched_faster(
|
| 134 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 135 |
+
torch::Tensor scales, torch::Tensor zeros
|
| 136 |
+
) {
|
| 137 |
+
const at::cuda::OptionalCUDAGuard device_guard(device_of(vec));
|
| 138 |
+
vecquant8matmul_batched_faster_cuda(vec, mat, mul, scales, zeros);
|
| 139 |
+
}
|
| 140 |
+
|
| 141 |
+
|
| 142 |
+
void vecquant8matmul_batched_faster_old_cuda(
|
| 143 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 144 |
+
torch::Tensor scales, torch::Tensor zeros
|
| 145 |
+
);
|
| 146 |
+
|
| 147 |
+
void vecquant8matmul_batched_faster_old(
|
| 148 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 149 |
+
torch::Tensor scales, torch::Tensor zeros
|
| 150 |
+
) {
|
| 151 |
+
const at::cuda::OptionalCUDAGuard device_guard(device_of(vec));
|
| 152 |
+
vecquant8matmul_batched_faster_old_cuda(vec, mat, mul, scales, zeros);
|
| 153 |
+
}
|
| 154 |
+
|
| 155 |
+
void vecquant8matmul_batched_column_compression_faster_cuda(
|
| 156 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 157 |
+
torch::Tensor scales, torch::Tensor zeros
|
| 158 |
+
);
|
| 159 |
+
|
| 160 |
+
void vecquant8matmul_batched_column_compression_faster(
|
| 161 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 162 |
+
torch::Tensor scales, torch::Tensor zeros
|
| 163 |
+
) {
|
| 164 |
+
const at::cuda::OptionalCUDAGuard device_guard(device_of(vec));
|
| 165 |
+
vecquant8matmul_batched_column_compression_faster_cuda(vec, mat, mul, scales, zeros);
|
| 166 |
+
}
|
| 167 |
+
|
| 168 |
+
|
| 169 |
+
void vecquant8matmul_batched_column_compression_faster_old_cuda(
|
| 170 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 171 |
+
torch::Tensor scales, torch::Tensor zeros
|
| 172 |
+
);
|
| 173 |
+
|
| 174 |
+
void vecquant8matmul_batched_column_compression_faster_old(
|
| 175 |
+
torch::Tensor vec, torch::Tensor mat, torch::Tensor mul,
|
| 176 |
+
torch::Tensor scales, torch::Tensor zeros
|
| 177 |
+
) {
|
| 178 |
+
const at::cuda::OptionalCUDAGuard device_guard(device_of(vec));
|
| 179 |
+
vecquant8matmul_batched_column_compression_faster_old_cuda(vec, mat, mul, scales, zeros);
|
| 180 |
+
}
|
| 181 |
+
|
| 182 |
+
|
| 183 |
+
|
| 184 |
+
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
|
| 185 |
+
m.def("vecquant8matmul", &vecquant8matmul, "Vector 8-bit Quantized Matrix Multiplication (CUDA) (desc_act)");
|
| 186 |
+
m.def("vecquant8matmul_batched", &vecquant8matmul_batched, "Vector 8-bit Batched Quantized Matrix Multiplication (CUDA) (desc_act)");
|
| 187 |
+
m.def("vecquant8matmul_batched_old", &vecquant8matmul_batched_old, "Vector 8-bit old Batched Quantized Matrix Multiplication (CUDA) (desc_act)");
|
| 188 |
+
m.def("vecquant8matmul_batched_faster", &vecquant8matmul_batched_faster, "Vector 8-bit old Batched Quantized Matrix Multiplication (CUDA) (desc_act)");
|
| 189 |
+
m.def("vecquant8matmul_batched_faster_old", &vecquant8matmul_batched_faster_old, "Vector 8-bit old Batched Quantized Matrix Multiplication (CUDA) (desc_act)");
|
| 190 |
+
m.def("vecquant4matmul_batched_old", &vecquant4matmul_batched_old, "Vector 4-bit old Batched Quantized Matrix Multiplication (CUDA) (desc_act)");
|
| 191 |
+
m.def("vecquant8matmul_batched_column_compression", &vecquant8matmul_batched_column_compression, "Vector 8-bit Batched Quantized Matrix Multiplication (CUDA) with weight's column compressed (desc_act)");
|
| 192 |
+
m.def("vecquant8matmul_batched_column_compression_old", &vecquant8matmul_batched_column_compression_old, "Vector old 8-bit Batched Quantized Matrix Multiplication (CUDA) with weight's column compressed (desc_act)");
|
| 193 |
+
m.def("vecquant8matmul_batched_column_compression_faster", &vecquant8matmul_batched_column_compression_faster, "Vector old 8-bit Batched Quantized Matrix Multiplication (CUDA) with weight's column compressed (desc_act)");
|
| 194 |
+
m.def("vecquant8matmul_batched_column_compression_faster_old", &vecquant8matmul_batched_column_compression_faster_old, "Vector old 8-bit Batched Quantized Matrix Multiplication (CUDA) with weight's column compressed (desc_act)");
|
| 195 |
+
m.def("vecquant4matmul_batched_column_compression_old", &vecquant4matmul_batched_column_compression_old, "Vector old 4-bit Batched Quantized Matrix Multiplication (CUDA) with weight's column compressed (desc_act)");
|
| 196 |
+
m.def("vecquant4matmul_batched", &vecquant4matmul_batched, "Vector 4-bit Batched Quantized Matrix Multiplication (CUDA) (desc_act)");
|
| 197 |
+
m.def("vecquant4matmul_batched_column_compression", &vecquant4matmul_batched_column_compression, "Vector 4-bit Batched Quantized Matrix Multiplication (CUDA) with weight's column compressed (desc_act)");
|
| 198 |
+
}
|
cache_autogptq_cuda_kernel_256.cu
ADDED
|
@@ -0,0 +1,1708 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#define _CRT_SECURE_NO_WARNINGS
|
| 2 |
+
#include <torch/all.h>
|
| 3 |
+
#include <torch/python.h>
|
| 4 |
+
#include <cuda.h>
|
| 5 |
+
#include <cuda_runtime.h>
|
| 6 |
+
#include <cuda_fp16.h>
|
| 7 |
+
#include <stdint.h>
|
| 8 |
+
|
| 9 |
+
#if (defined(__CUDA_ARCH__) && __CUDA_ARCH__ < 700) || defined(USE_ROCM)
|
| 10 |
+
// adapted from https://github.com/PanQiWei/AutoGPTQ/blob/main/autogptq_extension/cuda_256/autogptq_cuda_kernel_256.cu
|
| 11 |
+
__device__ __forceinline__ void atomicAdd(c10::Half* address, c10::Half val) {
|
| 12 |
+
unsigned int *address_as_ui = reinterpret_cast<unsigned int *>(reinterpret_cast<char *>(address) - (reinterpret_cast<size_t>(address) & 2));
|
| 13 |
+
unsigned int old = *address_as_ui;
|
| 14 |
+
unsigned int assumed;
|
| 15 |
+
|
| 16 |
+
do {
|
| 17 |
+
assumed = old;
|
| 18 |
+
unsigned short hsum = reinterpret_cast<size_t>(address) & 2 ? (old >> 16) : (old & 0xffff);
|
| 19 |
+
hsum += val;
|
| 20 |
+
old = reinterpret_cast<size_t>(address) & 2
|
| 21 |
+
? (old & 0xffff) | (hsum << 16)
|
| 22 |
+
: (old & 0xffff0000) | hsum;
|
| 23 |
+
old = atomicCAS(address_as_ui, assumed, old);
|
| 24 |
+
|
| 25 |
+
// Note: uses integer comparison to avoid hang in case of NaN (since NaN != NaN)
|
| 26 |
+
} while (assumed != old);
|
| 27 |
+
}
|
| 28 |
+
__device__ __forceinline__ void atomicAdd(__half* address, c10::Half val) {
|
| 29 |
+
unsigned int * address_as_ui = (unsigned int *) ((char *)address - ((size_t)address & 2));
|
| 30 |
+
unsigned int old = *address_as_ui;
|
| 31 |
+
unsigned int assumed;
|
| 32 |
+
|
| 33 |
+
do {
|
| 34 |
+
assumed = old;
|
| 35 |
+
__half_raw hsum;
|
| 36 |
+
hsum.x = (size_t)address & 2 ? (old >> 16) : (old & 0xffff);
|
| 37 |
+
half tmpres = __hadd(hsum, val);
|
| 38 |
+
hsum = __half_raw(tmpres);
|
| 39 |
+
old = (size_t)address & 2 ? (old & 0xffff) | (hsum.x << 16) : (old & 0xffff0000) | hsum.x;
|
| 40 |
+
old = atomicCAS(address_as_ui, assumed, old);
|
| 41 |
+
} while (assumed != old);
|
| 42 |
+
}
|
| 43 |
+
#endif
|
| 44 |
+
|
| 45 |
+
template <typename scalar_t>
|
| 46 |
+
__global__ void VecQuant8MatMulKernel(
|
| 47 |
+
const scalar_t* __restrict__ vec,
|
| 48 |
+
const int* __restrict__ mat,
|
| 49 |
+
scalar_t* __restrict__ mul,
|
| 50 |
+
const scalar_t* __restrict__ scales,
|
| 51 |
+
const int* __restrict__ zeros,
|
| 52 |
+
const int* __restrict__ g_idx,
|
| 53 |
+
int batch,
|
| 54 |
+
int vec_height,
|
| 55 |
+
int height,
|
| 56 |
+
int width,
|
| 57 |
+
int zero_width
|
| 58 |
+
);
|
| 59 |
+
|
| 60 |
+
template <typename scalar_t>
|
| 61 |
+
__global__ void VecQuant8BatchMatMulColumnCompressionKernel(
|
| 62 |
+
const scalar_t* __restrict__ vec,
|
| 63 |
+
const int* __restrict__ mat,
|
| 64 |
+
scalar_t* __restrict__ mul,
|
| 65 |
+
const scalar_t* __restrict__ scales,
|
| 66 |
+
const int* __restrict__ zeros,
|
| 67 |
+
int batch,
|
| 68 |
+
int heads,
|
| 69 |
+
int vec_row,
|
| 70 |
+
int height,
|
| 71 |
+
int width
|
| 72 |
+
);
|
| 73 |
+
|
| 74 |
+
template <typename scalar_t>
|
| 75 |
+
__global__ void VecQuant4BatchMatMulColumnCompressionKernel(
|
| 76 |
+
const scalar_t* __restrict__ vec,
|
| 77 |
+
const int* __restrict__ mat,
|
| 78 |
+
scalar_t* __restrict__ mul,
|
| 79 |
+
const scalar_t* __restrict__ scales,
|
| 80 |
+
const int* __restrict__ zeros,
|
| 81 |
+
int batch,
|
| 82 |
+
int heads,
|
| 83 |
+
int vec_row,
|
| 84 |
+
int height,
|
| 85 |
+
int width
|
| 86 |
+
);
|
| 87 |
+
|
| 88 |
+
template <typename scalar_t>
|
| 89 |
+
__global__ void VecQuant8BatchMatMulKernel(
|
| 90 |
+
const scalar_t* __restrict__ vec,
|
| 91 |
+
const int* __restrict__ mat,
|
| 92 |
+
scalar_t* __restrict__ mul,
|
| 93 |
+
const scalar_t* __restrict__ scales,
|
| 94 |
+
const int* __restrict__ zeros,
|
| 95 |
+
int batch,
|
| 96 |
+
int heads,
|
| 97 |
+
int vec_row,
|
| 98 |
+
int vec_height,
|
| 99 |
+
int height,
|
| 100 |
+
int width,
|
| 101 |
+
int zero_width
|
| 102 |
+
);
|
| 103 |
+
|
| 104 |
+
template <typename scalar_t>
|
| 105 |
+
__global__ void VecQuant4BatchMatMulKernel(
|
| 106 |
+
const scalar_t* __restrict__ vec,
|
| 107 |
+
const int* __restrict__ mat,
|
| 108 |
+
scalar_t* __restrict__ mul,
|
| 109 |
+
const scalar_t* __restrict__ scales,
|
| 110 |
+
const int* __restrict__ zeros,
|
| 111 |
+
int batch,
|
| 112 |
+
int heads,
|
| 113 |
+
int vec_row,
|
| 114 |
+
int vec_height,
|
| 115 |
+
int height,
|
| 116 |
+
int width,
|
| 117 |
+
int zero_width
|
| 118 |
+
);
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
template <typename scalar_t>
|
| 123 |
+
__global__ void VecQuant8BatchMatMulKernel_old(
|
| 124 |
+
const scalar_t* __restrict__ vec,
|
| 125 |
+
const uint8_t* __restrict__ mat,
|
| 126 |
+
scalar_t* __restrict__ mul,
|
| 127 |
+
const scalar_t* __restrict__ scales,
|
| 128 |
+
const scalar_t* __restrict__ zeros,
|
| 129 |
+
int batch,
|
| 130 |
+
int heads,
|
| 131 |
+
int vec_row,
|
| 132 |
+
int vec_height,
|
| 133 |
+
int height,
|
| 134 |
+
int width,
|
| 135 |
+
int zero_width
|
| 136 |
+
);
|
| 137 |
+
|
| 138 |
+
__global__ void VecQuant8BatchMatMulKernel_faster(
|
| 139 |
+
const half* __restrict__ vec,
|
| 140 |
+
const uint8_t* __restrict__ mat,
|
| 141 |
+
half* __restrict__ mul,
|
| 142 |
+
const half* __restrict__ scales,
|
| 143 |
+
const half* __restrict__ zeros,
|
| 144 |
+
int batch,
|
| 145 |
+
int heads,
|
| 146 |
+
int vec_row,
|
| 147 |
+
int vec_height,
|
| 148 |
+
int height,
|
| 149 |
+
int width,
|
| 150 |
+
int zero_width
|
| 151 |
+
);
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
__global__ void VecQuant8BatchMatMulKernel_faster_old(
|
| 156 |
+
const half* __restrict__ vec,
|
| 157 |
+
const uint8_t* __restrict__ mat,
|
| 158 |
+
half* __restrict__ mul,
|
| 159 |
+
const half* __restrict__ scales,
|
| 160 |
+
const half* __restrict__ zeros,
|
| 161 |
+
int batch,
|
| 162 |
+
int heads,
|
| 163 |
+
int vec_row,
|
| 164 |
+
int vec_height,
|
| 165 |
+
int height,
|
| 166 |
+
int width
|
| 167 |
+
);
|
| 168 |
+
|
| 169 |
+
|
| 170 |
+
template <typename scalar_t>
|
| 171 |
+
__global__ void VecQuant4BatchMatMulKernel_old(
|
| 172 |
+
const scalar_t* __restrict__ vec,
|
| 173 |
+
const uint8_t* __restrict__ mat,
|
| 174 |
+
scalar_t* __restrict__ mul,
|
| 175 |
+
const scalar_t* __restrict__ scales,
|
| 176 |
+
const scalar_t* __restrict__ zeros,
|
| 177 |
+
int batch,
|
| 178 |
+
int heads,
|
| 179 |
+
int vec_row,
|
| 180 |
+
int vec_height,
|
| 181 |
+
int height,
|
| 182 |
+
int width,
|
| 183 |
+
int zero_width
|
| 184 |
+
);
|
| 185 |
+
|
| 186 |
+
|
| 187 |
+
template <typename scalar_t>
|
| 188 |
+
__global__ void VecQuant8BatchMatMulColumnCompressionKernel_old(
|
| 189 |
+
const scalar_t* __restrict__ vec,
|
| 190 |
+
const uint8_t* __restrict__ mat,
|
| 191 |
+
scalar_t* __restrict__ mul,
|
| 192 |
+
const scalar_t* __restrict__ scales,
|
| 193 |
+
const scalar_t* __restrict__ zeros,
|
| 194 |
+
int batch,
|
| 195 |
+
int heads,
|
| 196 |
+
int vec_row,
|
| 197 |
+
int height,
|
| 198 |
+
int width
|
| 199 |
+
);
|
| 200 |
+
|
| 201 |
+
__global__ void VecQuant8BatchMatMulColumnCompressionKernel_faster(
|
| 202 |
+
const half* __restrict__ vec,
|
| 203 |
+
const uint8_t* __restrict__ mat,
|
| 204 |
+
half* __restrict__ mul,
|
| 205 |
+
const half* __restrict__ scales,
|
| 206 |
+
const half* __restrict__ zeros,
|
| 207 |
+
int batch,
|
| 208 |
+
int heads,
|
| 209 |
+
int vec_row,
|
| 210 |
+
int height,
|
| 211 |
+
int width
|
| 212 |
+
);
|
| 213 |
+
|
| 214 |
+
__global__ void VecQuant8BatchMatMulColumnCompressionKernel_faster_old(
|
| 215 |
+
const half* __restrict__ vec,
|
| 216 |
+
const uint8_t* __restrict__ mat,
|
| 217 |
+
half* __restrict__ mul,
|
| 218 |
+
const half* __restrict__ scales,
|
| 219 |
+
const half* __restrict__ zeros,
|
| 220 |
+
int batch,
|
| 221 |
+
int heads,
|
| 222 |
+
int vec_row,
|
| 223 |
+
int height,
|
| 224 |
+
int width
|
| 225 |
+
);
|
| 226 |
+
|
| 227 |
+
|
| 228 |
+
template <typename scalar_t>
|
| 229 |
+
__global__ void VecQuant4BatchMatMulColumnCompressionKernel_old(
|
| 230 |
+
const scalar_t* __restrict__ vec,
|
| 231 |
+
const uint8_t* __restrict__ mat,
|
| 232 |
+
scalar_t* __restrict__ mul,
|
| 233 |
+
const scalar_t* __restrict__ scales,
|
| 234 |
+
const scalar_t* __restrict__ zeros,
|
| 235 |
+
int batch,
|
| 236 |
+
int heads,
|
| 237 |
+
int vec_row,
|
| 238 |
+
int height,
|
| 239 |
+
int width
|
| 240 |
+
);
|
| 241 |
+
|
| 242 |
+
|
| 243 |
+
__global__ void VecQuant8BatchMatMulKernel_faster(
|
| 244 |
+
const half* __restrict__ vec,
|
| 245 |
+
const uint8_t* __restrict__ mat,
|
| 246 |
+
half* __restrict__ mul,
|
| 247 |
+
const half* __restrict__ scales,
|
| 248 |
+
const half* __restrict__ zeros,
|
| 249 |
+
int batch,
|
| 250 |
+
int heads,
|
| 251 |
+
int vec_row,
|
| 252 |
+
int vec_height,
|
| 253 |
+
int height,
|
| 254 |
+
int width
|
| 255 |
+
);
|
| 256 |
+
|
| 257 |
+
|
| 258 |
+
__global__ void VecQuant8BatchMatMulColumnCompressionKernel_faster(
|
| 259 |
+
const half* __restrict__ vec,
|
| 260 |
+
const uint8_t* __restrict__ mat,
|
| 261 |
+
half* __restrict__ mul,
|
| 262 |
+
const half* __restrict__ scales,
|
| 263 |
+
const half* __restrict__ zeros,
|
| 264 |
+
int batch,
|
| 265 |
+
int heads,
|
| 266 |
+
int vec_row,
|
| 267 |
+
int height,
|
| 268 |
+
int width
|
| 269 |
+
);
|
| 270 |
+
|
| 271 |
+
const int BLOCKWIDTH = 128;
|
| 272 |
+
const int BLOCKHEIGHT8 = 32;
|
| 273 |
+
const int BLOCKHEIGHT4 = 16;
|
| 274 |
+
const int BLOCKHEIGHT_OLD4 = 128;
|
| 275 |
+
//const int BLOCKHEIGHT_OLD8 = 128;
|
| 276 |
+
|
| 277 |
+
__device__ inline unsigned int as_unsigned(int i) {
|
| 278 |
+
return *reinterpret_cast<unsigned int*>(&i);
|
| 279 |
+
}
|
| 280 |
+
|
| 281 |
+
__device__ inline int as_int(int i) {
|
| 282 |
+
return *reinterpret_cast<int*>(&i);
|
| 283 |
+
}
|
| 284 |
+
|
| 285 |
+
void vecquant8matmul_batched_column_compression_cuda(
|
| 286 |
+
torch::Tensor vec,
|
| 287 |
+
torch::Tensor mat,
|
| 288 |
+
torch::Tensor mul,
|
| 289 |
+
torch::Tensor scales,
|
| 290 |
+
torch::Tensor zeros
|
| 291 |
+
) {
|
| 292 |
+
int batch = vec.size(0);
|
| 293 |
+
int heads = vec.size(1);
|
| 294 |
+
int vec_row = vec.size(2);
|
| 295 |
+
int height = vec.size(3);
|
| 296 |
+
int width = mat.size(3) * 4;
|
| 297 |
+
|
| 298 |
+
dim3 blocks(
|
| 299 |
+
(height + BLOCKWIDTH - 1) / BLOCKWIDTH,
|
| 300 |
+
(width + BLOCKWIDTH - 1) / BLOCKWIDTH
|
| 301 |
+
);
|
| 302 |
+
dim3 threads(BLOCKWIDTH);
|
| 303 |
+
|
| 304 |
+
AT_DISPATCH_FLOATING_TYPES(
|
| 305 |
+
vec.type(), "vecquant8matmul_batched_cuda", ([&] {
|
| 306 |
+
VecQuant8BatchMatMulColumnCompressionKernel<<<blocks, threads>>>(
|
| 307 |
+
vec.data<scalar_t>(), mat.data<int>(), mul.data<scalar_t>(),
|
| 308 |
+
scales.data<scalar_t>(), zeros.data<int>(),
|
| 309 |
+
batch, heads, vec_row, height, width
|
| 310 |
+
);
|
| 311 |
+
})
|
| 312 |
+
);
|
| 313 |
+
|
| 314 |
+
}
|
| 315 |
+
|
| 316 |
+
template <typename scalar_t>
|
| 317 |
+
__global__ void VecQuant8BatchMatMulColumnCompressionKernel(
|
| 318 |
+
const scalar_t* __restrict__ vec,
|
| 319 |
+
const int* __restrict__ mat,
|
| 320 |
+
scalar_t* __restrict__ mul,
|
| 321 |
+
const scalar_t* __restrict__ scales,
|
| 322 |
+
const int* __restrict__ zeros,
|
| 323 |
+
int batch,
|
| 324 |
+
int heads,
|
| 325 |
+
int vec_row,
|
| 326 |
+
int height,
|
| 327 |
+
int width
|
| 328 |
+
) {
|
| 329 |
+
int weight_total = batch * heads * height * width / 4;
|
| 330 |
+
int input_total = batch * heads * vec_row * height;
|
| 331 |
+
int out_total = batch * heads * vec_row * width;
|
| 332 |
+
int tid = threadIdx.x;
|
| 333 |
+
// h is index of height with step being BLOCKWIDTH
|
| 334 |
+
int h = BLOCKWIDTH * blockIdx.x;
|
| 335 |
+
// w is index of width with step being 1
|
| 336 |
+
int w = BLOCKWIDTH * blockIdx.y + tid;
|
| 337 |
+
if (w >= width && tid >= height) {
|
| 338 |
+
return;
|
| 339 |
+
}
|
| 340 |
+
|
| 341 |
+
__shared__ scalar_t blockvec[BLOCKWIDTH];
|
| 342 |
+
int k;
|
| 343 |
+
scalar_t w_tmp;
|
| 344 |
+
|
| 345 |
+
float weight[BLOCKWIDTH];
|
| 346 |
+
|
| 347 |
+
for (int b = 0; b < batch; ++b){
|
| 348 |
+
for (int head = 0; head < heads; ++head){
|
| 349 |
+
int batch_shift = b * heads + head;
|
| 350 |
+
for (k = 0; k < BLOCKWIDTH && h + k < height; ++k){
|
| 351 |
+
int i_w = (w / 4);
|
| 352 |
+
int w_bit = (w % 4) * 8;
|
| 353 |
+
|
| 354 |
+
int w_index = (batch_shift * height + h + k) * width / 4 + i_w;
|
| 355 |
+
if (w_index >= weight_total || w >= width) {
|
| 356 |
+
weight[k] = 0;
|
| 357 |
+
} else {
|
| 358 |
+
scalar_t scale = scales[batch_shift * height + h + k];
|
| 359 |
+
scalar_t zero = zeros[batch_shift * height + h + k];
|
| 360 |
+
w_tmp = ((as_unsigned(mat[w_index]) >> w_bit) & 0xFF);
|
| 361 |
+
weight[k] = scale * (w_tmp - zero);
|
| 362 |
+
}
|
| 363 |
+
}
|
| 364 |
+
|
| 365 |
+
scalar_t res;
|
| 366 |
+
for (int vr = 0; vr < vec_row; ++vr){
|
| 367 |
+
res = 0;
|
| 368 |
+
int vec_index = (batch_shift * vec_row + vr) * height + blockIdx.x * BLOCKWIDTH + tid;
|
| 369 |
+
if (vec_index < input_total) {
|
| 370 |
+
blockvec[tid] = vec[vec_index];
|
| 371 |
+
} else {
|
| 372 |
+
blockvec[tid] = 0;
|
| 373 |
+
}
|
| 374 |
+
|
| 375 |
+
__syncthreads();
|
| 376 |
+
for (k = 0; k < BLOCKWIDTH && h + k < height; ++k){
|
| 377 |
+
// res is the dot product of BLOCKWIDTH elements (part of width)
|
| 378 |
+
res += weight[k] * blockvec[k];
|
| 379 |
+
}
|
| 380 |
+
// add res to the final result, final matrix shape: (batch, vec_row, width)
|
| 381 |
+
int out_index = (batch_shift * vec_row + vr) * width + w;
|
| 382 |
+
if (out_index < out_total) {
|
| 383 |
+
atomicAdd(&mul[out_index], res);
|
| 384 |
+
}
|
| 385 |
+
__syncthreads();
|
| 386 |
+
}
|
| 387 |
+
}
|
| 388 |
+
}
|
| 389 |
+
}
|
| 390 |
+
|
| 391 |
+
void vecquant8matmul_batched_cuda(
|
| 392 |
+
torch::Tensor vec,
|
| 393 |
+
torch::Tensor mat,
|
| 394 |
+
torch::Tensor mul,
|
| 395 |
+
torch::Tensor scales,
|
| 396 |
+
torch::Tensor zeros
|
| 397 |
+
) {
|
| 398 |
+
int batch = vec.size(0);
|
| 399 |
+
int heads = vec.size(1);
|
| 400 |
+
int vec_row = vec.size(2);
|
| 401 |
+
int vec_height = vec.size(3);
|
| 402 |
+
int height = mat.size(2);
|
| 403 |
+
int width = mat.size(3);
|
| 404 |
+
int zero_width = zeros.size(2);
|
| 405 |
+
|
| 406 |
+
dim3 blocks(
|
| 407 |
+
(height + BLOCKHEIGHT8 - 1) / BLOCKHEIGHT8,
|
| 408 |
+
(width + BLOCKWIDTH - 1) / BLOCKWIDTH
|
| 409 |
+
);
|
| 410 |
+
dim3 threads(BLOCKWIDTH);
|
| 411 |
+
|
| 412 |
+
AT_DISPATCH_FLOATING_TYPES(
|
| 413 |
+
vec.type(), "vecquant8matmul_batched_cuda", ([&] {
|
| 414 |
+
VecQuant8BatchMatMulKernel<<<blocks, threads>>>(
|
| 415 |
+
vec.data<scalar_t>(), mat.data<int>(), mul.data<scalar_t>(),
|
| 416 |
+
scales.data<scalar_t>(), zeros.data<int>(),
|
| 417 |
+
batch, heads, vec_row, vec_height, height, width, zero_width
|
| 418 |
+
);
|
| 419 |
+
})
|
| 420 |
+
);
|
| 421 |
+
|
| 422 |
+
}
|
| 423 |
+
|
| 424 |
+
template <typename scalar_t>
|
| 425 |
+
__global__ void VecQuant8BatchMatMulKernel(
|
| 426 |
+
const scalar_t* __restrict__ vec,
|
| 427 |
+
const int* __restrict__ mat,
|
| 428 |
+
scalar_t* __restrict__ mul,
|
| 429 |
+
const scalar_t* __restrict__ scales,
|
| 430 |
+
const int* __restrict__ zeros,
|
| 431 |
+
int batch,
|
| 432 |
+
int heads,
|
| 433 |
+
int vec_row,
|
| 434 |
+
int vec_height,
|
| 435 |
+
int height,
|
| 436 |
+
int width,
|
| 437 |
+
int zero_width
|
| 438 |
+
) {
|
| 439 |
+
int weight_total = batch * heads * height * width;
|
| 440 |
+
int input_total = batch * heads * vec_row * vec_height;
|
| 441 |
+
int out_total = batch * heads * vec_row * width;
|
| 442 |
+
int tid = threadIdx.x;
|
| 443 |
+
// h is index of height with step being BLOCKHEIGHT8
|
| 444 |
+
int h = BLOCKHEIGHT8 * blockIdx.x;
|
| 445 |
+
// w is index of width with step being 1
|
| 446 |
+
int w = BLOCKWIDTH * blockIdx.y + tid;
|
| 447 |
+
if (w >= width && tid >= vec_height) {
|
| 448 |
+
return;
|
| 449 |
+
}
|
| 450 |
+
|
| 451 |
+
__shared__ scalar_t blockvec[BLOCKWIDTH];
|
| 452 |
+
// i is index of mat of block first row
|
| 453 |
+
int i = width * h + w;
|
| 454 |
+
// if (i >= width * height) {
|
| 455 |
+
// return;
|
| 456 |
+
// }
|
| 457 |
+
int k;
|
| 458 |
+
scalar_t w_tmp;
|
| 459 |
+
|
| 460 |
+
int z_w = w / 4;
|
| 461 |
+
int z_mod = (w % 4) * 8;
|
| 462 |
+
|
| 463 |
+
float weight[BLOCKWIDTH];
|
| 464 |
+
|
| 465 |
+
for (int b = 0; b < batch; ++b){
|
| 466 |
+
for (int head = 0; head < heads; ++head){
|
| 467 |
+
int batch_shift = b * heads + head;
|
| 468 |
+
for (k = 0; k < BLOCKWIDTH && h * 4 + k < vec_height; ++k){
|
| 469 |
+
int k_w = (k / 4);
|
| 470 |
+
int k_bit = (k % 4) * 8;
|
| 471 |
+
|
| 472 |
+
int w_index = batch_shift * height * width + i + (k_w * width);
|
| 473 |
+
if (w_index >= weight_total || w >= width) {
|
| 474 |
+
weight[k] = 0;
|
| 475 |
+
} else {
|
| 476 |
+
scalar_t scale = scales[batch_shift * width + w];
|
| 477 |
+
scalar_t zero;
|
| 478 |
+
if (zero_width == width) {
|
| 479 |
+
zero = zeros[batch_shift * width + w];
|
| 480 |
+
} else {
|
| 481 |
+
zero = scalar_t(((as_unsigned(zeros[batch_shift * zero_width + z_w]) >> z_mod) & 0xFF) + 1);
|
| 482 |
+
}
|
| 483 |
+
w_tmp = ((as_unsigned(mat[w_index]) >> k_bit) & 0xFF);
|
| 484 |
+
weight[k] = scale * (w_tmp - zero);
|
| 485 |
+
}
|
| 486 |
+
}
|
| 487 |
+
|
| 488 |
+
scalar_t res;
|
| 489 |
+
for (int vr = 0; vr < vec_row; ++vr){
|
| 490 |
+
res = 0;
|
| 491 |
+
int vec_index = (batch_shift * vec_row + vr) * vec_height + blockIdx.x * BLOCKWIDTH + tid;
|
| 492 |
+
if (vec_index < input_total) {
|
| 493 |
+
blockvec[tid] = vec[vec_index];
|
| 494 |
+
} else {
|
| 495 |
+
blockvec[tid] = 0;
|
| 496 |
+
}
|
| 497 |
+
|
| 498 |
+
__syncthreads();
|
| 499 |
+
for (k = 0; k < BLOCKWIDTH && h * 4 + k < vec_height; ++k){
|
| 500 |
+
// res is the dot product of BLOCKWIDTH elements (part of width)
|
| 501 |
+
res += weight[k] * blockvec[k];
|
| 502 |
+
}
|
| 503 |
+
// add res to the final result, final matrix shape: (batch, vec_row, width)
|
| 504 |
+
int out_index = (batch_shift * vec_row + vr) * width + w;
|
| 505 |
+
if (out_index < out_total) {
|
| 506 |
+
atomicAdd(&mul[out_index], res);
|
| 507 |
+
}
|
| 508 |
+
__syncthreads();
|
| 509 |
+
}
|
| 510 |
+
}
|
| 511 |
+
}
|
| 512 |
+
}
|
| 513 |
+
|
| 514 |
+
|
| 515 |
+
void vecquant8matmul_cuda(
|
| 516 |
+
torch::Tensor vec,
|
| 517 |
+
torch::Tensor mat,
|
| 518 |
+
torch::Tensor mul,
|
| 519 |
+
torch::Tensor scales,
|
| 520 |
+
torch::Tensor zeros,
|
| 521 |
+
torch::Tensor g_idx
|
| 522 |
+
) {
|
| 523 |
+
int batch = vec.size(0);
|
| 524 |
+
int vec_height = vec.size(1);
|
| 525 |
+
int height = mat.size(0);
|
| 526 |
+
int width = mat.size(1);
|
| 527 |
+
int zero_width = zeros.size(1);
|
| 528 |
+
|
| 529 |
+
dim3 blocks(
|
| 530 |
+
(height + BLOCKHEIGHT8 - 1) / BLOCKHEIGHT8,
|
| 531 |
+
(width + BLOCKWIDTH - 1) / BLOCKWIDTH
|
| 532 |
+
);
|
| 533 |
+
dim3 threads(BLOCKWIDTH);
|
| 534 |
+
|
| 535 |
+
AT_DISPATCH_FLOATING_TYPES(
|
| 536 |
+
vec.type(), "vecquant8matmul_cuda", ([&] {
|
| 537 |
+
VecQuant8MatMulKernel<<<blocks, threads>>>(
|
| 538 |
+
vec.data<scalar_t>(), mat.data<int>(), mul.data<scalar_t>(),
|
| 539 |
+
scales.data<scalar_t>(), zeros.data<int>(), g_idx.data<int>(),
|
| 540 |
+
batch, vec_height, height, width, zero_width
|
| 541 |
+
);
|
| 542 |
+
})
|
| 543 |
+
);
|
| 544 |
+
}
|
| 545 |
+
|
| 546 |
+
template <typename scalar_t>
|
| 547 |
+
__global__ void VecQuant8MatMulKernel(
|
| 548 |
+
const scalar_t* __restrict__ vec,
|
| 549 |
+
const int* __restrict__ mat,
|
| 550 |
+
scalar_t* __restrict__ mul,
|
| 551 |
+
const scalar_t* __restrict__ scales,
|
| 552 |
+
const int* __restrict__ zeros,
|
| 553 |
+
const int* __restrict__ g_idx,
|
| 554 |
+
int batch,
|
| 555 |
+
int vec_height,
|
| 556 |
+
int height,
|
| 557 |
+
int width,
|
| 558 |
+
int zero_width
|
| 559 |
+
) {
|
| 560 |
+
int h = BLOCKHEIGHT8 * blockIdx.x;
|
| 561 |
+
int w = BLOCKWIDTH * blockIdx.y + threadIdx.x;
|
| 562 |
+
|
| 563 |
+
__shared__ scalar_t blockvec[BLOCKWIDTH];
|
| 564 |
+
int i = width * h + w;
|
| 565 |
+
int g_h = h * 4;
|
| 566 |
+
int k;
|
| 567 |
+
unsigned int g;
|
| 568 |
+
scalar_t w_tmp;
|
| 569 |
+
|
| 570 |
+
int z_w = w / 4;
|
| 571 |
+
int z_mod = (w % 4) * 8;
|
| 572 |
+
|
| 573 |
+
float weight[BLOCKWIDTH];
|
| 574 |
+
|
| 575 |
+
for (k = 0; k < BLOCKWIDTH; ++k){
|
| 576 |
+
int k_w = (k / 4);
|
| 577 |
+
int k_bit = (k % 4) * 8;
|
| 578 |
+
|
| 579 |
+
g = as_int(g_idx[g_h + k]);
|
| 580 |
+
scalar_t scale = scales[g * width + w];
|
| 581 |
+
scalar_t zero = scalar_t(((as_unsigned(zeros[g * zero_width + z_w]) >> z_mod) & 0xFF) + 1);
|
| 582 |
+
|
| 583 |
+
w_tmp = ((as_unsigned(mat[i + (k_w * width)]) >> k_bit) & 0xFF);
|
| 584 |
+
|
| 585 |
+
weight[k] = scale * (w_tmp - zero);
|
| 586 |
+
}
|
| 587 |
+
|
| 588 |
+
|
| 589 |
+
scalar_t res;
|
| 590 |
+
for (int b = 0; b < batch; ++b){
|
| 591 |
+
res = 0;
|
| 592 |
+
blockvec[threadIdx.x] = vec[b * vec_height + blockIdx.x * BLOCKWIDTH + threadIdx.x];
|
| 593 |
+
__syncthreads();
|
| 594 |
+
for (k = 0; k < BLOCKWIDTH; ++k){
|
| 595 |
+
res += weight[k] * blockvec[k];
|
| 596 |
+
}
|
| 597 |
+
atomicAdd(&mul[b * width + w], res);
|
| 598 |
+
__syncthreads();
|
| 599 |
+
}
|
| 600 |
+
}
|
| 601 |
+
|
| 602 |
+
|
| 603 |
+
|
| 604 |
+
void vecquant4matmul_batched_cuda(
|
| 605 |
+
torch::Tensor vec,
|
| 606 |
+
torch::Tensor mat,
|
| 607 |
+
torch::Tensor mul,
|
| 608 |
+
torch::Tensor scales,
|
| 609 |
+
torch::Tensor zeros
|
| 610 |
+
) {
|
| 611 |
+
int batch = vec.size(0);
|
| 612 |
+
int heads = vec.size(1);
|
| 613 |
+
int vec_row = vec.size(2);
|
| 614 |
+
int vec_height = vec.size(3);
|
| 615 |
+
int height = mat.size(2);
|
| 616 |
+
int width = mat.size(3);
|
| 617 |
+
int zero_width = zeros.size(2);
|
| 618 |
+
|
| 619 |
+
dim3 blocks(
|
| 620 |
+
(height + BLOCKHEIGHT4 - 1) / BLOCKHEIGHT4,
|
| 621 |
+
(width + BLOCKWIDTH - 1) / BLOCKWIDTH
|
| 622 |
+
);
|
| 623 |
+
dim3 threads(BLOCKWIDTH);
|
| 624 |
+
|
| 625 |
+
AT_DISPATCH_FLOATING_TYPES(
|
| 626 |
+
vec.type(), "vecquant4matmul_batched_cuda", ([&] {
|
| 627 |
+
VecQuant4BatchMatMulKernel<<<blocks, threads>>>(
|
| 628 |
+
vec.data<scalar_t>(), mat.data<int>(), mul.data<scalar_t>(),
|
| 629 |
+
scales.data<scalar_t>(), zeros.data<int>(),
|
| 630 |
+
batch, heads, vec_row, vec_height, height, width, zero_width
|
| 631 |
+
);
|
| 632 |
+
})
|
| 633 |
+
);
|
| 634 |
+
|
| 635 |
+
}
|
| 636 |
+
|
| 637 |
+
template <typename scalar_t>
|
| 638 |
+
__global__ void VecQuant4BatchMatMulKernel(
|
| 639 |
+
const scalar_t* __restrict__ vec,
|
| 640 |
+
const int* __restrict__ mat,
|
| 641 |
+
scalar_t* __restrict__ mul,
|
| 642 |
+
const scalar_t* __restrict__ scales,
|
| 643 |
+
const int* __restrict__ zeros,
|
| 644 |
+
int batch,
|
| 645 |
+
int heads,
|
| 646 |
+
int vec_row,
|
| 647 |
+
int vec_height,
|
| 648 |
+
int height,
|
| 649 |
+
int width,
|
| 650 |
+
int zero_width
|
| 651 |
+
) {
|
| 652 |
+
int weight_total = batch * heads * height * width;
|
| 653 |
+
int input_total = batch * heads * vec_row * vec_height;
|
| 654 |
+
int out_total = batch * heads * vec_row * width;
|
| 655 |
+
int tid = threadIdx.x;
|
| 656 |
+
// h is index of height with step being BLOCKHEIGHT4
|
| 657 |
+
int h = BLOCKHEIGHT4 * blockIdx.x;
|
| 658 |
+
// w is index of width with step being 1
|
| 659 |
+
int w = BLOCKWIDTH * blockIdx.y + tid;
|
| 660 |
+
if (w >= width && tid >= vec_height) {
|
| 661 |
+
return;
|
| 662 |
+
}
|
| 663 |
+
|
| 664 |
+
__shared__ scalar_t blockvec[BLOCKWIDTH];
|
| 665 |
+
// i is index of mat of block first row
|
| 666 |
+
int i = width * h + w;
|
| 667 |
+
int k;
|
| 668 |
+
scalar_t w_tmp;
|
| 669 |
+
|
| 670 |
+
int z_w = w / 8;
|
| 671 |
+
int z_mod = (w % 8) * 4;
|
| 672 |
+
|
| 673 |
+
float weight[BLOCKWIDTH];
|
| 674 |
+
|
| 675 |
+
for (int b = 0; b < batch; ++b){
|
| 676 |
+
for (int head = 0; head < heads; ++head){
|
| 677 |
+
int batch_shift = b * heads + head;
|
| 678 |
+
for (k = 0; k < BLOCKWIDTH && h * 8 + k < vec_height; ++k){
|
| 679 |
+
int k_w = (k / 8);
|
| 680 |
+
int k_bit = (k % 8) * 4;
|
| 681 |
+
|
| 682 |
+
int w_index = batch_shift * height * width + i + (k_w * width);
|
| 683 |
+
if (w_index >= weight_total || w >= width) {
|
| 684 |
+
weight[k] = 0;
|
| 685 |
+
} else {
|
| 686 |
+
scalar_t scale = scales[batch_shift * width + w];
|
| 687 |
+
scalar_t zero;
|
| 688 |
+
if (zero_width == width) {
|
| 689 |
+
zero = zeros[batch_shift * width + w];
|
| 690 |
+
} else {
|
| 691 |
+
zero = scalar_t(((as_unsigned(zeros[batch_shift * zero_width + z_w]) >> z_mod) & 0xF));
|
| 692 |
+
}
|
| 693 |
+
w_tmp = ((as_unsigned(mat[w_index]) >> k_bit) & 0xF);
|
| 694 |
+
weight[k] = scale * (w_tmp - zero);
|
| 695 |
+
}
|
| 696 |
+
}
|
| 697 |
+
|
| 698 |
+
scalar_t res;
|
| 699 |
+
for (int vr = 0; vr < vec_row; ++vr){
|
| 700 |
+
res = 0;
|
| 701 |
+
int vec_index = (batch_shift * vec_row + vr) * vec_height + blockIdx.x * BLOCKWIDTH + tid;
|
| 702 |
+
if (vec_index < input_total) {
|
| 703 |
+
blockvec[tid] = vec[vec_index];
|
| 704 |
+
} else {
|
| 705 |
+
blockvec[tid] = 0;
|
| 706 |
+
}
|
| 707 |
+
|
| 708 |
+
__syncthreads();
|
| 709 |
+
for (k = 0; k < BLOCKWIDTH && h * 8 + k < vec_height; ++k){
|
| 710 |
+
// res is the dot product of BLOCKWIDTH elements (part of width)
|
| 711 |
+
res += weight[k] * blockvec[k];
|
| 712 |
+
}
|
| 713 |
+
// add res to the final result, final matrix shape: (batch, vec_row, width)
|
| 714 |
+
int out_index = (batch_shift * vec_row + vr) * width + w;
|
| 715 |
+
if (out_index < out_total) {
|
| 716 |
+
atomicAdd(&mul[out_index], res);
|
| 717 |
+
}
|
| 718 |
+
__syncthreads();
|
| 719 |
+
}
|
| 720 |
+
}
|
| 721 |
+
}
|
| 722 |
+
}
|
| 723 |
+
|
| 724 |
+
|
| 725 |
+
|
| 726 |
+
void vecquant4matmul_batched_column_compression_cuda(
|
| 727 |
+
torch::Tensor vec,
|
| 728 |
+
torch::Tensor mat,
|
| 729 |
+
torch::Tensor mul,
|
| 730 |
+
torch::Tensor scales,
|
| 731 |
+
torch::Tensor zeros
|
| 732 |
+
) {
|
| 733 |
+
int batch = vec.size(0);
|
| 734 |
+
int heads = vec.size(1);
|
| 735 |
+
int vec_row = vec.size(2);
|
| 736 |
+
int height = vec.size(3);
|
| 737 |
+
int width = mat.size(3) * 8;
|
| 738 |
+
|
| 739 |
+
dim3 blocks(
|
| 740 |
+
(height + BLOCKWIDTH - 1) / BLOCKWIDTH,
|
| 741 |
+
(width + BLOCKWIDTH - 1) / BLOCKWIDTH
|
| 742 |
+
);
|
| 743 |
+
dim3 threads(BLOCKWIDTH);
|
| 744 |
+
|
| 745 |
+
AT_DISPATCH_FLOATING_TYPES(
|
| 746 |
+
vec.type(), "vecquant4matmul_batched_cuda", ([&] {
|
| 747 |
+
VecQuant4BatchMatMulColumnCompressionKernel<<<blocks, threads>>>(
|
| 748 |
+
vec.data<scalar_t>(), mat.data<int>(), mul.data<scalar_t>(),
|
| 749 |
+
scales.data<scalar_t>(), zeros.data<int>(),
|
| 750 |
+
batch, heads, vec_row, height, width
|
| 751 |
+
);
|
| 752 |
+
})
|
| 753 |
+
);
|
| 754 |
+
|
| 755 |
+
}
|
| 756 |
+
|
| 757 |
+
template <typename scalar_t>
|
| 758 |
+
__global__ void VecQuant4BatchMatMulColumnCompressionKernel(
|
| 759 |
+
const scalar_t* __restrict__ vec,
|
| 760 |
+
const int* __restrict__ mat,
|
| 761 |
+
scalar_t* __restrict__ mul,
|
| 762 |
+
const scalar_t* __restrict__ scales,
|
| 763 |
+
const int* __restrict__ zeros,
|
| 764 |
+
int batch,
|
| 765 |
+
int heads,
|
| 766 |
+
int vec_row,
|
| 767 |
+
int height,
|
| 768 |
+
int width
|
| 769 |
+
) {
|
| 770 |
+
int weight_total = batch * heads * height * width / 8;
|
| 771 |
+
int input_total = batch * heads * vec_row * height;
|
| 772 |
+
int out_total = batch * heads * vec_row * width;
|
| 773 |
+
int tid = threadIdx.x;
|
| 774 |
+
// h is index of height with step being BLOCKWIDTH
|
| 775 |
+
int h = BLOCKWIDTH * blockIdx.x;
|
| 776 |
+
// w is index of width with step being 1
|
| 777 |
+
int w = BLOCKWIDTH * blockIdx.y + tid;
|
| 778 |
+
if (w >= width && tid >= height) {
|
| 779 |
+
return;
|
| 780 |
+
}
|
| 781 |
+
|
| 782 |
+
__shared__ scalar_t blockvec[BLOCKWIDTH];
|
| 783 |
+
int k;
|
| 784 |
+
scalar_t w_tmp;
|
| 785 |
+
|
| 786 |
+
float weight[BLOCKWIDTH];
|
| 787 |
+
|
| 788 |
+
for (int b = 0; b < batch; ++b){
|
| 789 |
+
for (int head = 0; head < heads; ++head){
|
| 790 |
+
int batch_shift = b * heads + head;
|
| 791 |
+
for (k = 0; k < BLOCKWIDTH && h + k < height; ++k){
|
| 792 |
+
int i_w = (w / 8);
|
| 793 |
+
int w_bit = (w % 8) * 4;
|
| 794 |
+
|
| 795 |
+
int w_index = (batch_shift * height + h + k) * width / 8 + i_w;
|
| 796 |
+
if (w_index >= weight_total || w >= width) {
|
| 797 |
+
weight[k] = 0;
|
| 798 |
+
} else {
|
| 799 |
+
scalar_t scale = scales[batch_shift * height + h + k];
|
| 800 |
+
scalar_t zero = zeros[batch_shift * height + h + k];
|
| 801 |
+
w_tmp = ((as_unsigned(mat[w_index]) >> w_bit) & 0xF);
|
| 802 |
+
weight[k] = scale * (w_tmp - zero);
|
| 803 |
+
}
|
| 804 |
+
}
|
| 805 |
+
|
| 806 |
+
scalar_t res;
|
| 807 |
+
for (int vr = 0; vr < vec_row; ++vr){
|
| 808 |
+
res = 0;
|
| 809 |
+
int vec_index = (batch_shift * vec_row + vr) * height + blockIdx.x * BLOCKWIDTH + tid;
|
| 810 |
+
if (vec_index < input_total) {
|
| 811 |
+
blockvec[tid] = vec[vec_index];
|
| 812 |
+
} else {
|
| 813 |
+
blockvec[tid] = 0;
|
| 814 |
+
}
|
| 815 |
+
|
| 816 |
+
__syncthreads();
|
| 817 |
+
for (k = 0; k < BLOCKWIDTH && h + k < height; ++k){
|
| 818 |
+
// res is the dot product of BLOCKWIDTH elements (part of width)
|
| 819 |
+
res += weight[k] * blockvec[k];
|
| 820 |
+
}
|
| 821 |
+
// add res to the final result, final matrix shape: (batch, vec_row, width)
|
| 822 |
+
int out_index = (batch_shift * vec_row + vr) * width + w;
|
| 823 |
+
if (out_index < out_total) {
|
| 824 |
+
atomicAdd(&mul[out_index], res);
|
| 825 |
+
}
|
| 826 |
+
__syncthreads();
|
| 827 |
+
}
|
| 828 |
+
}
|
| 829 |
+
}
|
| 830 |
+
}
|
| 831 |
+
|
| 832 |
+
|
| 833 |
+
void vecquant8matmul_batched_old_cuda(
|
| 834 |
+
torch::Tensor vec,
|
| 835 |
+
torch::Tensor mat,
|
| 836 |
+
torch::Tensor mul,
|
| 837 |
+
torch::Tensor scales,
|
| 838 |
+
torch::Tensor zeros
|
| 839 |
+
) {
|
| 840 |
+
int batch = vec.size(0);
|
| 841 |
+
int heads = vec.size(1);
|
| 842 |
+
int vec_row = vec.size(2);
|
| 843 |
+
int vec_height = vec.size(3);
|
| 844 |
+
int height = mat.size(2);
|
| 845 |
+
int width = mat.size(3);
|
| 846 |
+
int zero_width = zeros.size(2);
|
| 847 |
+
|
| 848 |
+
dim3 blocks(
|
| 849 |
+
(height + BLOCKWIDTH - 1) / BLOCKWIDTH,
|
| 850 |
+
(width + BLOCKWIDTH - 1) / BLOCKWIDTH
|
| 851 |
+
);
|
| 852 |
+
dim3 threads(BLOCKWIDTH);
|
| 853 |
+
|
| 854 |
+
AT_DISPATCH_FLOATING_TYPES(
|
| 855 |
+
vec.type(), "vecquant8matmul_batched_old_cuda", ([&] {
|
| 856 |
+
VecQuant8BatchMatMulKernel_old<<<blocks, threads>>>(
|
| 857 |
+
vec.data<scalar_t>(), mat.data<uint8_t>(), mul.data<scalar_t>(),
|
| 858 |
+
scales.data<scalar_t>(), zeros.data<scalar_t>(),
|
| 859 |
+
batch, heads, vec_row, vec_height, height, width, zero_width
|
| 860 |
+
);
|
| 861 |
+
})
|
| 862 |
+
);
|
| 863 |
+
}
|
| 864 |
+
|
| 865 |
+
|
| 866 |
+
template <typename scalar_t>
|
| 867 |
+
__global__ void VecQuant8BatchMatMulKernel_old(
|
| 868 |
+
const scalar_t* __restrict__ vec,
|
| 869 |
+
const uint8_t* __restrict__ mat,
|
| 870 |
+
scalar_t* __restrict__ mul,
|
| 871 |
+
const scalar_t* __restrict__ scales,
|
| 872 |
+
const scalar_t* __restrict__ zeros,
|
| 873 |
+
int batch,
|
| 874 |
+
int heads,
|
| 875 |
+
int vec_row,
|
| 876 |
+
int vec_height,
|
| 877 |
+
int height,
|
| 878 |
+
int width,
|
| 879 |
+
int zero_width
|
| 880 |
+
) {
|
| 881 |
+
int weight_total = batch * heads * height * width;
|
| 882 |
+
int input_total = batch * heads * vec_row * vec_height;
|
| 883 |
+
int out_total = batch * heads * vec_row * width;
|
| 884 |
+
int tid = threadIdx.x;
|
| 885 |
+
// h is index of height with step being BLOCKHEIGHT8
|
| 886 |
+
int h = BLOCKWIDTH * blockIdx.x;
|
| 887 |
+
// w is index of width with step being 1
|
| 888 |
+
int w = BLOCKWIDTH * blockIdx.y + tid;
|
| 889 |
+
if (w >= width && tid >= vec_height) {
|
| 890 |
+
return;
|
| 891 |
+
}
|
| 892 |
+
|
| 893 |
+
__shared__ scalar_t blockvec[BLOCKWIDTH];
|
| 894 |
+
// i is index of mat of block first row
|
| 895 |
+
int i = width * h + w;
|
| 896 |
+
int k;
|
| 897 |
+
scalar_t w_tmp;
|
| 898 |
+
|
| 899 |
+
float weight[BLOCKWIDTH];
|
| 900 |
+
for (int b = 0; b < batch; ++b){
|
| 901 |
+
for (int head = 0; head < heads; ++head){
|
| 902 |
+
int batch_shift = b * heads + head;
|
| 903 |
+
for (k = 0; k < BLOCKWIDTH && h + k < vec_height; ++k){
|
| 904 |
+
int k_w = k;
|
| 905 |
+
int w_index = batch_shift * height * width + i + (k_w * width);
|
| 906 |
+
if (w_index >= weight_total || w >= width) {
|
| 907 |
+
weight[k] = 0;
|
| 908 |
+
} else {
|
| 909 |
+
scalar_t scale = scales[batch_shift * width + w];
|
| 910 |
+
scalar_t zero = zeros[batch_shift * width + w];
|
| 911 |
+
w_tmp = as_unsigned(mat[w_index]);
|
| 912 |
+
weight[k] = scale * (w_tmp - zero);
|
| 913 |
+
}
|
| 914 |
+
}
|
| 915 |
+
|
| 916 |
+
scalar_t res;
|
| 917 |
+
for (int vr = 0; vr < vec_row; ++vr){
|
| 918 |
+
res = 0;
|
| 919 |
+
int vec_index = (batch_shift * vec_row + vr) * vec_height + blockIdx.x * BLOCKWIDTH + tid;
|
| 920 |
+
if (vec_index < input_total) {
|
| 921 |
+
blockvec[tid] = vec[vec_index];
|
| 922 |
+
} else {
|
| 923 |
+
blockvec[tid] = 0;
|
| 924 |
+
}
|
| 925 |
+
|
| 926 |
+
__syncthreads();
|
| 927 |
+
for (k = 0; k < BLOCKWIDTH && h + k < vec_height; ++k){
|
| 928 |
+
// res is the dot product of BLOCKWIDTH elements (part of width)
|
| 929 |
+
res += weight[k] * blockvec[k];
|
| 930 |
+
}
|
| 931 |
+
// add res to the final result, final matrix shape: (batch, vec_row, width)
|
| 932 |
+
int out_index = (batch_shift * vec_row + vr) * width + w;
|
| 933 |
+
if (out_index < out_total) {
|
| 934 |
+
atomicAdd(&mul[out_index], res);
|
| 935 |
+
}
|
| 936 |
+
__syncthreads();
|
| 937 |
+
}
|
| 938 |
+
}
|
| 939 |
+
}
|
| 940 |
+
}
|
| 941 |
+
|
| 942 |
+
|
| 943 |
+
|
| 944 |
+
void vecquant8matmul_batched_faster_cuda(
|
| 945 |
+
torch::Tensor vec,
|
| 946 |
+
torch::Tensor mat,
|
| 947 |
+
torch::Tensor mul,
|
| 948 |
+
torch::Tensor scales,
|
| 949 |
+
torch::Tensor zeros
|
| 950 |
+
) {
|
| 951 |
+
int batch = vec.size(0);
|
| 952 |
+
int heads = vec.size(1);
|
| 953 |
+
int vec_row = vec.size(2);
|
| 954 |
+
int vec_height = vec.size(3);
|
| 955 |
+
int height = mat.size(2);
|
| 956 |
+
int width = mat.size(3);
|
| 957 |
+
int zero_width = zeros.size(2);
|
| 958 |
+
|
| 959 |
+
dim3 blocks(
|
| 960 |
+
(height + BLOCKWIDTH - 1) / BLOCKWIDTH,
|
| 961 |
+
(width + BLOCKWIDTH - 1) / BLOCKWIDTH
|
| 962 |
+
);
|
| 963 |
+
dim3 threads(BLOCKWIDTH);
|
| 964 |
+
|
| 965 |
+
VecQuant8BatchMatMulKernel_faster<<<blocks, threads>>>(
|
| 966 |
+
(half*) vec.data_ptr(),
|
| 967 |
+
(uint8_t*) mat.data_ptr(),
|
| 968 |
+
(half*) mul.data_ptr(),
|
| 969 |
+
(half*) scales.data_ptr(),
|
| 970 |
+
(half*) zeros.data_ptr(),
|
| 971 |
+
batch, heads, vec_row, vec_height, height, width, zero_width
|
| 972 |
+
);
|
| 973 |
+
}
|
| 974 |
+
|
| 975 |
+
|
| 976 |
+
|
| 977 |
+
__global__ void VecQuant8BatchMatMulKernel_faster(
|
| 978 |
+
const half* __restrict__ vec,
|
| 979 |
+
const uint8_t* __restrict__ mat,
|
| 980 |
+
half* __restrict__ mul,
|
| 981 |
+
const half* __restrict__ scales,
|
| 982 |
+
const half* __restrict__ zeros,
|
| 983 |
+
int batch,
|
| 984 |
+
int heads,
|
| 985 |
+
int vec_row,
|
| 986 |
+
int vec_height,
|
| 987 |
+
int height,
|
| 988 |
+
int width,
|
| 989 |
+
int zero_width
|
| 990 |
+
) {
|
| 991 |
+
//int weight_total = batch * heads * height * width;
|
| 992 |
+
int input_total = batch * heads * vec_row * vec_height;
|
| 993 |
+
int out_total = batch * heads * vec_row * width;
|
| 994 |
+
int tid = threadIdx.x;
|
| 995 |
+
int h = BLOCKWIDTH * blockIdx.x;
|
| 996 |
+
int w = BLOCKWIDTH * blockIdx.y + tid;
|
| 997 |
+
if (w >= width && tid >= height) {
|
| 998 |
+
return;
|
| 999 |
+
}
|
| 1000 |
+
|
| 1001 |
+
__shared__ float blockvec[BLOCKWIDTH];
|
| 1002 |
+
int i = width * h + w;
|
| 1003 |
+
int k;
|
| 1004 |
+
float w_tmp;
|
| 1005 |
+
|
| 1006 |
+
float weight[BLOCKWIDTH];
|
| 1007 |
+
for (int b = 0; b < batch; ++b){
|
| 1008 |
+
for (int head = 0; head < heads; ++head){
|
| 1009 |
+
int batch_shift = b * heads + head;
|
| 1010 |
+
for (k = 0; k < BLOCKWIDTH && h + k < vec_height; ++k){
|
| 1011 |
+
int k_w = k;
|
| 1012 |
+
int w_index = batch_shift * height * width + i + (k_w * width);
|
| 1013 |
+
float scale = __half2float(scales[batch_shift * width + w]);
|
| 1014 |
+
float zero = __half2float(zeros[batch_shift * width + w]);
|
| 1015 |
+
w_tmp = as_unsigned(mat[w_index]);
|
| 1016 |
+
weight[k] = scale *(w_tmp-zero);
|
| 1017 |
+
}
|
| 1018 |
+
|
| 1019 |
+
float res;
|
| 1020 |
+
for (int vr = 0; vr < vec_row; ++vr){
|
| 1021 |
+
res = 0;
|
| 1022 |
+
int vec_index = (batch_shift * vec_row + vr) * vec_height + blockIdx.x * BLOCKWIDTH + tid;
|
| 1023 |
+
if (vec_index < input_total) {
|
| 1024 |
+
blockvec[tid] = __half2float(vec[vec_index]);
|
| 1025 |
+
} else {
|
| 1026 |
+
blockvec[tid] = 0;
|
| 1027 |
+
}
|
| 1028 |
+
__syncthreads();
|
| 1029 |
+
for (k = 0; k < BLOCKWIDTH && h + k < vec_height; ++k){
|
| 1030 |
+
float temp_res = weight[k]*blockvec[k];
|
| 1031 |
+
res += temp_res;
|
| 1032 |
+
}
|
| 1033 |
+
int out_index = (batch_shift * vec_row + vr) * width + w;
|
| 1034 |
+
if (out_index < out_total) {
|
| 1035 |
+
atomicAdd(&mul[out_index], __float2half(res));
|
| 1036 |
+
}
|
| 1037 |
+
__syncthreads();
|
| 1038 |
+
}
|
| 1039 |
+
}
|
| 1040 |
+
}
|
| 1041 |
+
}
|
| 1042 |
+
|
| 1043 |
+
|
| 1044 |
+
|
| 1045 |
+
|
| 1046 |
+
void vecquant8matmul_batched_column_compression_faster_cuda(
|
| 1047 |
+
torch::Tensor vec,
|
| 1048 |
+
torch::Tensor mat,
|
| 1049 |
+
torch::Tensor mul,
|
| 1050 |
+
torch::Tensor scales,
|
| 1051 |
+
torch::Tensor zeros
|
| 1052 |
+
) {
|
| 1053 |
+
int batch = vec.size(0);
|
| 1054 |
+
int heads = vec.size(1);
|
| 1055 |
+
int vec_row = vec.size(2);
|
| 1056 |
+
int height = vec.size(3);
|
| 1057 |
+
int width = mat.size(3);
|
| 1058 |
+
|
| 1059 |
+
dim3 blocks(
|
| 1060 |
+
(height + BLOCKWIDTH - 1) / BLOCKWIDTH,
|
| 1061 |
+
(width + BLOCKWIDTH - 1) / BLOCKWIDTH
|
| 1062 |
+
);
|
| 1063 |
+
dim3 threads(BLOCKWIDTH);
|
| 1064 |
+
|
| 1065 |
+
VecQuant8BatchMatMulColumnCompressionKernel_faster<<<blocks, threads>>>(
|
| 1066 |
+
(half*) vec.data_ptr(),
|
| 1067 |
+
(uint8_t*) mat.data_ptr(),
|
| 1068 |
+
(half*) mul.data_ptr(),
|
| 1069 |
+
(half*) scales.data_ptr(),
|
| 1070 |
+
(half*) zeros.data_ptr(),
|
| 1071 |
+
batch, heads, vec_row, height, width
|
| 1072 |
+
);
|
| 1073 |
+
|
| 1074 |
+
}
|
| 1075 |
+
|
| 1076 |
+
__global__ void VecQuant8BatchMatMulColumnCompressionKernel_faster(
|
| 1077 |
+
const half* __restrict__ vec,
|
| 1078 |
+
const uint8_t* __restrict__ mat,
|
| 1079 |
+
half* __restrict__ mul,
|
| 1080 |
+
const half* __restrict__ scales,
|
| 1081 |
+
const half* __restrict__ zeros,
|
| 1082 |
+
int batch,
|
| 1083 |
+
int heads,
|
| 1084 |
+
int vec_row,
|
| 1085 |
+
int height,
|
| 1086 |
+
int width
|
| 1087 |
+
) {
|
| 1088 |
+
//int weight_total = batch * heads * height * width;
|
| 1089 |
+
int input_total = batch * heads * vec_row * height;
|
| 1090 |
+
int out_total = batch * heads * vec_row * width;
|
| 1091 |
+
int tid = threadIdx.x;
|
| 1092 |
+
int h = BLOCKWIDTH * blockIdx.x;
|
| 1093 |
+
int w = BLOCKWIDTH * blockIdx.y + tid;
|
| 1094 |
+
if (w >= width && tid >= height) {
|
| 1095 |
+
return;
|
| 1096 |
+
}
|
| 1097 |
+
|
| 1098 |
+
__shared__ float blockvec[BLOCKWIDTH];
|
| 1099 |
+
int k;
|
| 1100 |
+
float w_tmp;
|
| 1101 |
+
float weight[BLOCKWIDTH];
|
| 1102 |
+
|
| 1103 |
+
for (int b = 0; b < batch; ++b){
|
| 1104 |
+
for (int head = 0; head < heads; ++head){
|
| 1105 |
+
int batch_shift = b * heads + head;
|
| 1106 |
+
for (k = 0; k < BLOCKWIDTH; ++k){
|
| 1107 |
+
int w_index = (batch_shift * height + h + k) * width + w;
|
| 1108 |
+
float scale = __half2float(scales[batch_shift * height + h + k]);
|
| 1109 |
+
float zero = __half2float(zeros[batch_shift * height + h + k]);
|
| 1110 |
+
w_tmp = mat[w_index];
|
| 1111 |
+
weight[k] = scale * (w_tmp-zero);
|
| 1112 |
+
}
|
| 1113 |
+
|
| 1114 |
+
float res;
|
| 1115 |
+
for (int vr = 0; vr < vec_row; ++vr){
|
| 1116 |
+
res = 0;
|
| 1117 |
+
int vec_index = (batch_shift * vec_row + vr) * height + blockIdx.x * BLOCKWIDTH + tid;
|
| 1118 |
+
if (vec_index < input_total) {
|
| 1119 |
+
blockvec[tid] = __half2float(vec[vec_index]);
|
| 1120 |
+
} else {
|
| 1121 |
+
blockvec[tid] = 0;
|
| 1122 |
+
}
|
| 1123 |
+
__syncthreads();
|
| 1124 |
+
for (k = 0; k < BLOCKWIDTH; ++k){
|
| 1125 |
+
res += weight[k]*blockvec[k];
|
| 1126 |
+
}
|
| 1127 |
+
int out_index = (batch_shift * vec_row + vr) * width + w;
|
| 1128 |
+
if (out_index < out_total) {
|
| 1129 |
+
atomicAdd(&mul[out_index], __float2half(res));
|
| 1130 |
+
}
|
| 1131 |
+
__syncthreads();
|
| 1132 |
+
}
|
| 1133 |
+
}
|
| 1134 |
+
}
|
| 1135 |
+
}
|
| 1136 |
+
|
| 1137 |
+
|
| 1138 |
+
|
| 1139 |
+
void vecquant8matmul_batched_column_compression_old_cuda(
|
| 1140 |
+
torch::Tensor vec,
|
| 1141 |
+
torch::Tensor mat,
|
| 1142 |
+
torch::Tensor mul,
|
| 1143 |
+
torch::Tensor scales,
|
| 1144 |
+
torch::Tensor zeros
|
| 1145 |
+
) {
|
| 1146 |
+
int batch = vec.size(0);
|
| 1147 |
+
int heads = vec.size(1);
|
| 1148 |
+
int vec_row = vec.size(2);
|
| 1149 |
+
int height = vec.size(3);
|
| 1150 |
+
int width = mat.size(3);
|
| 1151 |
+
|
| 1152 |
+
dim3 blocks(
|
| 1153 |
+
(height + BLOCKWIDTH - 1) / BLOCKWIDTH,
|
| 1154 |
+
(width + BLOCKWIDTH - 1) / BLOCKWIDTH
|
| 1155 |
+
);
|
| 1156 |
+
dim3 threads(BLOCKWIDTH);
|
| 1157 |
+
|
| 1158 |
+
AT_DISPATCH_FLOATING_TYPES(
|
| 1159 |
+
vec.type(), "vecquant8matmul_batched_column_compression_old_cuda", ([&] {
|
| 1160 |
+
VecQuant8BatchMatMulColumnCompressionKernel_old<<<blocks, threads>>>(
|
| 1161 |
+
vec.data<scalar_t>(), mat.data<uint8_t>(), mul.data<scalar_t>(),
|
| 1162 |
+
scales.data<scalar_t>(), zeros.data<scalar_t>(),
|
| 1163 |
+
batch, heads, vec_row, height, width
|
| 1164 |
+
);
|
| 1165 |
+
})
|
| 1166 |
+
);
|
| 1167 |
+
|
| 1168 |
+
}
|
| 1169 |
+
|
| 1170 |
+
template <typename scalar_t>
|
| 1171 |
+
__global__ void VecQuant8BatchMatMulColumnCompressionKernel_old(
|
| 1172 |
+
const scalar_t* __restrict__ vec,
|
| 1173 |
+
const uint8_t* __restrict__ mat,
|
| 1174 |
+
scalar_t* __restrict__ mul,
|
| 1175 |
+
const scalar_t* __restrict__ scales,
|
| 1176 |
+
const scalar_t* __restrict__ zeros,
|
| 1177 |
+
int batch,
|
| 1178 |
+
int heads,
|
| 1179 |
+
int vec_row,
|
| 1180 |
+
int height,
|
| 1181 |
+
int width
|
| 1182 |
+
) {
|
| 1183 |
+
int weight_total = batch * heads * height * width;
|
| 1184 |
+
int input_total = batch * heads * vec_row * height;
|
| 1185 |
+
int out_total = batch * heads * vec_row * width;
|
| 1186 |
+
int tid = threadIdx.x;
|
| 1187 |
+
// h is index of height with step being BLOCKWIDTH
|
| 1188 |
+
int h = BLOCKWIDTH * blockIdx.x;
|
| 1189 |
+
// w is index of width with step being 1
|
| 1190 |
+
int w = BLOCKWIDTH * blockIdx.y + tid;
|
| 1191 |
+
if (w >= width && tid >= height) {
|
| 1192 |
+
return;
|
| 1193 |
+
}
|
| 1194 |
+
|
| 1195 |
+
__shared__ scalar_t blockvec[BLOCKWIDTH];
|
| 1196 |
+
int k;
|
| 1197 |
+
scalar_t w_tmp;
|
| 1198 |
+
|
| 1199 |
+
float weight[BLOCKWIDTH];
|
| 1200 |
+
|
| 1201 |
+
for (int b = 0; b < batch; ++b){
|
| 1202 |
+
for (int head = 0; head < heads; ++head){
|
| 1203 |
+
int batch_shift = b * heads + head;
|
| 1204 |
+
for (k = 0; k < BLOCKWIDTH && h + k < height; ++k){
|
| 1205 |
+
int w_index = (batch_shift * height + h + k) * width + w;
|
| 1206 |
+
if (w_index >= weight_total || w >= width) {
|
| 1207 |
+
weight[k] = 0;
|
| 1208 |
+
} else {
|
| 1209 |
+
scalar_t scale = scales[batch_shift * height + h + k];
|
| 1210 |
+
scalar_t zero = zeros[batch_shift * height + h + k];
|
| 1211 |
+
w_tmp = mat[w_index];
|
| 1212 |
+
weight[k] = scale * (w_tmp - zero);
|
| 1213 |
+
}
|
| 1214 |
+
}
|
| 1215 |
+
|
| 1216 |
+
scalar_t res;
|
| 1217 |
+
for (int vr = 0; vr < vec_row; ++vr){
|
| 1218 |
+
res = 0;
|
| 1219 |
+
int vec_index = (batch_shift * vec_row + vr) * height + blockIdx.x * BLOCKWIDTH + tid;
|
| 1220 |
+
if (vec_index < input_total) {
|
| 1221 |
+
blockvec[tid] = vec[vec_index];
|
| 1222 |
+
} else {
|
| 1223 |
+
blockvec[tid] = 0;
|
| 1224 |
+
}
|
| 1225 |
+
|
| 1226 |
+
__syncthreads();
|
| 1227 |
+
for (k = 0; k < BLOCKWIDTH && h + k < height; ++k){
|
| 1228 |
+
// res is the dot product of BLOCKWIDTH elements (part of width)
|
| 1229 |
+
res += weight[k] * blockvec[k];
|
| 1230 |
+
}
|
| 1231 |
+
// add res to the final result, final matrix shape: (batch, vec_row, width)
|
| 1232 |
+
int out_index = (batch_shift * vec_row + vr) * width + w;
|
| 1233 |
+
if (out_index < out_total) {
|
| 1234 |
+
atomicAdd(&mul[out_index], res);
|
| 1235 |
+
}
|
| 1236 |
+
__syncthreads();
|
| 1237 |
+
}
|
| 1238 |
+
}
|
| 1239 |
+
}
|
| 1240 |
+
}
|
| 1241 |
+
|
| 1242 |
+
|
| 1243 |
+
void vecquant4matmul_batched_old_cuda(
|
| 1244 |
+
torch::Tensor vec,
|
| 1245 |
+
torch::Tensor mat,
|
| 1246 |
+
torch::Tensor mul,
|
| 1247 |
+
torch::Tensor scales,
|
| 1248 |
+
torch::Tensor zeros
|
| 1249 |
+
) {
|
| 1250 |
+
int batch = vec.size(0);
|
| 1251 |
+
int heads = vec.size(1);
|
| 1252 |
+
int vec_row = vec.size(2);
|
| 1253 |
+
int vec_height = vec.size(3);
|
| 1254 |
+
int height = mat.size(2);
|
| 1255 |
+
int width = mat.size(3);
|
| 1256 |
+
int zero_width = zeros.size(2);
|
| 1257 |
+
|
| 1258 |
+
dim3 blocks(
|
| 1259 |
+
(height + BLOCKHEIGHT_OLD4 - 1) / BLOCKHEIGHT_OLD4,
|
| 1260 |
+
(width + BLOCKWIDTH - 1) / BLOCKWIDTH
|
| 1261 |
+
);
|
| 1262 |
+
dim3 threads(BLOCKWIDTH);
|
| 1263 |
+
|
| 1264 |
+
AT_DISPATCH_FLOATING_TYPES(
|
| 1265 |
+
vec.type(), "vecquant4matmul_batched_old_cuda", ([&] {
|
| 1266 |
+
VecQuant4BatchMatMulKernel_old<<<blocks, threads>>>(
|
| 1267 |
+
vec.data<scalar_t>(), mat.data<uint8_t>(), mul.data<scalar_t>(),
|
| 1268 |
+
scales.data<scalar_t>(), zeros.data<scalar_t>(),
|
| 1269 |
+
batch, heads, vec_row, vec_height, height, width, zero_width
|
| 1270 |
+
);
|
| 1271 |
+
})
|
| 1272 |
+
);
|
| 1273 |
+
|
| 1274 |
+
}
|
| 1275 |
+
|
| 1276 |
+
template <typename scalar_t>
|
| 1277 |
+
__global__ void VecQuant4BatchMatMulKernel_old(
|
| 1278 |
+
const scalar_t* __restrict__ vec,
|
| 1279 |
+
const uint8_t* __restrict__ mat,
|
| 1280 |
+
scalar_t* __restrict__ mul,
|
| 1281 |
+
const scalar_t* __restrict__ scales,
|
| 1282 |
+
const scalar_t* __restrict__ zeros,
|
| 1283 |
+
int batch,
|
| 1284 |
+
int heads,
|
| 1285 |
+
int vec_row,
|
| 1286 |
+
int vec_height,
|
| 1287 |
+
int height,
|
| 1288 |
+
int width,
|
| 1289 |
+
int zero_width
|
| 1290 |
+
) {
|
| 1291 |
+
int weight_total = batch * heads * height * width;
|
| 1292 |
+
int input_total = batch * heads * vec_row * vec_height;
|
| 1293 |
+
int out_total = batch * heads * vec_row * width;
|
| 1294 |
+
int tid = threadIdx.x;
|
| 1295 |
+
// h is index of height with step being BLOCKHEIGHT_OLD4
|
| 1296 |
+
int h = BLOCKHEIGHT_OLD4 * blockIdx.x;
|
| 1297 |
+
// w is index of width with step being 1
|
| 1298 |
+
int w = BLOCKWIDTH * blockIdx.y + tid;
|
| 1299 |
+
if (w >= width && tid >= vec_height) {
|
| 1300 |
+
return;
|
| 1301 |
+
}
|
| 1302 |
+
|
| 1303 |
+
__shared__ scalar_t blockvec[BLOCKWIDTH];
|
| 1304 |
+
// i is index of mat of block first row
|
| 1305 |
+
int i = width * h + w;
|
| 1306 |
+
int k;
|
| 1307 |
+
scalar_t w_tmp;
|
| 1308 |
+
|
| 1309 |
+
float weight[BLOCKWIDTH];
|
| 1310 |
+
for (int b = 0; b < batch; ++b){
|
| 1311 |
+
for (int head = 0; head < heads; ++head){
|
| 1312 |
+
int batch_shift = b * heads + head;
|
| 1313 |
+
for (k = 0; k < BLOCKWIDTH && h*2 + k < vec_height; ++k){
|
| 1314 |
+
int k_w = (k / 2);
|
| 1315 |
+
int k_bit = (k % 2) * 4;
|
| 1316 |
+
int w_index = batch_shift * height * width + i + (k_w * width);
|
| 1317 |
+
if (w_index >= weight_total || w >= width) {
|
| 1318 |
+
weight[k] = 0;
|
| 1319 |
+
} else {
|
| 1320 |
+
scalar_t scale = scales[batch_shift * width + w];
|
| 1321 |
+
scalar_t zero = zeros[batch_shift * width + w];
|
| 1322 |
+
w_tmp = ((as_unsigned(mat[w_index]) >> k_bit) & 0xF);
|
| 1323 |
+
weight[k] = scale * (w_tmp - zero);
|
| 1324 |
+
}
|
| 1325 |
+
}
|
| 1326 |
+
|
| 1327 |
+
scalar_t res;
|
| 1328 |
+
for (int vr = 0; vr < vec_row; ++vr){
|
| 1329 |
+
res = 0;
|
| 1330 |
+
int vec_index = (batch_shift * vec_row + vr) * vec_height + blockIdx.x * BLOCKWIDTH + tid;
|
| 1331 |
+
if (vec_index < input_total) {
|
| 1332 |
+
blockvec[tid] = vec[vec_index];
|
| 1333 |
+
} else {
|
| 1334 |
+
blockvec[tid] = 0;
|
| 1335 |
+
}
|
| 1336 |
+
|
| 1337 |
+
__syncthreads();
|
| 1338 |
+
for (k = 0; k < BLOCKWIDTH && h*2 + k < vec_height; ++k){
|
| 1339 |
+
// res is the dot product of BLOCKWIDTH elements (part of width)
|
| 1340 |
+
res += weight[k] * blockvec[k];
|
| 1341 |
+
}
|
| 1342 |
+
// add res to the final result, final matrix shape: (batch, vec_row, width)
|
| 1343 |
+
int out_index = (batch_shift * vec_row + vr) * width + w;
|
| 1344 |
+
if (out_index < out_total) {
|
| 1345 |
+
atomicAdd(&mul[out_index], res);
|
| 1346 |
+
}
|
| 1347 |
+
__syncthreads();
|
| 1348 |
+
}
|
| 1349 |
+
}
|
| 1350 |
+
}
|
| 1351 |
+
}
|
| 1352 |
+
|
| 1353 |
+
|
| 1354 |
+
|
| 1355 |
+
|
| 1356 |
+
|
| 1357 |
+
void vecquant4matmul_batched_column_compression_old_cuda(
|
| 1358 |
+
torch::Tensor vec,
|
| 1359 |
+
torch::Tensor mat,
|
| 1360 |
+
torch::Tensor mul,
|
| 1361 |
+
torch::Tensor scales,
|
| 1362 |
+
torch::Tensor zeros
|
| 1363 |
+
) {
|
| 1364 |
+
int batch = vec.size(0);
|
| 1365 |
+
int heads = vec.size(1);
|
| 1366 |
+
int vec_row = vec.size(2);
|
| 1367 |
+
int height = vec.size(3);
|
| 1368 |
+
int width = mat.size(3);
|
| 1369 |
+
|
| 1370 |
+
dim3 blocks(
|
| 1371 |
+
(height + BLOCKHEIGHT_OLD4 - 1) / BLOCKHEIGHT_OLD4,
|
| 1372 |
+
(width + BLOCKWIDTH - 1) / BLOCKWIDTH
|
| 1373 |
+
);
|
| 1374 |
+
dim3 threads(BLOCKWIDTH);
|
| 1375 |
+
|
| 1376 |
+
AT_DISPATCH_FLOATING_TYPES(
|
| 1377 |
+
vec.type(), "vecquant4matmul_batched_column_compression_old_cuda", ([&] {
|
| 1378 |
+
VecQuant4BatchMatMulColumnCompressionKernel_old<<<blocks, threads>>>(
|
| 1379 |
+
vec.data<scalar_t>(), mat.data<uint8_t>(), mul.data<scalar_t>(),
|
| 1380 |
+
scales.data<scalar_t>(), zeros.data<scalar_t>(),
|
| 1381 |
+
batch, heads, vec_row, height, width
|
| 1382 |
+
);
|
| 1383 |
+
})
|
| 1384 |
+
);
|
| 1385 |
+
|
| 1386 |
+
}
|
| 1387 |
+
|
| 1388 |
+
template <typename scalar_t>
|
| 1389 |
+
__global__ void VecQuant4BatchMatMulColumnCompressionKernel_old(
|
| 1390 |
+
const scalar_t* __restrict__ vec,
|
| 1391 |
+
const uint8_t* __restrict__ mat,
|
| 1392 |
+
scalar_t* __restrict__ mul,
|
| 1393 |
+
const scalar_t* __restrict__ scales,
|
| 1394 |
+
const scalar_t* __restrict__ zeros,
|
| 1395 |
+
int batch,
|
| 1396 |
+
int heads,
|
| 1397 |
+
int vec_row,
|
| 1398 |
+
int height,
|
| 1399 |
+
int width
|
| 1400 |
+
) {
|
| 1401 |
+
int weight_total = batch * heads * height * width;
|
| 1402 |
+
int input_total = batch * heads * vec_row * height;
|
| 1403 |
+
int out_total = batch * heads * vec_row * width;
|
| 1404 |
+
int tid = threadIdx.x;
|
| 1405 |
+
// h is index of height with step being BLOCKWIDTH
|
| 1406 |
+
int h = BLOCKHEIGHT_OLD4 * blockIdx.x;
|
| 1407 |
+
// w is index of width with step being 1
|
| 1408 |
+
int w = BLOCKWIDTH * blockIdx.y + tid;
|
| 1409 |
+
if (w >= width && tid >= height) {
|
| 1410 |
+
return;
|
| 1411 |
+
}
|
| 1412 |
+
|
| 1413 |
+
__shared__ scalar_t blockvec[BLOCKWIDTH];
|
| 1414 |
+
int k;
|
| 1415 |
+
scalar_t w_tmp;
|
| 1416 |
+
|
| 1417 |
+
float weight[BLOCKWIDTH];
|
| 1418 |
+
|
| 1419 |
+
for (int b = 0; b < batch; ++b){
|
| 1420 |
+
for (int head = 0; head < heads; ++head){
|
| 1421 |
+
int batch_shift = b * heads + head;
|
| 1422 |
+
for (k = 0; k < BLOCKWIDTH && h*2 + k < height; ++k){
|
| 1423 |
+
int k_w = (k / 2);
|
| 1424 |
+
int k_bit = (k % 2) * 4;
|
| 1425 |
+
int w_index = (batch_shift * height + h + k) * width + k_w;
|
| 1426 |
+
if (w_index >= weight_total || w >= width) {
|
| 1427 |
+
weight[k] = 0;
|
| 1428 |
+
} else {
|
| 1429 |
+
scalar_t scale = scales[batch_shift * height + h + k];
|
| 1430 |
+
scalar_t zero = zeros[batch_shift * height + h + k];
|
| 1431 |
+
w_tmp = ((as_unsigned(mat[w_index]) >> k_bit) & 0xF);
|
| 1432 |
+
weight[k] = scale * (w_tmp - zero);
|
| 1433 |
+
}
|
| 1434 |
+
}
|
| 1435 |
+
|
| 1436 |
+
scalar_t res;
|
| 1437 |
+
for (int vr = 0; vr < vec_row; ++vr){
|
| 1438 |
+
res = 0;
|
| 1439 |
+
int vec_index = (batch_shift * vec_row + vr) * height + blockIdx.x * BLOCKWIDTH + tid;
|
| 1440 |
+
if (vec_index < input_total) {
|
| 1441 |
+
blockvec[tid] = vec[vec_index];
|
| 1442 |
+
} else {
|
| 1443 |
+
blockvec[tid] = 0;
|
| 1444 |
+
}
|
| 1445 |
+
|
| 1446 |
+
__syncthreads();
|
| 1447 |
+
for (k = 0; k < BLOCKWIDTH && h*2 + k < height; ++k){
|
| 1448 |
+
// res is the dot product of BLOCKWIDTH elements (part of width)
|
| 1449 |
+
res += weight[k] * blockvec[k];
|
| 1450 |
+
}
|
| 1451 |
+
// add res to the final result, final matrix shape: (batch, vec_row, width)
|
| 1452 |
+
int out_index = (batch_shift * vec_row + vr) * width + w;
|
| 1453 |
+
if (out_index < out_total) {
|
| 1454 |
+
atomicAdd(&mul[out_index], res);
|
| 1455 |
+
}
|
| 1456 |
+
__syncthreads();
|
| 1457 |
+
}
|
| 1458 |
+
}
|
| 1459 |
+
}
|
| 1460 |
+
}
|
| 1461 |
+
|
| 1462 |
+
|
| 1463 |
+
|
| 1464 |
+
|
| 1465 |
+
|
| 1466 |
+
void vecquant8matmul_batched_faster_old_cuda(
|
| 1467 |
+
torch::Tensor vec,
|
| 1468 |
+
torch::Tensor mat,
|
| 1469 |
+
torch::Tensor mul,
|
| 1470 |
+
torch::Tensor scales,
|
| 1471 |
+
torch::Tensor zeros
|
| 1472 |
+
) {
|
| 1473 |
+
int batch = vec.size(0);
|
| 1474 |
+
int heads = vec.size(1);
|
| 1475 |
+
int vec_row = vec.size(2);
|
| 1476 |
+
int vec_height = vec.size(3);
|
| 1477 |
+
int height = mat.size(2);
|
| 1478 |
+
int width = mat.size(3);
|
| 1479 |
+
|
| 1480 |
+
dim3 blocks(
|
| 1481 |
+
(height + BLOCKWIDTH - 1) / BLOCKWIDTH,
|
| 1482 |
+
(width + BLOCKWIDTH - 1) / BLOCKWIDTH
|
| 1483 |
+
);
|
| 1484 |
+
dim3 threads(BLOCKWIDTH);
|
| 1485 |
+
|
| 1486 |
+
VecQuant8BatchMatMulKernel_faster_old<<<blocks, threads>>>(
|
| 1487 |
+
(half*) vec.data_ptr(),
|
| 1488 |
+
(uint8_t*) mat.data_ptr(),
|
| 1489 |
+
(half*) mul.data_ptr(),
|
| 1490 |
+
(half*) scales.data_ptr(),
|
| 1491 |
+
(half*) zeros.data_ptr(),
|
| 1492 |
+
batch, heads, vec_row, vec_height, height, width
|
| 1493 |
+
);
|
| 1494 |
+
}
|
| 1495 |
+
|
| 1496 |
+
|
| 1497 |
+
__global__ void VecQuant8BatchMatMulKernel_faster_old(
|
| 1498 |
+
const half* __restrict__ vec,
|
| 1499 |
+
const uint8_t* __restrict__ mat,
|
| 1500 |
+
half* __restrict__ mul,
|
| 1501 |
+
const half* __restrict__ scales,
|
| 1502 |
+
const half* __restrict__ zeros,
|
| 1503 |
+
int batch,
|
| 1504 |
+
int heads,
|
| 1505 |
+
int vec_row,
|
| 1506 |
+
int vec_height,
|
| 1507 |
+
int height,
|
| 1508 |
+
int width
|
| 1509 |
+
) {
|
| 1510 |
+
int weight_total = batch * heads * height * width;
|
| 1511 |
+
int input_total = batch * heads * vec_row * vec_height;
|
| 1512 |
+
int out_total = batch * heads * vec_row * width;
|
| 1513 |
+
int tid = threadIdx.x;
|
| 1514 |
+
const int BLOCKWIDTH_half = BLOCKWIDTH/2;
|
| 1515 |
+
|
| 1516 |
+
int h = BLOCKWIDTH * blockIdx.x; //head_dim, dim=-1
|
| 1517 |
+
int w = BLOCKWIDTH * blockIdx.y + tid; //seq-len, +0-256 ,dim=-2
|
| 1518 |
+
/*
|
| 1519 |
+
if (w >= width && tid >= vec_height) {
|
| 1520 |
+
return;
|
| 1521 |
+
}
|
| 1522 |
+
*/
|
| 1523 |
+
__shared__ half blockvec[BLOCKWIDTH]; //256
|
| 1524 |
+
int i = width * h + w;
|
| 1525 |
+
int k;
|
| 1526 |
+
|
| 1527 |
+
half w_tmp1 = __float2half(0);
|
| 1528 |
+
half w_tmp2 = __float2half(0);
|
| 1529 |
+
|
| 1530 |
+
half2 weight[BLOCKWIDTH_half];
|
| 1531 |
+
for (int b = 0; b < batch; ++b){
|
| 1532 |
+
for (int head = 0; head < heads; ++head){
|
| 1533 |
+
int batch_shift = b * heads + head;
|
| 1534 |
+
//int zero_index = batch_shift;
|
| 1535 |
+
for (k = 0; k < BLOCKWIDTH_half; ++k){
|
| 1536 |
+
int w_index1 = batch_shift * height * width + i + (2 * k * width); // [batch,head,h+k, w]
|
| 1537 |
+
int w_index2 = batch_shift * height * width + i + ((2 * k + 1) * width);
|
| 1538 |
+
int zero_index = batch_shift * width + w; // [batch,head, w]
|
| 1539 |
+
if (w_index1 >= weight_total || w >= width || (2 * k + h) >= height) {
|
| 1540 |
+
weight[k] = __float2half2_rn(0);
|
| 1541 |
+
} else {
|
| 1542 |
+
float zero_f=__half2float(zeros[zero_index]);
|
| 1543 |
+
float scale_f= __half2float(scales[zero_index]);
|
| 1544 |
+
if (w_index2 >= weight_total){
|
| 1545 |
+
w_tmp1 = __float2half((as_unsigned(mat[w_index1]) -zero_f)*scale_f);
|
| 1546 |
+
w_tmp2 = __float2half(0);
|
| 1547 |
+
weight[k] = __halves2half2(w_tmp1,w_tmp2);
|
| 1548 |
+
//printf("zero_index is %d w is %d height is %d width is %d w_index1 is %d w_tmp1 is %f w_tmp2 is %f zero is %f scale is %f low is %f high is %f \n ",zero_index,w,height, width,w_index1,__half2float(w_tmp1),__half2float(w_tmp2),zero_f,scale_f,__low2float(weight[k]),__high2float(weight[k]));
|
| 1549 |
+
}else{
|
| 1550 |
+
w_tmp1 = __int2half_rn(as_unsigned(mat[w_index1]));
|
| 1551 |
+
w_tmp2 = __int2half_rn(as_unsigned(mat[w_index2]));
|
| 1552 |
+
|
| 1553 |
+
//weight[k] = __hmul2(__hsub2(__halves2half2(w_tmp1,w_tmp2), __halves2half2(zero,zero)),__halves2half2(scale,scale));
|
| 1554 |
+
weight[k] = __hfma2(__halves2half2(w_tmp1,w_tmp2), __float2half2_rn(scale_f), __float2half2_rn(-(scale_f * zero_f)));
|
| 1555 |
+
//printf("zero_index1 is %d zero_index2 is %d k is %d head is %d w is %d h is %d height is %d width is %d w_index1 is %d w_index2 is %d zero is %f scale is %f low is %f high is %f \n ",zero_index1,zero_index2,k,head,w,h,height, width,w_index1,w_index2,__half2float(zero1),__half2float(scale1),__low2float(weight[k]),__high2float(weight[k]));
|
| 1556 |
+
}
|
| 1557 |
+
}
|
| 1558 |
+
}
|
| 1559 |
+
|
| 1560 |
+
|
| 1561 |
+
for (int vr = 0; vr < vec_row; ++vr){
|
| 1562 |
+
float res=0;
|
| 1563 |
+
int vec_index = (batch_shift * vec_row + vr) * height + blockIdx.x * BLOCKWIDTH + tid;
|
| 1564 |
+
int out_index = (batch_shift * vec_row + vr) * width + w;
|
| 1565 |
+
if (vec_index < input_total) {
|
| 1566 |
+
//blockvec[tid] = __half2float(vec[vec_index]);// [batch, head, vr, tid(seq_len dim+)]
|
| 1567 |
+
blockvec[tid] = vec[vec_index];
|
| 1568 |
+
//printf("width is %d height is %d h is %d w is %d vec_index is %d out_index is %d vec_row is %d vec_height is %d,vr is %d tid is %d blockvec is %f\n",width,height, h,w,vec_index,out_index,vec_row,vec_height,vr,tid,blockvec[tid]);
|
| 1569 |
+
} else {
|
| 1570 |
+
blockvec[tid] = __float2half(0);
|
| 1571 |
+
}
|
| 1572 |
+
__syncthreads();
|
| 1573 |
+
if (out_index < out_total) {
|
| 1574 |
+
for (k = 0; k < BLOCKWIDTH_half; ++k){
|
| 1575 |
+
half2 res2 = __hmul2(weight[k],__halves2half2(blockvec[2*k],blockvec[2*k+1]));
|
| 1576 |
+
res += __low2float(res2) + __high2float(res2);
|
| 1577 |
+
}
|
| 1578 |
+
atomicAdd(&mul[out_index], __float2half(res));
|
| 1579 |
+
}
|
| 1580 |
+
__syncthreads();
|
| 1581 |
+
}
|
| 1582 |
+
}
|
| 1583 |
+
}
|
| 1584 |
+
}
|
| 1585 |
+
|
| 1586 |
+
|
| 1587 |
+
void vecquant8matmul_batched_column_compression_faster_old_cuda(
|
| 1588 |
+
torch::Tensor vec, // [batch,heads, seq_q, seq_v]
|
| 1589 |
+
torch::Tensor mat, // [batch,heads, seq_v, head_dim]
|
| 1590 |
+
torch::Tensor mul, // [batch,heads, seq_q,head_dim]
|
| 1591 |
+
torch::Tensor scales, // [batch,heads, head_dim]
|
| 1592 |
+
torch::Tensor zeros
|
| 1593 |
+
) {
|
| 1594 |
+
int batch = vec.size(0);
|
| 1595 |
+
int heads = vec.size(1);
|
| 1596 |
+
int vec_row = vec.size(2); //ql
|
| 1597 |
+
int height = mat.size(2); //vl
|
| 1598 |
+
int width = mat.size(3); //head_dim
|
| 1599 |
+
|
| 1600 |
+
dim3 blocks(
|
| 1601 |
+
(height + BLOCKWIDTH - 1) / BLOCKWIDTH,
|
| 1602 |
+
(width + BLOCKWIDTH - 1) / BLOCKWIDTH
|
| 1603 |
+
);
|
| 1604 |
+
dim3 threads(BLOCKWIDTH);
|
| 1605 |
+
|
| 1606 |
+
VecQuant8BatchMatMulColumnCompressionKernel_faster_old<<<blocks, threads>>>(
|
| 1607 |
+
(half*) vec.data_ptr(),
|
| 1608 |
+
(uint8_t*) mat.data_ptr(),
|
| 1609 |
+
(half*) mul.data_ptr(),
|
| 1610 |
+
(half*) scales.data_ptr(),
|
| 1611 |
+
(half*) zeros.data_ptr(),
|
| 1612 |
+
batch, heads, vec_row, height, width
|
| 1613 |
+
);
|
| 1614 |
+
|
| 1615 |
+
}
|
| 1616 |
+
|
| 1617 |
+
|
| 1618 |
+
__global__ void VecQuant8BatchMatMulColumnCompressionKernel_faster_old(
|
| 1619 |
+
const half* __restrict__ vec, // [batch,heads, seq_q, seq_v]
|
| 1620 |
+
const uint8_t* __restrict__ mat, // [batch,heads, seq_v, head_dim]
|
| 1621 |
+
half* __restrict__ mul, // [batch,heads, seq_q,head_dim]
|
| 1622 |
+
const half* __restrict__ scales, // [batch,heads, seq_v]
|
| 1623 |
+
const half* __restrict__ zeros,
|
| 1624 |
+
int batch,
|
| 1625 |
+
int heads,
|
| 1626 |
+
int vec_row, //seq_q
|
| 1627 |
+
int height, //seq_v
|
| 1628 |
+
int width //head_dim
|
| 1629 |
+
) {
|
| 1630 |
+
int weight_total = batch * heads * height * width;
|
| 1631 |
+
int input_total = batch * heads * vec_row * height;
|
| 1632 |
+
int out_total = batch * heads * vec_row * width;
|
| 1633 |
+
int tid = threadIdx.x;
|
| 1634 |
+
int h = BLOCKWIDTH * blockIdx.x; // vl
|
| 1635 |
+
int w = BLOCKWIDTH * blockIdx.y + tid; //head_dim + block
|
| 1636 |
+
if (w >= width && tid >= height) {
|
| 1637 |
+
return;
|
| 1638 |
+
}
|
| 1639 |
+
__shared__ half blockvec[BLOCKWIDTH];
|
| 1640 |
+
int k;
|
| 1641 |
+
half w_tmp1 = __float2half(0);
|
| 1642 |
+
half w_tmp2 = __float2half(0);
|
| 1643 |
+
int i = width * h + w;
|
| 1644 |
+
const int BLOCKWIDTH_half = BLOCKWIDTH/2;
|
| 1645 |
+
half2 weight[BLOCKWIDTH_half];
|
| 1646 |
+
|
| 1647 |
+
for (int b = 0; b < batch; ++b){
|
| 1648 |
+
for (int head = 0; head < heads; ++head){
|
| 1649 |
+
int batch_shift = b * heads + head;
|
| 1650 |
+
//int zero_index = batch_shift;
|
| 1651 |
+
for (k = 0; k < BLOCKWIDTH_half; ++k){
|
| 1652 |
+
int w_index1 = batch_shift * height * width + i + (2 * k) * width; // [batch,head, h+k, w]
|
| 1653 |
+
int w_index2 = batch_shift * height * width + i + ((2 * k + 1) * width);
|
| 1654 |
+
int zero_index1 = batch_shift * height + h + 2*k; // [batch,head, w]
|
| 1655 |
+
int zero_index2 = batch_shift * height + h + 2*k+1; // [batch,head, w]
|
| 1656 |
+
|
| 1657 |
+
if (w_index1 >= weight_total || (2 * k + h)>=height) {
|
| 1658 |
+
weight[k]=__float2half2_rn(0);
|
| 1659 |
+
} else{
|
| 1660 |
+
//int zero_index = batch_shift + h; // [batch,head, w]
|
| 1661 |
+
//float scale_f1 = __half2float(scales[zero_index1]);
|
| 1662 |
+
//float zero_f1 = __half2float(zeros[zero_index1]);
|
| 1663 |
+
if (w_index2>=weight_total){
|
| 1664 |
+
w_tmp1 = __float2half((as_unsigned(mat[w_index1]) - __half2float(zeros[zero_index1]))* __half2float(scales[zero_index1]));
|
| 1665 |
+
w_tmp2 = __float2half(0);
|
| 1666 |
+
weight[k] = __halves2half2(w_tmp1,w_tmp2);
|
| 1667 |
+
//printf("zero_index is %d k is %d w is %d head is %d height is %d width is %d w_index1 is %d w_tmp1 is %f w_tmp2 is %f zero is %f scale is %f low is %f high is %f \n ",zero_index,k,w,head,height, width,w_index1,__half2float(w_tmp1),__half2float(w_tmp2),zero_f,scale_f,__low2float(weight[k]),__high2float(weight[k]));
|
| 1668 |
+
}else{
|
| 1669 |
+
w_tmp1 = __int2half_rn(as_unsigned(mat[w_index1]));
|
| 1670 |
+
w_tmp2 = __int2half_rn(as_unsigned(mat[w_index2]));
|
| 1671 |
+
half zero1=zeros[zero_index1];
|
| 1672 |
+
half zero2=zeros[zero_index2];
|
| 1673 |
+
half scale1=scales[zero_index1];
|
| 1674 |
+
half scale2=scales[zero_index2];
|
| 1675 |
+
weight[k] = __hmul2(__hsub2(__halves2half2(w_tmp1,w_tmp2), __halves2half2(zero1,zero2)),__halves2half2(scale1,scale2));
|
| 1676 |
+
//weight[k] = __hfma2(__halves2half2(w_tmp1,w_tmp2), __float2half2_rn(scale_f), __float2half2_rn(-(scale_f * zero_f)));
|
| 1677 |
+
//printf("zero_index1 is %d zero_index2 is %d k is %d head is %d w is %d h is %d height is %d width is %d w_index1 is %d w_index2 is %d zero is %f scale is %f low is %f high is %f \n ",zero_index1,zero_index2,k,head,w,h,height, width,w_index1,w_index2,__half2float(zero1),__half2float(scale1),__low2float(weight[k]),__high2float(weight[k]));
|
| 1678 |
+
}
|
| 1679 |
+
}
|
| 1680 |
+
}
|
| 1681 |
+
|
| 1682 |
+
|
| 1683 |
+
for (int vr = 0; vr < vec_row; ++vr){
|
| 1684 |
+
float res=0;
|
| 1685 |
+
int vec_index = (batch_shift * vec_row + vr) * height + blockIdx.x * BLOCKWIDTH + tid;
|
| 1686 |
+
int out_index = (batch_shift * vec_row + vr) * width + w;
|
| 1687 |
+
|
| 1688 |
+
if (vec_index < input_total) {
|
| 1689 |
+
//blockvec[tid] = __half2float(vec[vec_index]);
|
| 1690 |
+
blockvec[tid] = vec[vec_index];
|
| 1691 |
+
//printf("vec_index is %d out_index is %d vec_row is %d ,vr is %d tid is %d blockvec is %f\n",vec_index,out_index,vec_row,vr,tid,blockvec[tid]);
|
| 1692 |
+
} else {
|
| 1693 |
+
blockvec[tid] = __float2half(0);
|
| 1694 |
+
//blockvec[tid] = 0;
|
| 1695 |
+
}
|
| 1696 |
+
__syncthreads();
|
| 1697 |
+
if (out_index < out_total) {
|
| 1698 |
+
for (k = 0; k < BLOCKWIDTH_half; ++k){
|
| 1699 |
+
half2 res2 = __hmul2(weight[k],__halves2half2(blockvec[2*k],blockvec[2*k+1]));
|
| 1700 |
+
res += __low2float(res2) + __high2float(res2);
|
| 1701 |
+
}
|
| 1702 |
+
atomicAdd(&mul[out_index], __float2half(res));
|
| 1703 |
+
}
|
| 1704 |
+
__syncthreads();
|
| 1705 |
+
}
|
| 1706 |
+
}
|
| 1707 |
+
}
|
| 1708 |
+
}
|
modeling_qwen.py
CHANGED
|
@@ -13,7 +13,6 @@ import torch
|
|
| 13 |
import torch.nn.functional as F
|
| 14 |
import torch.utils.checkpoint
|
| 15 |
import warnings
|
| 16 |
-
from torch.cuda.amp import autocast
|
| 17 |
|
| 18 |
from torch.nn import CrossEntropyLoss
|
| 19 |
from transformers import PreTrainedTokenizer, GenerationConfig, StoppingCriteriaList
|
|
@@ -79,9 +78,10 @@ We detect you have activated flash attention support, but running model computat
|
|
| 79 |
apply_rotary_emb_func = None
|
| 80 |
rms_norm = None
|
| 81 |
flash_attn_unpadded_func = None
|
|
|
|
| 82 |
|
| 83 |
def _import_flash_attn():
|
| 84 |
-
global apply_rotary_emb_func, rms_norm, flash_attn_unpadded_func
|
| 85 |
try:
|
| 86 |
from flash_attn.layers.rotary import apply_rotary_emb_func as __apply_rotary_emb_func
|
| 87 |
apply_rotary_emb_func = __apply_rotary_emb_func
|
|
@@ -102,14 +102,18 @@ def _import_flash_attn():
|
|
| 102 |
|
| 103 |
try:
|
| 104 |
import flash_attn
|
|
|
|
| 105 |
if not hasattr(flash_attn, '__version__'):
|
| 106 |
from flash_attn.flash_attn_interface import flash_attn_unpadded_func as __flash_attn_unpadded_func
|
| 107 |
else:
|
| 108 |
if int(flash_attn.__version__.split(".")[0]) >= 2:
|
|
|
|
|
|
|
| 109 |
from flash_attn.flash_attn_interface import flash_attn_varlen_func as __flash_attn_unpadded_func
|
| 110 |
else:
|
| 111 |
from flash_attn.flash_attn_interface import flash_attn_unpadded_func as __flash_attn_unpadded_func
|
| 112 |
flash_attn_unpadded_func = __flash_attn_unpadded_func
|
|
|
|
| 113 |
except ImportError:
|
| 114 |
logger.warn(
|
| 115 |
"Warning: import flash_attn fail, please install FlashAttention to get higher efficiency "
|
|
@@ -182,6 +186,11 @@ class FlashSelfAttention(torch.nn.Module):
|
|
| 182 |
seqlen_k = k.shape[1]
|
| 183 |
seqlen_out = seqlen_q
|
| 184 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 185 |
q, k, v = [rearrange(x, "b s ... -> (b s) ...") for x in [q, k, v]]
|
| 186 |
cu_seqlens_q = torch.arange(
|
| 187 |
0,
|
|
@@ -311,7 +320,7 @@ class QWenAttention(nn.Module):
|
|
| 311 |
warnings.warn("Failed to import KV cache kernels.")
|
| 312 |
self.cache_kernels = None
|
| 313 |
|
| 314 |
-
def _attn(self, query, key, value,
|
| 315 |
device = query.device
|
| 316 |
if self.use_cache_quantization:
|
| 317 |
qk, qk_scale, qk_zero = key
|
|
@@ -336,26 +345,13 @@ class QWenAttention(nn.Module):
|
|
| 336 |
size_temp = value[0].size(-1)
|
| 337 |
else:
|
| 338 |
size_temp = value.size(-1)
|
| 339 |
-
attn_weights = attn_weights /
|
| 340 |
-
|
| 341 |
-
size_temp ** 0.5,
|
| 342 |
-
dtype=attn_weights.dtype,
|
| 343 |
-
device=attn_weights.device,
|
| 344 |
-
)
|
| 345 |
-
if self.use_cache_quantization:
|
| 346 |
-
query_length, key_length = query.size(-2), key[0].size(-2)
|
| 347 |
-
else:
|
| 348 |
-
query_length, key_length = query.size(-2), key.size(-2)
|
| 349 |
-
causal_mask = registered_causal_mask[
|
| 350 |
-
:, :, key_length - query_length : key_length, :key_length
|
| 351 |
-
]
|
| 352 |
mask_value = torch.finfo(attn_weights.dtype).min
|
| 353 |
-
|
| 354 |
-
attn_weights.
|
| 355 |
-
|
| 356 |
-
|
| 357 |
-
causal_mask, attn_weights.to(attn_weights.dtype), mask_value
|
| 358 |
-
)
|
| 359 |
|
| 360 |
if attention_mask is not None:
|
| 361 |
attn_weights = attn_weights + attention_mask
|
|
@@ -482,7 +478,8 @@ class QWenAttention(nn.Module):
|
|
| 482 |
else:
|
| 483 |
present = None
|
| 484 |
|
| 485 |
-
if self.
|
|
|
|
| 486 |
if self.use_cache_quantization:
|
| 487 |
seq_start = key[0].size(2) - query.size(1)
|
| 488 |
seq_end = key[0].size(2)
|
|
@@ -501,15 +498,19 @@ class QWenAttention(nn.Module):
|
|
| 501 |
q, k, v = query, key, value
|
| 502 |
attn_output = self.core_attention_flash(q, k, v, attention_mask=attention_mask)
|
| 503 |
else:
|
| 504 |
-
|
| 505 |
-
|
| 506 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 507 |
query = query.permute(0, 2, 1, 3)
|
| 508 |
if not self.use_cache_quantization:
|
| 509 |
key = key.permute(0, 2, 1, 3)
|
| 510 |
value = value.permute(0, 2, 1, 3)
|
| 511 |
if (
|
| 512 |
-
|
| 513 |
and self.use_flash_attn
|
| 514 |
and flash_attn_unpadded_func is not None
|
| 515 |
and not self.is_fp32
|
|
@@ -518,13 +519,12 @@ class QWenAttention(nn.Module):
|
|
| 518 |
raise Exception(_ERROR_INPUT_CPU_QUERY_WITH_FLASH_ATTN_ACTIVATED)
|
| 519 |
|
| 520 |
if not self.use_cache_quantization and SUPPORT_TORCH2:
|
| 521 |
-
causal_mask = registered_causal_mask[
|
| 522 |
-
:, :, key.size(-2) - query.size(-2): key.size(-2), :key.size(-2)
|
| 523 |
-
]
|
| 524 |
if attention_mask is not None:
|
| 525 |
attention_mask = attention_mask.expand(
|
| 526 |
-1, -1, causal_mask.size(2), -1
|
| 527 |
-
)
|
|
|
|
|
|
|
| 528 |
else:
|
| 529 |
attention_mask = causal_mask
|
| 530 |
attn_output = F.scaled_dot_product_attention(
|
|
@@ -533,7 +533,7 @@ class QWenAttention(nn.Module):
|
|
| 533 |
attn_weight = None
|
| 534 |
else:
|
| 535 |
attn_output, attn_weight = self._attn(
|
| 536 |
-
query, key, value,
|
| 537 |
)
|
| 538 |
context_layer = self._merge_heads(
|
| 539 |
attn_output, self.num_heads, self.head_dim
|
|
@@ -549,6 +549,8 @@ class QWenAttention(nn.Module):
|
|
| 549 |
and not self.is_fp32
|
| 550 |
):
|
| 551 |
raise ValueError("Cannot output attentions while using flash-attn")
|
|
|
|
|
|
|
| 552 |
else:
|
| 553 |
outputs += (attn_weight,)
|
| 554 |
|
|
@@ -574,6 +576,7 @@ class QWenMLP(nn.Module):
|
|
| 574 |
output = self.c_proj(intermediate_parallel)
|
| 575 |
return output
|
| 576 |
|
|
|
|
| 577 |
class QWenBlock(nn.Module):
|
| 578 |
def __init__(self, config):
|
| 579 |
super().__init__()
|
|
@@ -642,6 +645,7 @@ class QWenPreTrainedModel(PreTrainedModel):
|
|
| 642 |
is_parallelizable = False
|
| 643 |
supports_gradient_checkpointing = True
|
| 644 |
_no_split_modules = ["QWenBlock"]
|
|
|
|
| 645 |
|
| 646 |
def __init__(self, *inputs, **kwargs):
|
| 647 |
super().__init__(*inputs, **kwargs)
|
|
@@ -933,11 +937,6 @@ class QWenLMHeadModel(QWenPreTrainedModel):
|
|
| 933 |
assert (
|
| 934 |
config.bf16 + config.fp16 + config.fp32 <= 1
|
| 935 |
), "Only one of \"bf16\", \"fp16\", \"fp32\" can be true"
|
| 936 |
-
logger.warn(
|
| 937 |
-
"Warning: please make sure that you are using the latest codes and checkpoints, "
|
| 938 |
-
"especially if you used Qwen-7B before 09.25.2023."
|
| 939 |
-
"请使用最新模型和代码,尤其如果你在9月25日前已经开始使用Qwen-7B,千万注意不要使用错误代码和模型。"
|
| 940 |
-
)
|
| 941 |
|
| 942 |
autoset_precision = config.bf16 + config.fp16 + config.fp32 == 0
|
| 943 |
|
|
@@ -990,7 +989,6 @@ class QWenLMHeadModel(QWenPreTrainedModel):
|
|
| 990 |
self.lm_head.half()
|
| 991 |
self.post_init()
|
| 992 |
|
| 993 |
-
|
| 994 |
def get_output_embeddings(self):
|
| 995 |
return self.lm_head
|
| 996 |
|
|
@@ -1000,22 +998,13 @@ class QWenLMHeadModel(QWenPreTrainedModel):
|
|
| 1000 |
def prepare_inputs_for_generation(
|
| 1001 |
self, input_ids, past_key_values=None, inputs_embeds=None, **kwargs
|
| 1002 |
):
|
| 1003 |
-
token_type_ids = kwargs.get("token_type_ids", None)
|
| 1004 |
if past_key_values:
|
| 1005 |
input_ids = input_ids[:, -1].unsqueeze(-1)
|
| 1006 |
-
if token_type_ids is not None:
|
| 1007 |
-
token_type_ids = token_type_ids[:, -1].unsqueeze(-1)
|
| 1008 |
|
| 1009 |
-
|
| 1010 |
-
|
| 1011 |
-
|
| 1012 |
-
if attention_mask is not None and position_ids is None:
|
| 1013 |
-
position_ids = attention_mask.long().cumsum(-1) - 1
|
| 1014 |
-
position_ids.masked_fill_(attention_mask == 0, 1)
|
| 1015 |
-
if past_key_values:
|
| 1016 |
-
position_ids = position_ids[:, -1].unsqueeze(-1)
|
| 1017 |
else:
|
| 1018 |
-
|
| 1019 |
|
| 1020 |
if inputs_embeds is not None and past_key_values is None:
|
| 1021 |
model_inputs = {"inputs_embeds": inputs_embeds}
|
|
@@ -1026,9 +1015,7 @@ class QWenLMHeadModel(QWenPreTrainedModel):
|
|
| 1026 |
{
|
| 1027 |
"past_key_values": past_key_values,
|
| 1028 |
"use_cache": kwargs.get("use_cache"),
|
| 1029 |
-
"position_ids": position_ids,
|
| 1030 |
"attention_mask": attention_mask,
|
| 1031 |
-
"token_type_ids": token_type_ids,
|
| 1032 |
}
|
| 1033 |
)
|
| 1034 |
return model_inputs
|
|
@@ -1299,8 +1286,7 @@ class RotaryEmbedding(torch.nn.Module):
|
|
| 1299 |
self._ntk_alpha_cached = 1.0
|
| 1300 |
self._ntk_alpha_cached_list = [1.0]
|
| 1301 |
|
| 1302 |
-
def update_rotary_pos_emb_cache(self,
|
| 1303 |
-
seqlen = max_seq_len + offset
|
| 1304 |
if seqlen > self._seq_len_cached or ntk_alpha != self._ntk_alpha_cached:
|
| 1305 |
base = self.base * ntk_alpha ** (self.dim / (self.dim - 2))
|
| 1306 |
self.inv_freq = 1.0 / (
|
|
@@ -1323,10 +1309,10 @@ class RotaryEmbedding(torch.nn.Module):
|
|
| 1323 |
cos, sin = emb.cos(), emb.sin()
|
| 1324 |
self._rotary_pos_emb_cache = [cos, sin]
|
| 1325 |
|
| 1326 |
-
def forward(self, max_seq_len,
|
| 1327 |
-
self.update_rotary_pos_emb_cache(max_seq_len,
|
| 1328 |
cos, sin = self._rotary_pos_emb_cache
|
| 1329 |
-
return [cos[:,
|
| 1330 |
|
| 1331 |
|
| 1332 |
def _rotate_half(x):
|
|
@@ -1338,21 +1324,28 @@ def _rotate_half(x):
|
|
| 1338 |
|
| 1339 |
|
| 1340 |
def apply_rotary_pos_emb(t, freqs):
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1341 |
cos, sin = freqs
|
|
|
|
| 1342 |
if apply_rotary_emb_func is not None and t.is_cuda:
|
| 1343 |
-
|
| 1344 |
-
|
| 1345 |
-
|
| 1346 |
-
|
| 1347 |
-
|
|
|
|
| 1348 |
else:
|
| 1349 |
-
|
| 1350 |
-
cos
|
| 1351 |
-
|
| 1352 |
-
t_ = t_.float()
|
| 1353 |
-
t_pass_ = t_pass_.float()
|
| 1354 |
-
t_ = (t_ * cos) + (_rotate_half(t_) * sin)
|
| 1355 |
-
return torch.cat((t_, t_pass_), dim=-1).type_as(t)
|
| 1356 |
|
| 1357 |
|
| 1358 |
class RMSNorm(torch.nn.Module):
|
|
|
|
| 13 |
import torch.nn.functional as F
|
| 14 |
import torch.utils.checkpoint
|
| 15 |
import warnings
|
|
|
|
| 16 |
|
| 17 |
from torch.nn import CrossEntropyLoss
|
| 18 |
from transformers import PreTrainedTokenizer, GenerationConfig, StoppingCriteriaList
|
|
|
|
| 78 |
apply_rotary_emb_func = None
|
| 79 |
rms_norm = None
|
| 80 |
flash_attn_unpadded_func = None
|
| 81 |
+
flash_attn_func = None
|
| 82 |
|
| 83 |
def _import_flash_attn():
|
| 84 |
+
global apply_rotary_emb_func, rms_norm, flash_attn_unpadded_func, flash_attn_func
|
| 85 |
try:
|
| 86 |
from flash_attn.layers.rotary import apply_rotary_emb_func as __apply_rotary_emb_func
|
| 87 |
apply_rotary_emb_func = __apply_rotary_emb_func
|
|
|
|
| 102 |
|
| 103 |
try:
|
| 104 |
import flash_attn
|
| 105 |
+
_flash_attn_func = None
|
| 106 |
if not hasattr(flash_attn, '__version__'):
|
| 107 |
from flash_attn.flash_attn_interface import flash_attn_unpadded_func as __flash_attn_unpadded_func
|
| 108 |
else:
|
| 109 |
if int(flash_attn.__version__.split(".")[0]) >= 2:
|
| 110 |
+
if int(flash_attn.__version__.split(".")[1]) >= 1:
|
| 111 |
+
from flash_attn.flash_attn_interface import flash_attn_func as _flash_attn_func
|
| 112 |
from flash_attn.flash_attn_interface import flash_attn_varlen_func as __flash_attn_unpadded_func
|
| 113 |
else:
|
| 114 |
from flash_attn.flash_attn_interface import flash_attn_unpadded_func as __flash_attn_unpadded_func
|
| 115 |
flash_attn_unpadded_func = __flash_attn_unpadded_func
|
| 116 |
+
flash_attn_func = _flash_attn_func
|
| 117 |
except ImportError:
|
| 118 |
logger.warn(
|
| 119 |
"Warning: import flash_attn fail, please install FlashAttention to get higher efficiency "
|
|
|
|
| 186 |
seqlen_k = k.shape[1]
|
| 187 |
seqlen_out = seqlen_q
|
| 188 |
|
| 189 |
+
if flash_attn_func is not None and batch_size == 1:
|
| 190 |
+
dropout_p = self.dropout_p if self.training else 0
|
| 191 |
+
output = flash_attn_func(q, k, v, dropout_p, softmax_scale=self.softmax_scale, causal=self.causal)
|
| 192 |
+
return output
|
| 193 |
+
|
| 194 |
q, k, v = [rearrange(x, "b s ... -> (b s) ...") for x in [q, k, v]]
|
| 195 |
cu_seqlens_q = torch.arange(
|
| 196 |
0,
|
|
|
|
| 320 |
warnings.warn("Failed to import KV cache kernels.")
|
| 321 |
self.cache_kernels = None
|
| 322 |
|
| 323 |
+
def _attn(self, query, key, value, causal_mask=None, attention_mask=None, head_mask=None):
|
| 324 |
device = query.device
|
| 325 |
if self.use_cache_quantization:
|
| 326 |
qk, qk_scale, qk_zero = key
|
|
|
|
| 345 |
size_temp = value[0].size(-1)
|
| 346 |
else:
|
| 347 |
size_temp = value.size(-1)
|
| 348 |
+
attn_weights = attn_weights / (size_temp ** 0.5)
|
| 349 |
+
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 350 |
mask_value = torch.finfo(attn_weights.dtype).min
|
| 351 |
+
if causal_mask is not None:
|
| 352 |
+
attn_weights = torch.where(
|
| 353 |
+
causal_mask, attn_weights.to(attn_weights.dtype), mask_value
|
| 354 |
+
)
|
|
|
|
|
|
|
| 355 |
|
| 356 |
if attention_mask is not None:
|
| 357 |
attn_weights = attn_weights + attention_mask
|
|
|
|
| 478 |
else:
|
| 479 |
present = None
|
| 480 |
|
| 481 |
+
key_size = key[0].size(2) if self.use_cache_quantization else key.size(1)
|
| 482 |
+
if key_size > self.seq_length and self.use_logn_attn and not self.training:
|
| 483 |
if self.use_cache_quantization:
|
| 484 |
seq_start = key[0].size(2) - query.size(1)
|
| 485 |
seq_end = key[0].size(2)
|
|
|
|
| 498 |
q, k, v = query, key, value
|
| 499 |
attn_output = self.core_attention_flash(q, k, v, attention_mask=attention_mask)
|
| 500 |
else:
|
| 501 |
+
key_size = key[0].size(2) if self.use_cache_quantization else key.size(1)
|
| 502 |
+
if query.size(1) == key_size:
|
| 503 |
+
causal_mask = torch.tril(
|
| 504 |
+
torch.ones((key_size, key_size), dtype=torch.bool, device=query.device)
|
| 505 |
+
).view(1, 1, key_size, key_size)
|
| 506 |
+
else:
|
| 507 |
+
causal_mask = None
|
| 508 |
query = query.permute(0, 2, 1, 3)
|
| 509 |
if not self.use_cache_quantization:
|
| 510 |
key = key.permute(0, 2, 1, 3)
|
| 511 |
value = value.permute(0, 2, 1, 3)
|
| 512 |
if (
|
| 513 |
+
causal_mask is None
|
| 514 |
and self.use_flash_attn
|
| 515 |
and flash_attn_unpadded_func is not None
|
| 516 |
and not self.is_fp32
|
|
|
|
| 519 |
raise Exception(_ERROR_INPUT_CPU_QUERY_WITH_FLASH_ATTN_ACTIVATED)
|
| 520 |
|
| 521 |
if not self.use_cache_quantization and SUPPORT_TORCH2:
|
|
|
|
|
|
|
|
|
|
| 522 |
if attention_mask is not None:
|
| 523 |
attention_mask = attention_mask.expand(
|
| 524 |
-1, -1, causal_mask.size(2), -1
|
| 525 |
+
)
|
| 526 |
+
if causal_mask is not None:
|
| 527 |
+
attention_mask.masked_fill(~causal_mask, torch.finfo(query.dtype).min)
|
| 528 |
else:
|
| 529 |
attention_mask = causal_mask
|
| 530 |
attn_output = F.scaled_dot_product_attention(
|
|
|
|
| 533 |
attn_weight = None
|
| 534 |
else:
|
| 535 |
attn_output, attn_weight = self._attn(
|
| 536 |
+
query, key, value, causal_mask, attention_mask, head_mask
|
| 537 |
)
|
| 538 |
context_layer = self._merge_heads(
|
| 539 |
attn_output, self.num_heads, self.head_dim
|
|
|
|
| 549 |
and not self.is_fp32
|
| 550 |
):
|
| 551 |
raise ValueError("Cannot output attentions while using flash-attn")
|
| 552 |
+
elif not self.use_cache_quantization and SUPPORT_TORCH2:
|
| 553 |
+
raise ValueError("Cannot output attentions while using scaled_dot_product_attention")
|
| 554 |
else:
|
| 555 |
outputs += (attn_weight,)
|
| 556 |
|
|
|
|
| 576 |
output = self.c_proj(intermediate_parallel)
|
| 577 |
return output
|
| 578 |
|
| 579 |
+
|
| 580 |
class QWenBlock(nn.Module):
|
| 581 |
def __init__(self, config):
|
| 582 |
super().__init__()
|
|
|
|
| 645 |
is_parallelizable = False
|
| 646 |
supports_gradient_checkpointing = True
|
| 647 |
_no_split_modules = ["QWenBlock"]
|
| 648 |
+
_skip_keys_device_placement = "past_key_values"
|
| 649 |
|
| 650 |
def __init__(self, *inputs, **kwargs):
|
| 651 |
super().__init__(*inputs, **kwargs)
|
|
|
|
| 937 |
assert (
|
| 938 |
config.bf16 + config.fp16 + config.fp32 <= 1
|
| 939 |
), "Only one of \"bf16\", \"fp16\", \"fp32\" can be true"
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 940 |
|
| 941 |
autoset_precision = config.bf16 + config.fp16 + config.fp32 == 0
|
| 942 |
|
|
|
|
| 989 |
self.lm_head.half()
|
| 990 |
self.post_init()
|
| 991 |
|
|
|
|
| 992 |
def get_output_embeddings(self):
|
| 993 |
return self.lm_head
|
| 994 |
|
|
|
|
| 998 |
def prepare_inputs_for_generation(
|
| 999 |
self, input_ids, past_key_values=None, inputs_embeds=None, **kwargs
|
| 1000 |
):
|
|
|
|
| 1001 |
if past_key_values:
|
| 1002 |
input_ids = input_ids[:, -1].unsqueeze(-1)
|
|
|
|
|
|
|
| 1003 |
|
| 1004 |
+
if input_ids.size(0) == 1:
|
| 1005 |
+
attention_mask = None
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1006 |
else:
|
| 1007 |
+
attention_mask = kwargs.get("attention_mask", None)
|
| 1008 |
|
| 1009 |
if inputs_embeds is not None and past_key_values is None:
|
| 1010 |
model_inputs = {"inputs_embeds": inputs_embeds}
|
|
|
|
| 1015 |
{
|
| 1016 |
"past_key_values": past_key_values,
|
| 1017 |
"use_cache": kwargs.get("use_cache"),
|
|
|
|
| 1018 |
"attention_mask": attention_mask,
|
|
|
|
| 1019 |
}
|
| 1020 |
)
|
| 1021 |
return model_inputs
|
|
|
|
| 1286 |
self._ntk_alpha_cached = 1.0
|
| 1287 |
self._ntk_alpha_cached_list = [1.0]
|
| 1288 |
|
| 1289 |
+
def update_rotary_pos_emb_cache(self, seqlen, ntk_alpha=1.0):
|
|
|
|
| 1290 |
if seqlen > self._seq_len_cached or ntk_alpha != self._ntk_alpha_cached:
|
| 1291 |
base = self.base * ntk_alpha ** (self.dim / (self.dim - 2))
|
| 1292 |
self.inv_freq = 1.0 / (
|
|
|
|
| 1309 |
cos, sin = emb.cos(), emb.sin()
|
| 1310 |
self._rotary_pos_emb_cache = [cos, sin]
|
| 1311 |
|
| 1312 |
+
def forward(self, max_seq_len, ntk_alpha=1.0):
|
| 1313 |
+
self.update_rotary_pos_emb_cache(max_seq_len, ntk_alpha)
|
| 1314 |
cos, sin = self._rotary_pos_emb_cache
|
| 1315 |
+
return [cos[:, :max_seq_len], sin[:, :max_seq_len]]
|
| 1316 |
|
| 1317 |
|
| 1318 |
def _rotate_half(x):
|
|
|
|
| 1324 |
|
| 1325 |
|
| 1326 |
def apply_rotary_pos_emb(t, freqs):
|
| 1327 |
+
""" Apply rotary embedding to the first rotary_dim of the iput
|
| 1328 |
+
|
| 1329 |
+
Arguments:
|
| 1330 |
+
t (tensor(batch_size, seq_len, n_head, head_dim)):
|
| 1331 |
+
the input embedding/hidden states
|
| 1332 |
+
freqs (list[tensor(1, seq_len, 1, rotary_dim), tensor(1, seq_len, 1, rotary_dim)]):
|
| 1333 |
+
the cached cos/sin position embeddings
|
| 1334 |
+
"""
|
| 1335 |
+
rot_dim = freqs[0].shape[-1]
|
| 1336 |
cos, sin = freqs
|
| 1337 |
+
t_float = t.float()
|
| 1338 |
if apply_rotary_emb_func is not None and t.is_cuda:
|
| 1339 |
+
# apply_rotary_emb in flash_attn requires cos/sin to be of
|
| 1340 |
+
# shape (seqlen, rotary_dim / 2) and apply rotary embedding
|
| 1341 |
+
# to the first rotary_dim of the input
|
| 1342 |
+
cos = cos.squeeze(0).squeeze(1)[:, : rot_dim // 2]
|
| 1343 |
+
sin = sin.squeeze(0).squeeze(1)[:, : rot_dim // 2]
|
| 1344 |
+
return apply_rotary_emb_func(t_float, cos, sin).type_as(t)
|
| 1345 |
else:
|
| 1346 |
+
t_rot, t_pass = t_float[..., :rot_dim], t_float[..., rot_dim:]
|
| 1347 |
+
t_rot = (t_rot * cos) + (_rotate_half(t_rot) * sin)
|
| 1348 |
+
return torch.cat((t_rot, t_pass), dim=-1).type_as(t)
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1349 |
|
| 1350 |
|
| 1351 |
class RMSNorm(torch.nn.Module):
|