---
license: apache-2.0
---
# Model Card for MediaTek Research Breeze-7B-FC-v1_0
## 🏆 Performance
| Models | #Parameters | Organization | License | 🧰 Function Calling? | 💬 Instrustion Following? |
|--------------------------------------------------------------------------------------------|-------------|------------|------------|-------------------|----------|
| [Breeze-7B-Instruct-v1_0](https://huggingface.co/MediaTek-Research/Breeze-7B-Instruct-v1_0)| 7B | MediaTek Research | Apache 2.0 | ❌ | ✅ |
| [**Breeze-7B-FC-v1_0**](https://huggingface.co/MediaTek-Research/Breeze-7B-FC-v1_0) | 7B | MediaTek Research | Apache 2.0 | ✅ | ✅ |
| [Gorilla-OpenFunctions-v2](https://huggingface.co/MediaTek-Research/Breeze-7B-FC-v1_0) | 7B | Gorilla LLM | Apache 2.0 | ✅ | ❌ |
| [GPT-3.5-Turbo-0125](https://openai.com) | | OpenAI | Proprietary| ✅ | ✅ |
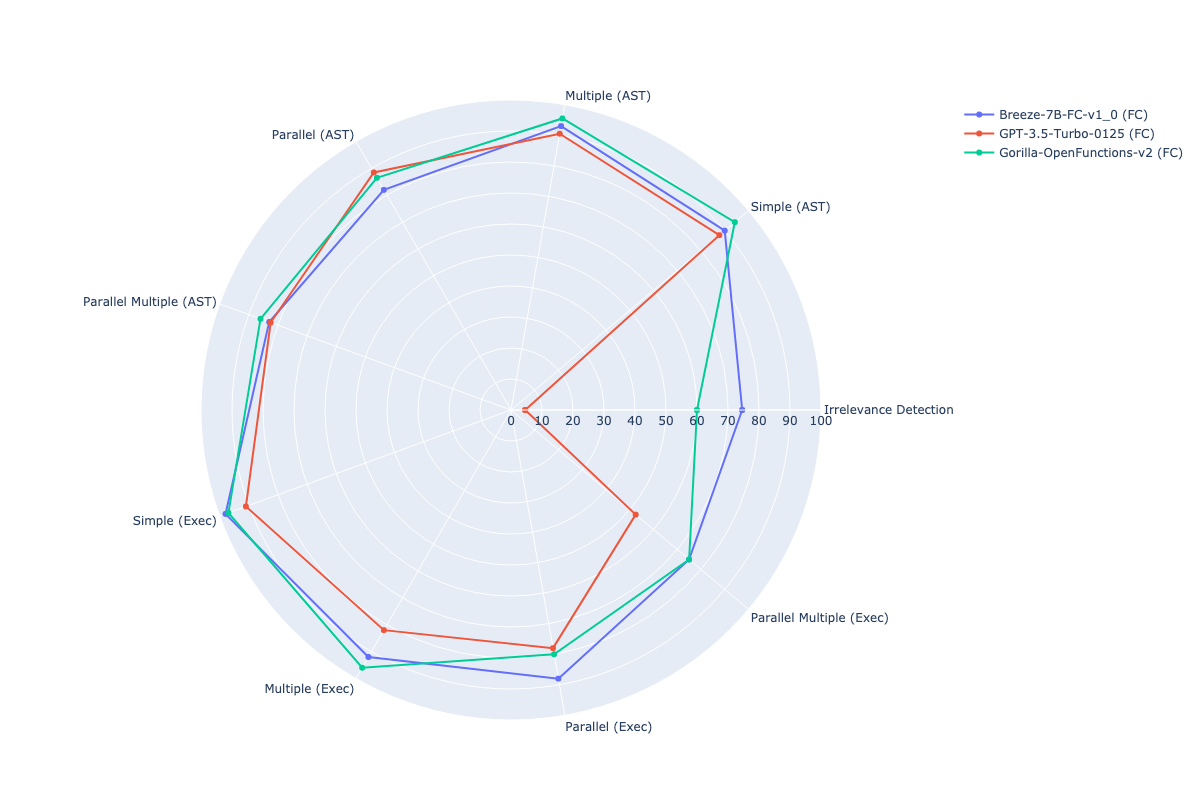
**Evaluate function calling on EN benchmark**
Berkeley function-calling leaderboard
| Models | ↑ Overall | Irrelevance
Detection | AST/
Simple | AST/
Multiple | AST/
Parallel | AST/
Parallel-Multiple | Exec/
Simple | Exec/
Multiple | Exec/
Parallel | Exec/
Parallel-Multiple |
|-----------------------------------|----------|---------------------|------------|--------------|--------------|------------------------|--------------|---------------------|---------------------|-------------------------------|
| **Breeze-7B-FC-v1_0 (FC)** | 86.01 | 74.58 | 90.00 | 93.00 | 82.00 | 83.00 | 98.00 | 92.00 | 88.00 | 75.00 |
| Gorilla-OpenFunctions-v2 (FC) | 85.95 | 60.00 | 94.25 | 95.50 | 86.50 | 86.00 | 97.00 | 96.00 | 80.00 | 75.00 |
| GPT-3.5-Turbo-0125 (FC) | 72.77 | 4.58 | 87.75 | 90.50 | 88.50 | 82.50 | 91.00 | 82.00 | 78.00 | 52.50 |
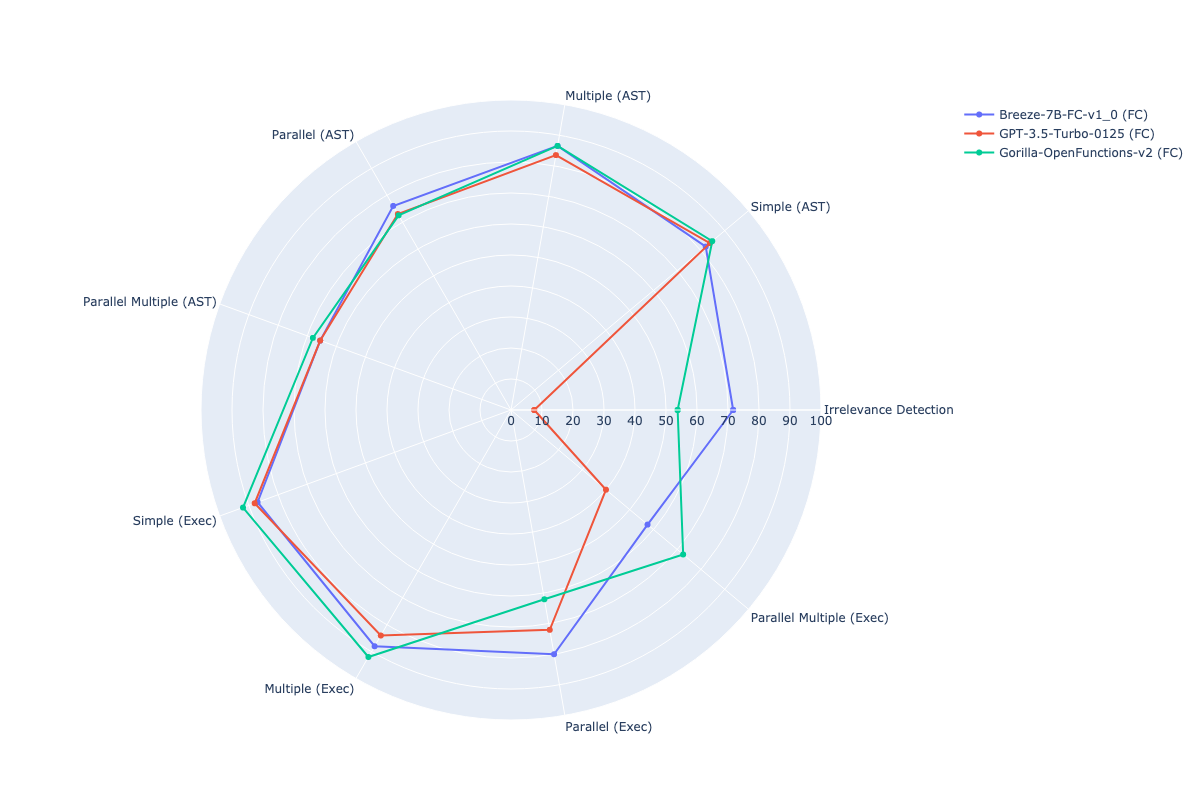
**Evaluate function calling on ZHTW benchmark**
function-calling-leaderboard-for-zhtw
| Models | ↑ Overall | Irrelevance
Detection | AST/
Simple | AST/
Multiple | AST/
Parallel | AST/
Parallel-Multiple | Exec/
Simple | Exec/
Multiple | Exec/
Parallel | Exec/
Parallel-Multiple |
|-----------------------------------|----------|---------------------|------------|--------------|--------------|------------------------|--------------|---------------------|---------------------|-------------------------------|
| **Breeze-7B-FC-v1_0 (FC)** | 77.70 | 71.67 | 82.00 | 86.50 | 76.00 | 65.50 | 87.00 | 88.00 | 80.00 | 57.50 |
| Gorilla-OpenFunctions-v2 (FC) | 75.68 | 53.75 | 84.75 | 86.50 | 72.50 | 68.00 | 92.00 | 92.00 | 62.00 | 72.50 |
| GPT-3.5-Turbo-0125 (FC) | 66.15 | 7.50 | 83.75 | 83.50 | 73.00 | 65.50 | 88.00 | 84.00 | 72.00 | 40.00 |
**Evaluate instrustion following on EN benchmark**
MT-Bench
| | Win | Tie | Lose |
|---|---|---|---|
| **Breeze-7B-FC-v1_0** *v.s.* Breeze-7B-Instruct-v1_0 | 25 (15.6%) | 72 (45.0%) | 63 (39.4%) |
**Evaluate instrustion following on ZHTW benchmark**
MT-Bench-TC
| | Win | Tie | Lose |
|---|---|---|---|
| **Breeze-7B-FC-v1_0** *v.s.* Breeze-7B-Instruct-v1_0 | 36 (22.5%) | 81 (50.6%) | 43 (26.9%) |
## 👩💻 How to use
**Dependiency**
Install `mtkresearch` package
```
git clone https://github.com/mtkresearch/mtkresearch.git
cd mtkresearch
pip install -e .
```
**Hosting by VLLM**
```python
from vllm import LLM, SamplingParams
llm = LLM(
model='MediaTek-Research/Breeze-7B-FC-v1_0',
tensor_parallel_size=num_gpu, # number of gpus
gpu_memory_utilization=0.7
)
instance_end_token_id = llm.get_tokenizer().convert_token_to_ids('<|im_end|>')
params = SamplingParams(
temperature=0.01,
top_p=0.01,
max_tokens=4096,
repetition_penalty=1.1,
stop_token_ids=[instance_end_token_id]
)
def _inference(prompt, llm, params):
return llm.generate(prompt, params)[0].outputs[0].text
```
**Instruction following**
```python
from mtkresearch.llm.prompt import MRPromptV2
sys_prompt = 'You are a helpful AI assistant built by MediaTek Research. The user you are helping speaks Traditional Chinese and comes from Taiwan.'
prompt_engine = MRPromptV2()
conversations = [
{"role": "system", "content": sys_prompt},
{"role": "user", "content": "請問什麼是深度學習?"},
]
prompt = prompt_engine.get_prompt(conversations)
output_str = _inference(prompt, llm, params)
result = prompt_engine.parse_generated_str(output_str)
print(result) #
```
**Function Calling**
```python
from mtkresearch.llm.prompt import MRPromptV2
sys_prompt = 'You are a helpful AI assistant built by MediaTek Research. The user you are helping speaks Traditional Chinese and comes from Taiwan.'
functions = [
{
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA"
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"]
}
},
"required": ["location"]
}
}
]
prompt_engine = MRPromptV2()
# stage 1: query
conversations = [
{"role": "user", "content": "台北目前溫度是攝氏幾度?"},
]
prompt = prompt_engine.get_prompt(conversations, functions=functions)
output_str = _inference(prompt, llm, params)
result = prompt_engine.parse_generated_str(output_str)
print(result) #
# stage 2: execute called functions
# stage 3: put executed results
```