

Update README.md
Browse files
README.md
CHANGED
|
@@ -38,7 +38,8 @@ https://AlignmentLab.ai
|
|
| 38 |
|
| 39 |
|
| 40 |
|
| 41 |
-
|
|
|
|
| 42 |
|-----------------------|-------|
|
| 43 |
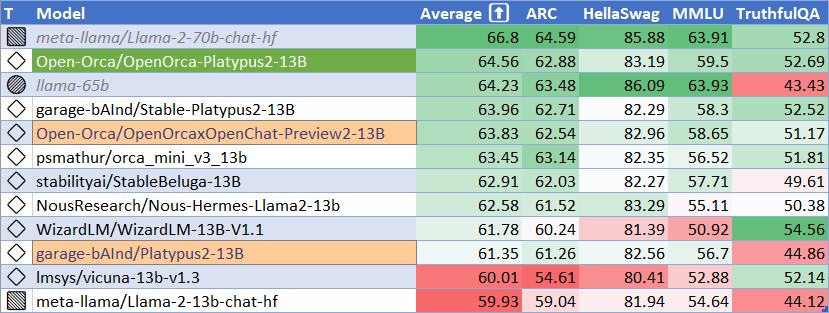
| MMLU (5-shot) | 59.5 |
|
| 44 |
| ARC (25-shot) | 62.88 |
|
|
@@ -46,18 +47,24 @@ https://AlignmentLab.ai
|
|
| 46 |
| TruthfulQA (0-shot) | 52.69 |
|
| 47 |
| Avg. | 64.56 |
|
| 48 |
|
| 49 |
-
We use [Language Model Evaluation Harness](https://github.com/EleutherAI/lm-evaluation-harness) to run the benchmark tests above, using the same version as the HuggingFace LLM Leaderboard.
|
|
|
|
|
|
|
| 50 |
|
| 51 |
|
| 52 |
## AGIEval Performance
|
| 53 |
|
| 54 |
-
We compare our results to our base Preview2 model
|
|
|
|
|
|
|
| 55 |
|
| 56 |

|
| 57 |
|
| 58 |
## BigBench-Hard Performance
|
| 59 |
|
| 60 |
-
We compare our results to our base Preview2 model
|
|
|
|
|
|
|
| 61 |
|
| 62 |

|
| 63 |
|
|
@@ -71,7 +78,9 @@ We compare our results to our base Preview2 model, and find **105%** of the base
|
|
| 71 |
* **License for OpenOrcaxOpenChat-Preview2-13B base weights**: Llama 2 Commercial
|
| 72 |
|
| 73 |
|
| 74 |
-
#
|
|
|
|
|
|
|
| 75 |
|
| 76 |
```
|
| 77 |
### Instruction:
|
|
@@ -82,12 +91,14 @@ We compare our results to our base Preview2 model, and find **105%** of the base
|
|
| 82 |
```
|
| 83 |
|
| 84 |
|
| 85 |
-
|
| 86 |
|
| 87 |
OpenChat Llama2 V1: see [OpenOrcaxOpenChat-Preview2-13B](https://huggingface.co/Open-Orca/OpenOrcaxOpenChat-Preview2-13B) for additional information.
|
| 88 |
|
| 89 |
|
| 90 |
-
# Training
|
|
|
|
|
|
|
| 91 |
|
| 92 |
`garage-bAInd/Platypus2-13B` trained using STEM and logic based dataset [`garage-bAInd/Open-Platypus`](https://huggingface.co/datasets/garage-bAInd/Open-Platypus).
|
| 93 |
|
|
@@ -96,13 +107,15 @@ Please see our [paper](https://platypus-llm.github.io/Platypus.pdf) and [project
|
|
| 96 |
[`Open-Orca/OpenOrcaxOpenChat-Preview2-13B`] trained using a refined subset of most of the GPT-4 data from the [OpenOrca dataset](https://huggingface.co/datasets/Open-Orca/OpenOrca).
|
| 97 |
|
| 98 |
|
| 99 |
-
|
| 100 |
|
| 101 |
`Open-Orca/Platypus2-13B` was instruction fine-tuned using LoRA on 1x A100-80GB.
|
| 102 |
For training details and inference instructions please see the [Platypus](https://github.com/arielnlee/Platypus) GitHub repo.
|
| 103 |
|
| 104 |
|
| 105 |
-
#
|
|
|
|
|
|
|
| 106 |
|
| 107 |
Install LM Evaluation Harness:
|
| 108 |
```
|
|
@@ -138,7 +151,7 @@ python main.py --model hf-causal-experimental --model_args pretrained=Open-Orca/
|
|
| 138 |
```
|
| 139 |
|
| 140 |
|
| 141 |
-
|
| 142 |
|
| 143 |
Llama 2 and fine-tuned variants are a new technology that carries risks with use. Testing conducted to date has been in English, and has not covered, nor could it cover all scenarios. For these reasons, as with all LLMs, Llama 2 and any fine-tuned varient's potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 2 variants, developers should perform safety testing and tuning tailored to their specific applications of the model.
|
| 144 |
|
|
|
|
| 38 |
|
| 39 |

|
| 40 |
|
| 41 |
+
|
| 42 |
+
| Metric | Value |
|
| 43 |
|-----------------------|-------|
|
| 44 |
| MMLU (5-shot) | 59.5 |
|
| 45 |
| ARC (25-shot) | 62.88 |
|
|
|
|
| 47 |
| TruthfulQA (0-shot) | 52.69 |
|
| 48 |
| Avg. | 64.56 |
|
| 49 |
|
| 50 |
+
We use [Language Model Evaluation Harness](https://github.com/EleutherAI/lm-evaluation-harness) to run the benchmark tests above, using the same version as the HuggingFace LLM Leaderboard.
|
| 51 |
+
|
| 52 |
+
Please see below for detailed instructions on reproducing benchmark results.
|
| 53 |
|
| 54 |
|
| 55 |
## AGIEval Performance
|
| 56 |
|
| 57 |
+
We compare our results to our base Preview2 model (using LM Evaluation Harness).
|
| 58 |
+
|
| 59 |
+
We find **112%** of the base model's performance on AGI Eval, averaging **0.463**.
|
| 60 |
|
| 61 |

|
| 62 |
|
| 63 |
## BigBench-Hard Performance
|
| 64 |
|
| 65 |
+
We compare our results to our base Preview2 model (using LM Evaluation Harness).
|
| 66 |
+
|
| 67 |
+
We find **105%** of the base model's performance on BigBench-Hard, averaging **0.442**.
|
| 68 |
|
| 69 |

|
| 70 |
|
|
|
|
| 78 |
* **License for OpenOrcaxOpenChat-Preview2-13B base weights**: Llama 2 Commercial
|
| 79 |
|
| 80 |
|
| 81 |
+
# Prompting
|
| 82 |
+
|
| 83 |
+
## Prompt Template for base Platypus2-13B
|
| 84 |
|
| 85 |
```
|
| 86 |
### Instruction:
|
|
|
|
| 91 |
```
|
| 92 |
|
| 93 |
|
| 94 |
+
## Prompt Template for base OpenOrcaxOpenChat-Preview2-13B
|
| 95 |
|
| 96 |
OpenChat Llama2 V1: see [OpenOrcaxOpenChat-Preview2-13B](https://huggingface.co/Open-Orca/OpenOrcaxOpenChat-Preview2-13B) for additional information.
|
| 97 |
|
| 98 |
|
| 99 |
+
# Training
|
| 100 |
+
|
| 101 |
+
## Training Datasets
|
| 102 |
|
| 103 |
`garage-bAInd/Platypus2-13B` trained using STEM and logic based dataset [`garage-bAInd/Open-Platypus`](https://huggingface.co/datasets/garage-bAInd/Open-Platypus).
|
| 104 |
|
|
|
|
| 107 |
[`Open-Orca/OpenOrcaxOpenChat-Preview2-13B`] trained using a refined subset of most of the GPT-4 data from the [OpenOrca dataset](https://huggingface.co/datasets/Open-Orca/OpenOrca).
|
| 108 |
|
| 109 |
|
| 110 |
+
## Training Procedure
|
| 111 |
|
| 112 |
`Open-Orca/Platypus2-13B` was instruction fine-tuned using LoRA on 1x A100-80GB.
|
| 113 |
For training details and inference instructions please see the [Platypus](https://github.com/arielnlee/Platypus) GitHub repo.
|
| 114 |
|
| 115 |
|
| 116 |
+
# Supplemental
|
| 117 |
+
|
| 118 |
+
## Reproducing Evaluation Results (for HuggingFace Leaderboard Eval)
|
| 119 |
|
| 120 |
Install LM Evaluation Harness:
|
| 121 |
```
|
|
|
|
| 151 |
```
|
| 152 |
|
| 153 |
|
| 154 |
+
## Limitations and bias
|
| 155 |
|
| 156 |
Llama 2 and fine-tuned variants are a new technology that carries risks with use. Testing conducted to date has been in English, and has not covered, nor could it cover all scenarios. For these reasons, as with all LLMs, Llama 2 and any fine-tuned varient's potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 2 variants, developers should perform safety testing and tuning tailored to their specific applications of the model.
|
| 157 |
|