

up
Browse files- README.md +127 -1
- added_tokens.json +4 -0
- config.json +26 -0
- generation_config.json +7 -0
- img1.png +0 -0
- img2.png +0 -0
- img3.png +0 -0
- pytorch_model-00001-of-00028.bin +3 -0
- pytorch_model-00002-of-00028.bin +3 -0
- pytorch_model-00003-of-00028.bin +3 -0
- pytorch_model-00004-of-00028.bin +3 -0
- pytorch_model-00005-of-00028.bin +3 -0
- pytorch_model-00006-of-00028.bin +3 -0
- pytorch_model-00007-of-00028.bin +3 -0
- pytorch_model-00008-of-00028.bin +3 -0
- pytorch_model-00009-of-00028.bin +3 -0
- pytorch_model-00010-of-00028.bin +3 -0
- pytorch_model-00011-of-00028.bin +3 -0
- pytorch_model-00012-of-00028.bin +3 -0
- pytorch_model-00013-of-00028.bin +3 -0
- pytorch_model-00014-of-00028.bin +3 -0
- pytorch_model-00015-of-00028.bin +3 -0
- pytorch_model-00016-of-00028.bin +3 -0
- pytorch_model-00017-of-00028.bin +3 -0
- pytorch_model-00018-of-00028.bin +3 -0
- pytorch_model-00019-of-00028.bin +3 -0
- pytorch_model-00020-of-00028.bin +3 -0
- pytorch_model-00021-of-00028.bin +3 -0
- pytorch_model-00022-of-00028.bin +3 -0
- pytorch_model-00023-of-00028.bin +3 -0
- pytorch_model-00024-of-00028.bin +3 -0
- pytorch_model-00025-of-00028.bin +3 -0
- pytorch_model-00026-of-00028.bin +3 -0
- pytorch_model-00027-of-00028.bin +3 -0
- pytorch_model-00028-of-00028.bin +3 -0
- pytorch_model.bin.index.json +410 -0
- special_tokens_map.json +39 -0
- tokenizer.model +3 -0
- tokenizer_config.json +33 -0
README.md
CHANGED
|
@@ -1,3 +1,129 @@
|
|
| 1 |
---
|
| 2 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
+
tasks:
|
| 3 |
+
|
| 4 |
+
- text-generation
|
| 5 |
+
|
| 6 |
+
model_type:
|
| 7 |
+
|
| 8 |
+
- gpt
|
| 9 |
+
- llama
|
| 10 |
+
|
| 11 |
+
domain:
|
| 12 |
+
|
| 13 |
+
- nlp
|
| 14 |
+
|
| 15 |
+
license: Apache License 2.0
|
| 16 |
+
|
| 17 |
+
language:
|
| 18 |
+
|
| 19 |
+
- en
|
| 20 |
+
- zh
|
| 21 |
+
- cn
|
| 22 |
+
|
| 23 |
+
tags:
|
| 24 |
+
- transformer
|
| 25 |
+
- 封神榜
|
| 26 |
---
|
| 27 |
+
# Ziya2-13B-Base
|
| 28 |
+
|
| 29 |
+
- Main Page:[Fengshenbang](https://fengshenbang-lm.com/)
|
| 30 |
+
- Github: [Fengshenbang-LM](https://github.com/IDEA-CCNL/Fengshenbang-LM)
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
# 姜子牙系列模型
|
| 34 |
+
|
| 35 |
+
- [Ziya-LLaMA-13B-v1](https://huggingface.co/IDEA-CCNL/Ziya-LLaMA-13B-v1)
|
| 36 |
+
- [Ziya-LLaMA-7B-Reward](https://huggingface.co/IDEA-CCNL/Ziya-LLaMA-7B-Reward)
|
| 37 |
+
- [Ziya-LLaMA-13B-Pretrain-v1](https://huggingface.co/IDEA-CCNL/Ziya-LLaMA-13B-Pretrain-v1)
|
| 38 |
+
- [Ziya-BLIP2-14B-Visual-v1](https://huggingface.co/IDEA-CCNL/Ziya-BLIP2-14B-Visual-v1)
|
| 39 |
+
|
| 40 |
+
## 简介 Brief Introduction
|
| 41 |
+
|
| 42 |
+
Ziya2-13B-Base 是基于LLaMa2的130亿参数大规模预训练模型,针对中文分词优化,并完成了中英文 650B tokens 的增量预训练,进一步提升了中文生成和理解能力。
|
| 43 |
+
|
| 44 |
+
The Ziya2-13B-Base is a large-scale pre-trained model based on LLaMA2 with 13 billion parameters. We optimizes LLaMAtokenizer on chinese, and incrementally train 650 billion tokens of data based on LLaMa2-13B model, which significantly improved the understanding and generation ability on Chinese.
|
| 45 |
+

|
| 46 |
+
## 模型分类 Model Taxonomy
|
| 47 |
+
|
| 48 |
+
| 需求 Demand | 任务 Task | 系列 Series | 模型 Model | 参数 Parameter | 额外 Extra |
|
| 49 |
+
|:----------:|:-------:|:---------:|:--------:|:------------:|:---------------:|
|
| 50 |
+
| 通用 General | AGI模型 | 姜子牙 Ziya | LLaMA2 | 13B | English&Chinese |
|
| 51 |
+
|
| 52 |
+
## 模型信息 Model Information
|
| 53 |
+
|
| 54 |
+
### 继续预训练 Continual Pretraining
|
| 55 |
+
|
| 56 |
+
Meta在2023年7月份发布了Llama2系列大模型,相比于LLaMA1的1.4万亿Token数据,Llama2预训练的Token达到了2万亿,并在各个榜单中明显超过LLaMA1。
|
| 57 |
+
|
| 58 |
+
Meta released the Llama2 series of large models in July 2023, with pre-trained tokens reaching 200 billion compared to Llama1's 140 billion tokens, significantly outperforming Llama1 in various rankings.
|
| 59 |
+
|
| 60 |
+
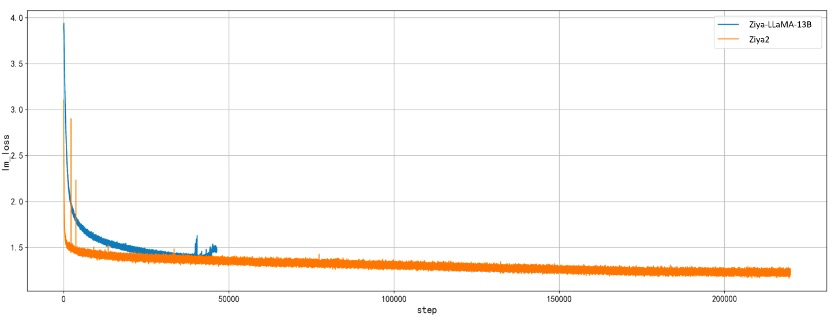
Ziya2-13B-Base沿用了Ziya-LLaMA-13B高效的中文编解码方式,但采取了更优化的初始化算法使得初始训练loss更低。同时,我们对Fengshen-PT继续训练框架进行了优化,效率方面,整合了FlashAttention2、Apex RMS norm等技术来帮助提升效率,对比Ziya-LLaMA-13B训练速度提升38%(163 TFLOPS/per gpu/per sec)。稳定性方面,我们采取BF16进行训练,修复了底层分布式框架的bug,确保模型能够持续稳定训练,解决了Ziya-LLaMA-13B遇到的训练后期不稳定的问题,并在7.25号进行了直播,最终完成了全部数据的继续训练。我们也发现,模型效果还有进一步提升的趋势,后续也会对Ziya2-13B-Base进行继续优化。
|
| 61 |
+
|
| 62 |
+
Ziya2-13B-Base retained the efficient Chinese encoding and decoding techniques of Ziya-LLaMA-13B, but employed a more optimized initialization algorithm to achieve lower initial training loss. Additionally, we optimized the Fengshen-PT fine-tuning framework. In terms of efficiency, we integrated technologies such as FlashAttention2 and Apex RMS norm to boost efficiency, resulting in a 38% increase in training speed compared to Ziya-LLaMA-13B (163 TFLOPS per GPU per second). For stability, we used BF16 for training, fixed underlying distributed framework bugs to ensure consistent model training, and resolved the late-stage instability issues encountered in the training of Ziya-LLaMA-13B. We also conducted a live broadcast on July 25th to complete the continued training of all data. We have observed a trend towards further improvements in model performance and plan to continue optimizing Ziya2-13B-Base in the future.
|
| 63 |
+
|
| 64 |
+

|
| 65 |
+
|
| 66 |
+
### 效果评估 Performance
|
| 67 |
+
|
| 68 |
+
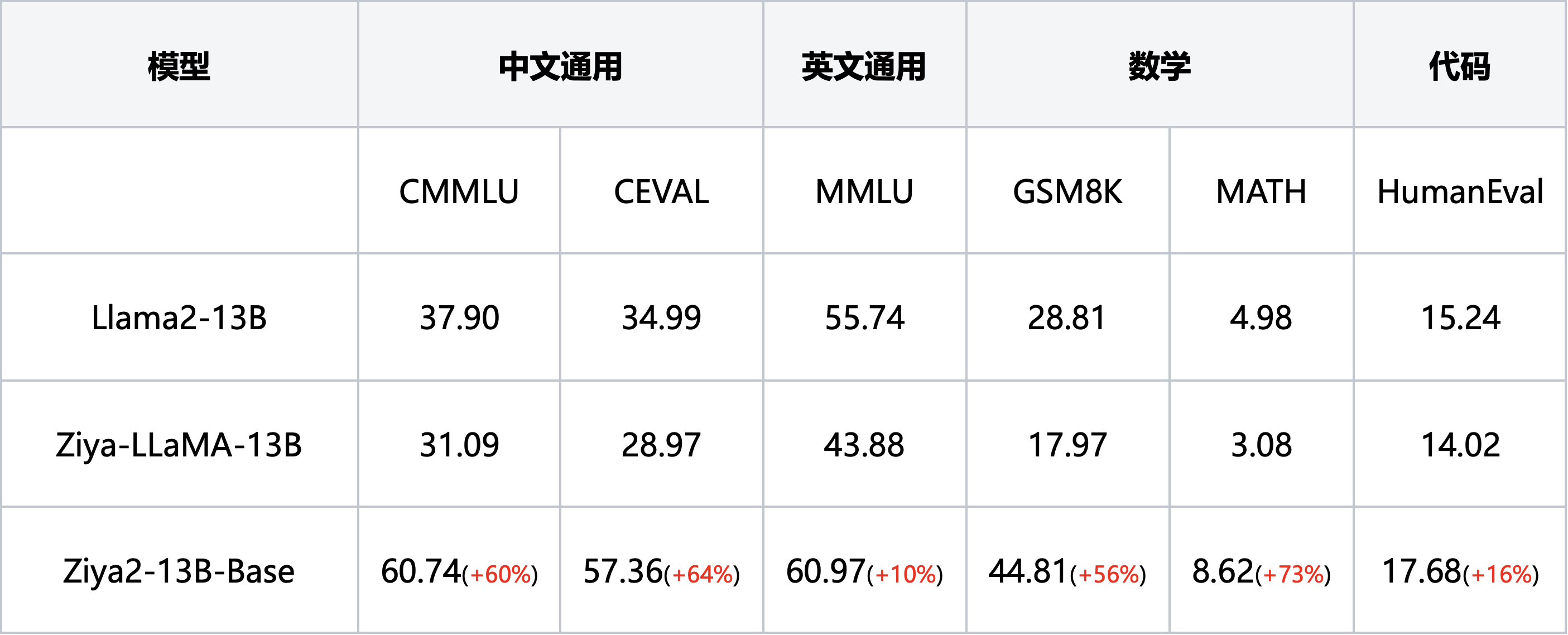
Ziya2-13B-Base在Llama2-13B的基础上进行了约650B自建高质量中英文数据集的继续训练,在中文、英文、数学、代码等下游理解任务上相对于Llama2-13B取得了明显的提升,相对Ziya-LLaMA-13B也有明显的提升。
|
| 69 |
+
|
| 70 |
+
The model Ziya2-13B-Base underwent further training on approximately 650 billion self-collected high-quality Chinese and English datasets, building upon the foundation of Llama2-13B. It achieved significant improvements in downstream comprehension tasks such as Chinese, English, mathematics, and code understanding, surpassing Llama2-13B and showing clear advancements compared to Ziya-LLaMA-13B.
|
| 71 |
+
|
| 72 |
+

|
| 73 |
+
|
| 74 |
+
## 使用 Usage
|
| 75 |
+
|
| 76 |
+
加载模型,进行的续写:
|
| 77 |
+
|
| 78 |
+
Load the model and predicting:
|
| 79 |
+
|
| 80 |
+
```python3
|
| 81 |
+
from transformers import AutoTokenizer
|
| 82 |
+
from transformers import LlamaForCausalLM
|
| 83 |
+
import torch
|
| 84 |
+
|
| 85 |
+
query="问题:我国的三皇五帝分别指的是谁?答案:
|
| 86 |
+
model = LlamaForCausalLM.from_pretrained('IDEA-CCNL/Ziya2-13B-Base', torch_dtype=torch.float16, device_map="auto").eval()
|
| 87 |
+
tokenizer = AutoTokenizer.from_pretrained(ckpt)
|
| 88 |
+
input_ids = tokenizer(query, return_tensors="pt").input_ids.to('cuda:0')
|
| 89 |
+
generate_ids = model.generate(
|
| 90 |
+
input_ids,
|
| 91 |
+
max_new_tokens=512,
|
| 92 |
+
do_sample = True,
|
| 93 |
+
top_p = 0.9)
|
| 94 |
+
output = tokenizer.batch_decode(generate_ids)[0]
|
| 95 |
+
print(output)
|
| 96 |
+
```
|
| 97 |
+
|
| 98 |
+
上面是简单的续写示例,其他更多prompt和玩法,感兴趣的朋友可以下载下来自行发掘。
|
| 99 |
+
|
| 100 |
+
The above is a simple example of continuing writing. For more prompts and creative ways to use the model, interested individuals can download it and explore further on their own.
|
| 101 |
+
|
| 102 |
+
## 引用 Citation
|
| 103 |
+
|
| 104 |
+
如果您在您的工作中使用了我们的模型,可以引用我们的[论文](https://arxiv.org/abs/2210.08590):
|
| 105 |
+
|
| 106 |
+
If you are using the resource for your work, please cite the our [paper](https://arxiv.org/abs/2210.08590):
|
| 107 |
+
|
| 108 |
+
```text
|
| 109 |
+
@article{fengshenbang,
|
| 110 |
+
author = {Jiaxing Zhang and Ruyi Gan and Junjie Wang and Yuxiang Zhang and Lin Zhang and Ping Yang and Xinyu Gao and Ziwei Wu and Xiaoqun Dong and Junqing He and Jianheng Zhuo and Qi Yang and Yongfeng Huang and Xiayu Li and Yanghan Wu and Junyu Lu and Xinyu Zhu and Weifeng Chen and Ting Han and Kunhao Pan and Rui Wang and Hao Wang and Xiaojun Wu and Zhongshen Zeng and Chongpei Chen},
|
| 111 |
+
title = {Fengshenbang 1.0: Being the Foundation of Chinese Cognitive Intelligence},
|
| 112 |
+
journal = {CoRR},
|
| 113 |
+
volume = {abs/2209.02970},
|
| 114 |
+
year = {2022}
|
| 115 |
+
}
|
| 116 |
+
```
|
| 117 |
+
|
| 118 |
+
You can also cite our [website](https://github.com/IDEA-CCNL/Fengshenbang-LM/):
|
| 119 |
+
|
| 120 |
+
欢迎引用我们的[网站](https://github.com/IDEA-CCNL/Fengshenbang-LM/):
|
| 121 |
+
|
| 122 |
+
```text
|
| 123 |
+
@misc{Fengshenbang-LM,
|
| 124 |
+
title={Fengshenbang-LM},
|
| 125 |
+
author={IDEA-CCNL},
|
| 126 |
+
year={2021},
|
| 127 |
+
howpublished={\url{https://github.com/IDEA-CCNL/Fengshenbang-LM}},
|
| 128 |
+
}
|
| 129 |
+
```
|
added_tokens.json
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"<bot>": 39409,
|
| 3 |
+
"<human>": 39408
|
| 4 |
+
}
|
config.json
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"LlamaForCausalLM"
|
| 4 |
+
],
|
| 5 |
+
"bos_token_id": 1,
|
| 6 |
+
"eos_token_id": 2,
|
| 7 |
+
"hidden_act": "silu",
|
| 8 |
+
"hidden_size": 5120,
|
| 9 |
+
"initializer_range": 0.02,
|
| 10 |
+
"intermediate_size": 13824,
|
| 11 |
+
"layer_norm_eps": 1e-05,
|
| 12 |
+
"max_position_embeddings": 4096,
|
| 13 |
+
"model_type": "llama",
|
| 14 |
+
"num_attention_heads": 40,
|
| 15 |
+
"num_hidden_layers": 40,
|
| 16 |
+
"pad_token_id": 0,
|
| 17 |
+
"rms_norm_eps": 1e-06,
|
| 18 |
+
"rotary_emb_base": 10000,
|
| 19 |
+
"rotary_pct": 1,
|
| 20 |
+
"tie_word_embeddings": false,
|
| 21 |
+
"torch_dtype": "bfloat16",
|
| 22 |
+
"transformers_version": "4.30.2",
|
| 23 |
+
"use_cache": true,
|
| 24 |
+
"use_parallel_residual": false,
|
| 25 |
+
"vocab_size": 39424
|
| 26 |
+
}
|
generation_config.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"bos_token_id": 1,
|
| 4 |
+
"eos_token_id": 2,
|
| 5 |
+
"pad_token_id": 0,
|
| 6 |
+
"transformers_version": "4.30.2"
|
| 7 |
+
}
|
img1.png
ADDED

|
img2.png
ADDED
|
img3.png
ADDED
|
pytorch_model-00001-of-00028.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:58fcec6cc8f64994950f8d609154e9716bae9ffce7718aabafc95a981267284b
|
| 3 |
+
size 896534991
|
pytorch_model-00002-of-00028.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f434eb99fbbf675dac0b896853c3c76ac499a9e950adcb8894295f6a1ae28d79
|
| 3 |
+
size 985707823
|
pytorch_model-00003-of-00028.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8b40a90ada8790140c48e238594eaf3307a510b8d18598722ef1e80aa314268f
|
| 3 |
+
size 917528001
|
pytorch_model-00004-of-00028.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:cab0c80c7adecd376eca6253ff84dbdee004240302c386072336d6d807e00afa
|
| 3 |
+
size 985707823
|
pytorch_model-00005-of-00028.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:dd4918bffe1c2a9136e5989b44a1c5c5d90f38cde66734f761307a2115742890
|
| 3 |
+
size 917528001
|
pytorch_model-00006-of-00028.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c3411357e58de4193fa8c75b21929ad7f5f00aca8e626fb8af81d3312480572f
|
| 3 |
+
size 985707823
|
pytorch_model-00007-of-00028.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c569f55b71ff92e40c04a8e420377587afdd14b75ee37714c85aed66be81db70
|
| 3 |
+
size 917528001
|
pytorch_model-00008-of-00028.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:50d38b8b8c8e3380be78e956ecc9873a268c49ccaa8952dc81eb46f0091f2200
|
| 3 |
+
size 985707823
|
pytorch_model-00009-of-00028.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c64fe112d9bf0aca8730337ee7651145842cbfe4a171af3ad080834bbd3f5f01
|
| 3 |
+
size 917528001
|
pytorch_model-00010-of-00028.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:37bbe56a0a3dfc536c106f4d6784410ea2e3065f9f8b9986b2a193623d4ae5f2
|
| 3 |
+
size 985707823
|
pytorch_model-00011-of-00028.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a0ce324eb37fa8a5987a3aef37c824e97e6e1931ae173382432ca1e84287c94c
|
| 3 |
+
size 917528001
|
pytorch_model-00012-of-00028.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:bd90c2387a7185f5f95e0eabcc924bb4ee202df41af87f98395b75f0e1e1417c
|
| 3 |
+
size 985707823
|
pytorch_model-00013-of-00028.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9b0ec5133336611bb8fe99ef89218e7e9309b3ab6f9feef1a591aa38e63ec087
|
| 3 |
+
size 917528001
|
pytorch_model-00014-of-00028.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:bc616f57f410066f5e58e941be2bf4ca29e191bb8aa231dd0c9435181195fa87
|
| 3 |
+
size 985707823
|
pytorch_model-00015-of-00028.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:edcb8c50e1397947fb55d0c78d3c36c54ab798705ef94cd25205307aff20a45f
|
| 3 |
+
size 917528001
|
pytorch_model-00016-of-00028.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:93f25f171e62c82808ea32f09e6fc4ab3b3723418bc121e86885f1ef3e38e038
|
| 3 |
+
size 985707823
|
pytorch_model-00017-of-00028.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:cd0cdfff2019e214f12dd7602ff2e9f669d63bc4bfed651d8ffa6baf2482278c
|
| 3 |
+
size 917528001
|
pytorch_model-00018-of-00028.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c2d36fb07d744bc97a55443fab68fbd9bd776245341d996a5c3848d0a79a9103
|
| 3 |
+
size 985707823
|
pytorch_model-00019-of-00028.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ed579c633f7f4f51b9d14952e5b8417bef607710dfd28cd06d80fefbc570feed
|
| 3 |
+
size 917528001
|
pytorch_model-00020-of-00028.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:3caef721b8b15706a4a566a108dbac4f28c8d1f3d35456ba2f8fab6b1275d3d0
|
| 3 |
+
size 985707823
|
pytorch_model-00021-of-00028.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b98efcf6b3a72acb7cb1ea62ab519304e3d18481f54117e961aa7d28af9aea0f
|
| 3 |
+
size 917528001
|
pytorch_model-00022-of-00028.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:394ac6396848038f4591343393edd996d8c3f206d35f5a1135021466e0f52cf8
|
| 3 |
+
size 985707823
|
pytorch_model-00023-of-00028.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d4785f54e41f1b9c2a098061b70185e3a01f4467b37fcf88b0f2fdffe965f83c
|
| 3 |
+
size 917528001
|
pytorch_model-00024-of-00028.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:71ae6d94acb1b488b534cc2bcd0ab147c625e5f1d0b38dddae47f7afe970abd2
|
| 3 |
+
size 985707823
|
pytorch_model-00025-of-00028.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:05cb90f9fafb73b094a7b91d561d7aec560f2e6164a19bd0081942d60cc27bf4
|
| 3 |
+
size 917528001
|
pytorch_model-00026-of-00028.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:43ed8f14508cddcf3e1e689434a245ebc333f7da24bce346ad41105d39642c76
|
| 3 |
+
size 985707823
|
pytorch_model-00027-of-00028.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:523a61944cf3416497fd41bca283ea7e592e6b2a76c147a84f2ae6ef04d3323c
|
| 3 |
+
size 917528001
|
pytorch_model-00028-of-00028.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:eb4302a156960a3c3d76efd371812ae470edde8c1eaa8ef45925565ca6784b64
|
| 3 |
+
size 545291867
|
pytorch_model.bin.index.json
ADDED
|
@@ -0,0 +1,410 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_size": 26183777280
|
| 4 |
+
},
|
| 5 |
+
"weight_map": {
|
| 6 |
+
"lm_head.weight": "pytorch_model-00028-of-00028.bin",
|
| 7 |
+
"model.embed_tokens.weight": "pytorch_model-00001-of-00028.bin",
|
| 8 |
+
"model.layers.0.input_layernorm.weight": "pytorch_model-00002-of-00028.bin",
|
| 9 |
+
"model.layers.0.mlp.down_proj.weight": "pytorch_model-00001-of-00028.bin",
|
| 10 |
+
"model.layers.0.mlp.gate_proj.weight": "pytorch_model-00001-of-00028.bin",
|
| 11 |
+
"model.layers.0.mlp.up_proj.weight": "pytorch_model-00002-of-00028.bin",
|
| 12 |
+
"model.layers.0.post_attention_layernorm.weight": "pytorch_model-00002-of-00028.bin",
|
| 13 |
+
"model.layers.0.self_attn.k_proj.weight": "pytorch_model-00001-of-00028.bin",
|
| 14 |
+
"model.layers.0.self_attn.o_proj.weight": "pytorch_model-00001-of-00028.bin",
|
| 15 |
+
"model.layers.0.self_attn.q_proj.weight": "pytorch_model-00001-of-00028.bin",
|
| 16 |
+
"model.layers.0.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00028.bin",
|
| 17 |
+
"model.layers.0.self_attn.v_proj.weight": "pytorch_model-00001-of-00028.bin",
|
| 18 |
+
"model.layers.1.input_layernorm.weight": "pytorch_model-00002-of-00028.bin",
|
| 19 |
+
"model.layers.1.mlp.down_proj.weight": "pytorch_model-00002-of-00028.bin",
|
| 20 |
+
"model.layers.1.mlp.gate_proj.weight": "pytorch_model-00002-of-00028.bin",
|
| 21 |
+
"model.layers.1.mlp.up_proj.weight": "pytorch_model-00002-of-00028.bin",
|
| 22 |
+
"model.layers.1.post_attention_layernorm.weight": "pytorch_model-00002-of-00028.bin",
|
| 23 |
+
"model.layers.1.self_attn.k_proj.weight": "pytorch_model-00002-of-00028.bin",
|
| 24 |
+
"model.layers.1.self_attn.o_proj.weight": "pytorch_model-00002-of-00028.bin",
|
| 25 |
+
"model.layers.1.self_attn.q_proj.weight": "pytorch_model-00002-of-00028.bin",
|
| 26 |
+
"model.layers.1.self_attn.rotary_emb.inv_freq": "pytorch_model-00002-of-00028.bin",
|
| 27 |
+
"model.layers.1.self_attn.v_proj.weight": "pytorch_model-00002-of-00028.bin",
|
| 28 |
+
"model.layers.10.input_layernorm.weight": "pytorch_model-00008-of-00028.bin",
|
| 29 |
+
"model.layers.10.mlp.down_proj.weight": "pytorch_model-00008-of-00028.bin",
|
| 30 |
+
"model.layers.10.mlp.gate_proj.weight": "pytorch_model-00008-of-00028.bin",
|
| 31 |
+
"model.layers.10.mlp.up_proj.weight": "pytorch_model-00008-of-00028.bin",
|
| 32 |
+
"model.layers.10.post_attention_layernorm.weight": "pytorch_model-00008-of-00028.bin",
|
| 33 |
+
"model.layers.10.self_attn.k_proj.weight": "pytorch_model-00008-of-00028.bin",
|
| 34 |
+
"model.layers.10.self_attn.o_proj.weight": "pytorch_model-00008-of-00028.bin",
|
| 35 |
+
"model.layers.10.self_attn.q_proj.weight": "pytorch_model-00008-of-00028.bin",
|
| 36 |
+
"model.layers.10.self_attn.rotary_emb.inv_freq": "pytorch_model-00008-of-00028.bin",
|
| 37 |
+
"model.layers.10.self_attn.v_proj.weight": "pytorch_model-00008-of-00028.bin",
|
| 38 |
+
"model.layers.11.input_layernorm.weight": "pytorch_model-00009-of-00028.bin",
|
| 39 |
+
"model.layers.11.mlp.down_proj.weight": "pytorch_model-00009-of-00028.bin",
|
| 40 |
+
"model.layers.11.mlp.gate_proj.weight": "pytorch_model-00009-of-00028.bin",
|
| 41 |
+
"model.layers.11.mlp.up_proj.weight": "pytorch_model-00009-of-00028.bin",
|
| 42 |
+
"model.layers.11.post_attention_layernorm.weight": "pytorch_model-00009-of-00028.bin",
|
| 43 |
+
"model.layers.11.self_attn.k_proj.weight": "pytorch_model-00008-of-00028.bin",
|
| 44 |
+
"model.layers.11.self_attn.o_proj.weight": "pytorch_model-00008-of-00028.bin",
|
| 45 |
+
"model.layers.11.self_attn.q_proj.weight": "pytorch_model-00008-of-00028.bin",
|
| 46 |
+
"model.layers.11.self_attn.rotary_emb.inv_freq": "pytorch_model-00008-of-00028.bin",
|
| 47 |
+
"model.layers.11.self_attn.v_proj.weight": "pytorch_model-00008-of-00028.bin",
|
| 48 |
+
"model.layers.12.input_layernorm.weight": "pytorch_model-00010-of-00028.bin",
|
| 49 |
+
"model.layers.12.mlp.down_proj.weight": "pytorch_model-00009-of-00028.bin",
|
| 50 |
+
"model.layers.12.mlp.gate_proj.weight": "pytorch_model-00009-of-00028.bin",
|
| 51 |
+
"model.layers.12.mlp.up_proj.weight": "pytorch_model-00010-of-00028.bin",
|
| 52 |
+
"model.layers.12.post_attention_layernorm.weight": "pytorch_model-00010-of-00028.bin",
|
| 53 |
+
"model.layers.12.self_attn.k_proj.weight": "pytorch_model-00009-of-00028.bin",
|
| 54 |
+
"model.layers.12.self_attn.o_proj.weight": "pytorch_model-00009-of-00028.bin",
|
| 55 |
+
"model.layers.12.self_attn.q_proj.weight": "pytorch_model-00009-of-00028.bin",
|
| 56 |
+
"model.layers.12.self_attn.rotary_emb.inv_freq": "pytorch_model-00009-of-00028.bin",
|
| 57 |
+
"model.layers.12.self_attn.v_proj.weight": "pytorch_model-00009-of-00028.bin",
|
| 58 |
+
"model.layers.13.input_layernorm.weight": "pytorch_model-00010-of-00028.bin",
|
| 59 |
+
"model.layers.13.mlp.down_proj.weight": "pytorch_model-00010-of-00028.bin",
|
| 60 |
+
"model.layers.13.mlp.gate_proj.weight": "pytorch_model-00010-of-00028.bin",
|
| 61 |
+
"model.layers.13.mlp.up_proj.weight": "pytorch_model-00010-of-00028.bin",
|
| 62 |
+
"model.layers.13.post_attention_layernorm.weight": "pytorch_model-00010-of-00028.bin",
|
| 63 |
+
"model.layers.13.self_attn.k_proj.weight": "pytorch_model-00010-of-00028.bin",
|
| 64 |
+
"model.layers.13.self_attn.o_proj.weight": "pytorch_model-00010-of-00028.bin",
|
| 65 |
+
"model.layers.13.self_attn.q_proj.weight": "pytorch_model-00010-of-00028.bin",
|
| 66 |
+
"model.layers.13.self_attn.rotary_emb.inv_freq": "pytorch_model-00010-of-00028.bin",
|
| 67 |
+
"model.layers.13.self_attn.v_proj.weight": "pytorch_model-00010-of-00028.bin",
|
| 68 |
+
"model.layers.14.input_layernorm.weight": "pytorch_model-00011-of-00028.bin",
|
| 69 |
+
"model.layers.14.mlp.down_proj.weight": "pytorch_model-00011-of-00028.bin",
|
| 70 |
+
"model.layers.14.mlp.gate_proj.weight": "pytorch_model-00011-of-00028.bin",
|
| 71 |
+
"model.layers.14.mlp.up_proj.weight": "pytorch_model-00011-of-00028.bin",
|
| 72 |
+
"model.layers.14.post_attention_layernorm.weight": "pytorch_model-00011-of-00028.bin",
|
| 73 |
+
"model.layers.14.self_attn.k_proj.weight": "pytorch_model-00010-of-00028.bin",
|
| 74 |
+
"model.layers.14.self_attn.o_proj.weight": "pytorch_model-00010-of-00028.bin",
|
| 75 |
+
"model.layers.14.self_attn.q_proj.weight": "pytorch_model-00010-of-00028.bin",
|
| 76 |
+
"model.layers.14.self_attn.rotary_emb.inv_freq": "pytorch_model-00010-of-00028.bin",
|
| 77 |
+
"model.layers.14.self_attn.v_proj.weight": "pytorch_model-00010-of-00028.bin",
|
| 78 |
+
"model.layers.15.input_layernorm.weight": "pytorch_model-00012-of-00028.bin",
|
| 79 |
+
"model.layers.15.mlp.down_proj.weight": "pytorch_model-00011-of-00028.bin",
|
| 80 |
+
"model.layers.15.mlp.gate_proj.weight": "pytorch_model-00011-of-00028.bin",
|
| 81 |
+
"model.layers.15.mlp.up_proj.weight": "pytorch_model-00012-of-00028.bin",
|
| 82 |
+
"model.layers.15.post_attention_layernorm.weight": "pytorch_model-00012-of-00028.bin",
|
| 83 |
+
"model.layers.15.self_attn.k_proj.weight": "pytorch_model-00011-of-00028.bin",
|
| 84 |
+
"model.layers.15.self_attn.o_proj.weight": "pytorch_model-00011-of-00028.bin",
|
| 85 |
+
"model.layers.15.self_attn.q_proj.weight": "pytorch_model-00011-of-00028.bin",
|
| 86 |
+
"model.layers.15.self_attn.rotary_emb.inv_freq": "pytorch_model-00011-of-00028.bin",
|
| 87 |
+
"model.layers.15.self_attn.v_proj.weight": "pytorch_model-00011-of-00028.bin",
|
| 88 |
+
"model.layers.16.input_layernorm.weight": "pytorch_model-00012-of-00028.bin",
|
| 89 |
+
"model.layers.16.mlp.down_proj.weight": "pytorch_model-00012-of-00028.bin",
|
| 90 |
+
"model.layers.16.mlp.gate_proj.weight": "pytorch_model-00012-of-00028.bin",
|
| 91 |
+
"model.layers.16.mlp.up_proj.weight": "pytorch_model-00012-of-00028.bin",
|
| 92 |
+
"model.layers.16.post_attention_layernorm.weight": "pytorch_model-00012-of-00028.bin",
|
| 93 |
+
"model.layers.16.self_attn.k_proj.weight": "pytorch_model-00012-of-00028.bin",
|
| 94 |
+
"model.layers.16.self_attn.o_proj.weight": "pytorch_model-00012-of-00028.bin",
|
| 95 |
+
"model.layers.16.self_attn.q_proj.weight": "pytorch_model-00012-of-00028.bin",
|
| 96 |
+
"model.layers.16.self_attn.rotary_emb.inv_freq": "pytorch_model-00012-of-00028.bin",
|
| 97 |
+
"model.layers.16.self_attn.v_proj.weight": "pytorch_model-00012-of-00028.bin",
|
| 98 |
+
"model.layers.17.input_layernorm.weight": "pytorch_model-00013-of-00028.bin",
|
| 99 |
+
"model.layers.17.mlp.down_proj.weight": "pytorch_model-00013-of-00028.bin",
|
| 100 |
+
"model.layers.17.mlp.gate_proj.weight": "pytorch_model-00013-of-00028.bin",
|
| 101 |
+
"model.layers.17.mlp.up_proj.weight": "pytorch_model-00013-of-00028.bin",
|
| 102 |
+
"model.layers.17.post_attention_layernorm.weight": "pytorch_model-00013-of-00028.bin",
|
| 103 |
+
"model.layers.17.self_attn.k_proj.weight": "pytorch_model-00012-of-00028.bin",
|
| 104 |
+
"model.layers.17.self_attn.o_proj.weight": "pytorch_model-00012-of-00028.bin",
|
| 105 |
+
"model.layers.17.self_attn.q_proj.weight": "pytorch_model-00012-of-00028.bin",
|
| 106 |
+
"model.layers.17.self_attn.rotary_emb.inv_freq": "pytorch_model-00012-of-00028.bin",
|
| 107 |
+
"model.layers.17.self_attn.v_proj.weight": "pytorch_model-00012-of-00028.bin",
|
| 108 |
+
"model.layers.18.input_layernorm.weight": "pytorch_model-00014-of-00028.bin",
|
| 109 |
+
"model.layers.18.mlp.down_proj.weight": "pytorch_model-00013-of-00028.bin",
|
| 110 |
+
"model.layers.18.mlp.gate_proj.weight": "pytorch_model-00013-of-00028.bin",
|
| 111 |
+
"model.layers.18.mlp.up_proj.weight": "pytorch_model-00014-of-00028.bin",
|
| 112 |
+
"model.layers.18.post_attention_layernorm.weight": "pytorch_model-00014-of-00028.bin",
|
| 113 |
+
"model.layers.18.self_attn.k_proj.weight": "pytorch_model-00013-of-00028.bin",
|
| 114 |
+
"model.layers.18.self_attn.o_proj.weight": "pytorch_model-00013-of-00028.bin",
|
| 115 |
+
"model.layers.18.self_attn.q_proj.weight": "pytorch_model-00013-of-00028.bin",
|
| 116 |
+
"model.layers.18.self_attn.rotary_emb.inv_freq": "pytorch_model-00013-of-00028.bin",
|
| 117 |
+
"model.layers.18.self_attn.v_proj.weight": "pytorch_model-00013-of-00028.bin",
|
| 118 |
+
"model.layers.19.input_layernorm.weight": "pytorch_model-00014-of-00028.bin",
|
| 119 |
+
"model.layers.19.mlp.down_proj.weight": "pytorch_model-00014-of-00028.bin",
|
| 120 |
+
"model.layers.19.mlp.gate_proj.weight": "pytorch_model-00014-of-00028.bin",
|
| 121 |
+
"model.layers.19.mlp.up_proj.weight": "pytorch_model-00014-of-00028.bin",
|
| 122 |
+
"model.layers.19.post_attention_layernorm.weight": "pytorch_model-00014-of-00028.bin",
|
| 123 |
+
"model.layers.19.self_attn.k_proj.weight": "pytorch_model-00014-of-00028.bin",
|
| 124 |
+
"model.layers.19.self_attn.o_proj.weight": "pytorch_model-00014-of-00028.bin",
|
| 125 |
+
"model.layers.19.self_attn.q_proj.weight": "pytorch_model-00014-of-00028.bin",
|
| 126 |
+
"model.layers.19.self_attn.rotary_emb.inv_freq": "pytorch_model-00014-of-00028.bin",
|
| 127 |
+
"model.layers.19.self_attn.v_proj.weight": "pytorch_model-00014-of-00028.bin",
|
| 128 |
+
"model.layers.2.input_layernorm.weight": "pytorch_model-00003-of-00028.bin",
|
| 129 |
+
"model.layers.2.mlp.down_proj.weight": "pytorch_model-00003-of-00028.bin",
|
| 130 |
+
"model.layers.2.mlp.gate_proj.weight": "pytorch_model-00003-of-00028.bin",
|
| 131 |
+
"model.layers.2.mlp.up_proj.weight": "pytorch_model-00003-of-00028.bin",
|
| 132 |
+
"model.layers.2.post_attention_layernorm.weight": "pytorch_model-00003-of-00028.bin",
|
| 133 |
+
"model.layers.2.self_attn.k_proj.weight": "pytorch_model-00002-of-00028.bin",
|
| 134 |
+
"model.layers.2.self_attn.o_proj.weight": "pytorch_model-00002-of-00028.bin",
|
| 135 |
+
"model.layers.2.self_attn.q_proj.weight": "pytorch_model-00002-of-00028.bin",
|
| 136 |
+
"model.layers.2.self_attn.rotary_emb.inv_freq": "pytorch_model-00002-of-00028.bin",
|
| 137 |
+
"model.layers.2.self_attn.v_proj.weight": "pytorch_model-00002-of-00028.bin",
|
| 138 |
+
"model.layers.20.input_layernorm.weight": "pytorch_model-00015-of-00028.bin",
|
| 139 |
+
"model.layers.20.mlp.down_proj.weight": "pytorch_model-00015-of-00028.bin",
|
| 140 |
+
"model.layers.20.mlp.gate_proj.weight": "pytorch_model-00015-of-00028.bin",
|
| 141 |
+
"model.layers.20.mlp.up_proj.weight": "pytorch_model-00015-of-00028.bin",
|
| 142 |
+
"model.layers.20.post_attention_layernorm.weight": "pytorch_model-00015-of-00028.bin",
|
| 143 |
+
"model.layers.20.self_attn.k_proj.weight": "pytorch_model-00014-of-00028.bin",
|
| 144 |
+
"model.layers.20.self_attn.o_proj.weight": "pytorch_model-00014-of-00028.bin",
|
| 145 |
+
"model.layers.20.self_attn.q_proj.weight": "pytorch_model-00014-of-00028.bin",
|
| 146 |
+
"model.layers.20.self_attn.rotary_emb.inv_freq": "pytorch_model-00014-of-00028.bin",
|
| 147 |
+
"model.layers.20.self_attn.v_proj.weight": "pytorch_model-00014-of-00028.bin",
|
| 148 |
+
"model.layers.21.input_layernorm.weight": "pytorch_model-00016-of-00028.bin",
|
| 149 |
+
"model.layers.21.mlp.down_proj.weight": "pytorch_model-00015-of-00028.bin",
|
| 150 |
+
"model.layers.21.mlp.gate_proj.weight": "pytorch_model-00015-of-00028.bin",
|
| 151 |
+
"model.layers.21.mlp.up_proj.weight": "pytorch_model-00016-of-00028.bin",
|
| 152 |
+
"model.layers.21.post_attention_layernorm.weight": "pytorch_model-00016-of-00028.bin",
|
| 153 |
+
"model.layers.21.self_attn.k_proj.weight": "pytorch_model-00015-of-00028.bin",
|
| 154 |
+
"model.layers.21.self_attn.o_proj.weight": "pytorch_model-00015-of-00028.bin",
|
| 155 |
+
"model.layers.21.self_attn.q_proj.weight": "pytorch_model-00015-of-00028.bin",
|
| 156 |
+
"model.layers.21.self_attn.rotary_emb.inv_freq": "pytorch_model-00015-of-00028.bin",
|
| 157 |
+
"model.layers.21.self_attn.v_proj.weight": "pytorch_model-00015-of-00028.bin",
|
| 158 |
+
"model.layers.22.input_layernorm.weight": "pytorch_model-00016-of-00028.bin",
|
| 159 |
+
"model.layers.22.mlp.down_proj.weight": "pytorch_model-00016-of-00028.bin",
|
| 160 |
+
"model.layers.22.mlp.gate_proj.weight": "pytorch_model-00016-of-00028.bin",
|
| 161 |
+
"model.layers.22.mlp.up_proj.weight": "pytorch_model-00016-of-00028.bin",
|
| 162 |
+
"model.layers.22.post_attention_layernorm.weight": "pytorch_model-00016-of-00028.bin",
|
| 163 |
+
"model.layers.22.self_attn.k_proj.weight": "pytorch_model-00016-of-00028.bin",
|
| 164 |
+
"model.layers.22.self_attn.o_proj.weight": "pytorch_model-00016-of-00028.bin",
|
| 165 |
+
"model.layers.22.self_attn.q_proj.weight": "pytorch_model-00016-of-00028.bin",
|
| 166 |
+
"model.layers.22.self_attn.rotary_emb.inv_freq": "pytorch_model-00016-of-00028.bin",
|
| 167 |
+
"model.layers.22.self_attn.v_proj.weight": "pytorch_model-00016-of-00028.bin",
|
| 168 |
+
"model.layers.23.input_layernorm.weight": "pytorch_model-00017-of-00028.bin",
|
| 169 |
+
"model.layers.23.mlp.down_proj.weight": "pytorch_model-00017-of-00028.bin",
|
| 170 |
+
"model.layers.23.mlp.gate_proj.weight": "pytorch_model-00017-of-00028.bin",
|
| 171 |
+
"model.layers.23.mlp.up_proj.weight": "pytorch_model-00017-of-00028.bin",
|
| 172 |
+
"model.layers.23.post_attention_layernorm.weight": "pytorch_model-00017-of-00028.bin",
|
| 173 |
+
"model.layers.23.self_attn.k_proj.weight": "pytorch_model-00016-of-00028.bin",
|
| 174 |
+
"model.layers.23.self_attn.o_proj.weight": "pytorch_model-00016-of-00028.bin",
|
| 175 |
+
"model.layers.23.self_attn.q_proj.weight": "pytorch_model-00016-of-00028.bin",
|
| 176 |
+
"model.layers.23.self_attn.rotary_emb.inv_freq": "pytorch_model-00016-of-00028.bin",
|
| 177 |
+
"model.layers.23.self_attn.v_proj.weight": "pytorch_model-00016-of-00028.bin",
|
| 178 |
+
"model.layers.24.input_layernorm.weight": "pytorch_model-00018-of-00028.bin",
|
| 179 |
+
"model.layers.24.mlp.down_proj.weight": "pytorch_model-00017-of-00028.bin",
|
| 180 |
+
"model.layers.24.mlp.gate_proj.weight": "pytorch_model-00017-of-00028.bin",
|
| 181 |
+
"model.layers.24.mlp.up_proj.weight": "pytorch_model-00018-of-00028.bin",
|
| 182 |
+
"model.layers.24.post_attention_layernorm.weight": "pytorch_model-00018-of-00028.bin",
|
| 183 |
+
"model.layers.24.self_attn.k_proj.weight": "pytorch_model-00017-of-00028.bin",
|
| 184 |
+
"model.layers.24.self_attn.o_proj.weight": "pytorch_model-00017-of-00028.bin",
|
| 185 |
+
"model.layers.24.self_attn.q_proj.weight": "pytorch_model-00017-of-00028.bin",
|
| 186 |
+
"model.layers.24.self_attn.rotary_emb.inv_freq": "pytorch_model-00017-of-00028.bin",
|
| 187 |
+
"model.layers.24.self_attn.v_proj.weight": "pytorch_model-00017-of-00028.bin",
|
| 188 |
+
"model.layers.25.input_layernorm.weight": "pytorch_model-00018-of-00028.bin",
|
| 189 |
+
"model.layers.25.mlp.down_proj.weight": "pytorch_model-00018-of-00028.bin",
|
| 190 |
+
"model.layers.25.mlp.gate_proj.weight": "pytorch_model-00018-of-00028.bin",
|
| 191 |
+
"model.layers.25.mlp.up_proj.weight": "pytorch_model-00018-of-00028.bin",
|
| 192 |
+
"model.layers.25.post_attention_layernorm.weight": "pytorch_model-00018-of-00028.bin",
|
| 193 |
+
"model.layers.25.self_attn.k_proj.weight": "pytorch_model-00018-of-00028.bin",
|
| 194 |
+
"model.layers.25.self_attn.o_proj.weight": "pytorch_model-00018-of-00028.bin",
|
| 195 |
+
"model.layers.25.self_attn.q_proj.weight": "pytorch_model-00018-of-00028.bin",
|
| 196 |
+
"model.layers.25.self_attn.rotary_emb.inv_freq": "pytorch_model-00018-of-00028.bin",
|
| 197 |
+
"model.layers.25.self_attn.v_proj.weight": "pytorch_model-00018-of-00028.bin",
|
| 198 |
+
"model.layers.26.input_layernorm.weight": "pytorch_model-00019-of-00028.bin",
|
| 199 |
+
"model.layers.26.mlp.down_proj.weight": "pytorch_model-00019-of-00028.bin",
|
| 200 |
+
"model.layers.26.mlp.gate_proj.weight": "pytorch_model-00019-of-00028.bin",
|
| 201 |
+
"model.layers.26.mlp.up_proj.weight": "pytorch_model-00019-of-00028.bin",
|
| 202 |
+
"model.layers.26.post_attention_layernorm.weight": "pytorch_model-00019-of-00028.bin",
|
| 203 |
+
"model.layers.26.self_attn.k_proj.weight": "pytorch_model-00018-of-00028.bin",
|
| 204 |
+
"model.layers.26.self_attn.o_proj.weight": "pytorch_model-00018-of-00028.bin",
|
| 205 |
+
"model.layers.26.self_attn.q_proj.weight": "pytorch_model-00018-of-00028.bin",
|
| 206 |
+
"model.layers.26.self_attn.rotary_emb.inv_freq": "pytorch_model-00018-of-00028.bin",
|
| 207 |
+
"model.layers.26.self_attn.v_proj.weight": "pytorch_model-00018-of-00028.bin",
|
| 208 |
+
"model.layers.27.input_layernorm.weight": "pytorch_model-00020-of-00028.bin",
|
| 209 |
+
"model.layers.27.mlp.down_proj.weight": "pytorch_model-00019-of-00028.bin",
|
| 210 |
+
"model.layers.27.mlp.gate_proj.weight": "pytorch_model-00019-of-00028.bin",
|
| 211 |
+
"model.layers.27.mlp.up_proj.weight": "pytorch_model-00020-of-00028.bin",
|
| 212 |
+
"model.layers.27.post_attention_layernorm.weight": "pytorch_model-00020-of-00028.bin",
|
| 213 |
+
"model.layers.27.self_attn.k_proj.weight": "pytorch_model-00019-of-00028.bin",
|
| 214 |
+
"model.layers.27.self_attn.o_proj.weight": "pytorch_model-00019-of-00028.bin",
|
| 215 |
+
"model.layers.27.self_attn.q_proj.weight": "pytorch_model-00019-of-00028.bin",
|
| 216 |
+
"model.layers.27.self_attn.rotary_emb.inv_freq": "pytorch_model-00019-of-00028.bin",
|
| 217 |
+
"model.layers.27.self_attn.v_proj.weight": "pytorch_model-00019-of-00028.bin",
|
| 218 |
+
"model.layers.28.input_layernorm.weight": "pytorch_model-00020-of-00028.bin",
|
| 219 |
+
"model.layers.28.mlp.down_proj.weight": "pytorch_model-00020-of-00028.bin",
|
| 220 |
+
"model.layers.28.mlp.gate_proj.weight": "pytorch_model-00020-of-00028.bin",
|
| 221 |
+
"model.layers.28.mlp.up_proj.weight": "pytorch_model-00020-of-00028.bin",
|
| 222 |
+
"model.layers.28.post_attention_layernorm.weight": "pytorch_model-00020-of-00028.bin",
|
| 223 |
+
"model.layers.28.self_attn.k_proj.weight": "pytorch_model-00020-of-00028.bin",
|
| 224 |
+
"model.layers.28.self_attn.o_proj.weight": "pytorch_model-00020-of-00028.bin",
|
| 225 |
+
"model.layers.28.self_attn.q_proj.weight": "pytorch_model-00020-of-00028.bin",
|
| 226 |
+
"model.layers.28.self_attn.rotary_emb.inv_freq": "pytorch_model-00020-of-00028.bin",
|
| 227 |
+
"model.layers.28.self_attn.v_proj.weight": "pytorch_model-00020-of-00028.bin",
|
| 228 |
+
"model.layers.29.input_layernorm.weight": "pytorch_model-00021-of-00028.bin",
|
| 229 |
+
"model.layers.29.mlp.down_proj.weight": "pytorch_model-00021-of-00028.bin",
|
| 230 |
+
"model.layers.29.mlp.gate_proj.weight": "pytorch_model-00021-of-00028.bin",
|
| 231 |
+
"model.layers.29.mlp.up_proj.weight": "pytorch_model-00021-of-00028.bin",
|
| 232 |
+
"model.layers.29.post_attention_layernorm.weight": "pytorch_model-00021-of-00028.bin",
|
| 233 |
+
"model.layers.29.self_attn.k_proj.weight": "pytorch_model-00020-of-00028.bin",
|
| 234 |
+
"model.layers.29.self_attn.o_proj.weight": "pytorch_model-00020-of-00028.bin",
|
| 235 |
+
"model.layers.29.self_attn.q_proj.weight": "pytorch_model-00020-of-00028.bin",
|
| 236 |
+
"model.layers.29.self_attn.rotary_emb.inv_freq": "pytorch_model-00020-of-00028.bin",
|
| 237 |
+
"model.layers.29.self_attn.v_proj.weight": "pytorch_model-00020-of-00028.bin",
|
| 238 |
+
"model.layers.3.input_layernorm.weight": "pytorch_model-00004-of-00028.bin",
|
| 239 |
+
"model.layers.3.mlp.down_proj.weight": "pytorch_model-00003-of-00028.bin",
|
| 240 |
+
"model.layers.3.mlp.gate_proj.weight": "pytorch_model-00003-of-00028.bin",
|
| 241 |
+
"model.layers.3.mlp.up_proj.weight": "pytorch_model-00004-of-00028.bin",
|
| 242 |
+
"model.layers.3.post_attention_layernorm.weight": "pytorch_model-00004-of-00028.bin",
|
| 243 |
+
"model.layers.3.self_attn.k_proj.weight": "pytorch_model-00003-of-00028.bin",
|
| 244 |
+
"model.layers.3.self_attn.o_proj.weight": "pytorch_model-00003-of-00028.bin",
|
| 245 |
+
"model.layers.3.self_attn.q_proj.weight": "pytorch_model-00003-of-00028.bin",
|
| 246 |
+
"model.layers.3.self_attn.rotary_emb.inv_freq": "pytorch_model-00003-of-00028.bin",
|
| 247 |
+
"model.layers.3.self_attn.v_proj.weight": "pytorch_model-00003-of-00028.bin",
|
| 248 |
+
"model.layers.30.input_layernorm.weight": "pytorch_model-00022-of-00028.bin",
|
| 249 |
+
"model.layers.30.mlp.down_proj.weight": "pytorch_model-00021-of-00028.bin",
|
| 250 |
+
"model.layers.30.mlp.gate_proj.weight": "pytorch_model-00021-of-00028.bin",
|
| 251 |
+
"model.layers.30.mlp.up_proj.weight": "pytorch_model-00022-of-00028.bin",
|
| 252 |
+
"model.layers.30.post_attention_layernorm.weight": "pytorch_model-00022-of-00028.bin",
|
| 253 |
+
"model.layers.30.self_attn.k_proj.weight": "pytorch_model-00021-of-00028.bin",
|
| 254 |
+
"model.layers.30.self_attn.o_proj.weight": "pytorch_model-00021-of-00028.bin",
|
| 255 |
+
"model.layers.30.self_attn.q_proj.weight": "pytorch_model-00021-of-00028.bin",
|
| 256 |
+
"model.layers.30.self_attn.rotary_emb.inv_freq": "pytorch_model-00021-of-00028.bin",
|
| 257 |
+
"model.layers.30.self_attn.v_proj.weight": "pytorch_model-00021-of-00028.bin",
|
| 258 |
+
"model.layers.31.input_layernorm.weight": "pytorch_model-00022-of-00028.bin",
|
| 259 |
+
"model.layers.31.mlp.down_proj.weight": "pytorch_model-00022-of-00028.bin",
|
| 260 |
+
"model.layers.31.mlp.gate_proj.weight": "pytorch_model-00022-of-00028.bin",
|
| 261 |
+
"model.layers.31.mlp.up_proj.weight": "pytorch_model-00022-of-00028.bin",
|
| 262 |
+
"model.layers.31.post_attention_layernorm.weight": "pytorch_model-00022-of-00028.bin",
|
| 263 |
+
"model.layers.31.self_attn.k_proj.weight": "pytorch_model-00022-of-00028.bin",
|
| 264 |
+
"model.layers.31.self_attn.o_proj.weight": "pytorch_model-00022-of-00028.bin",
|
| 265 |
+
"model.layers.31.self_attn.q_proj.weight": "pytorch_model-00022-of-00028.bin",
|
| 266 |
+
"model.layers.31.self_attn.rotary_emb.inv_freq": "pytorch_model-00022-of-00028.bin",
|
| 267 |
+
"model.layers.31.self_attn.v_proj.weight": "pytorch_model-00022-of-00028.bin",
|
| 268 |
+
"model.layers.32.input_layernorm.weight": "pytorch_model-00023-of-00028.bin",
|
| 269 |
+
"model.layers.32.mlp.down_proj.weight": "pytorch_model-00023-of-00028.bin",
|
| 270 |
+
"model.layers.32.mlp.gate_proj.weight": "pytorch_model-00023-of-00028.bin",
|
| 271 |
+
"model.layers.32.mlp.up_proj.weight": "pytorch_model-00023-of-00028.bin",
|
| 272 |
+
"model.layers.32.post_attention_layernorm.weight": "pytorch_model-00023-of-00028.bin",
|
| 273 |
+
"model.layers.32.self_attn.k_proj.weight": "pytorch_model-00022-of-00028.bin",
|
| 274 |
+
"model.layers.32.self_attn.o_proj.weight": "pytorch_model-00022-of-00028.bin",
|
| 275 |
+
"model.layers.32.self_attn.q_proj.weight": "pytorch_model-00022-of-00028.bin",
|
| 276 |
+
"model.layers.32.self_attn.rotary_emb.inv_freq": "pytorch_model-00022-of-00028.bin",
|
| 277 |
+
"model.layers.32.self_attn.v_proj.weight": "pytorch_model-00022-of-00028.bin",
|
| 278 |
+
"model.layers.33.input_layernorm.weight": "pytorch_model-00024-of-00028.bin",
|
| 279 |
+
"model.layers.33.mlp.down_proj.weight": "pytorch_model-00023-of-00028.bin",
|
| 280 |
+
"model.layers.33.mlp.gate_proj.weight": "pytorch_model-00023-of-00028.bin",
|
| 281 |
+
"model.layers.33.mlp.up_proj.weight": "pytorch_model-00024-of-00028.bin",
|
| 282 |
+
"model.layers.33.post_attention_layernorm.weight": "pytorch_model-00024-of-00028.bin",
|
| 283 |
+
"model.layers.33.self_attn.k_proj.weight": "pytorch_model-00023-of-00028.bin",
|
| 284 |
+
"model.layers.33.self_attn.o_proj.weight": "pytorch_model-00023-of-00028.bin",
|
| 285 |
+
"model.layers.33.self_attn.q_proj.weight": "pytorch_model-00023-of-00028.bin",
|
| 286 |
+
"model.layers.33.self_attn.rotary_emb.inv_freq": "pytorch_model-00023-of-00028.bin",
|
| 287 |
+
"model.layers.33.self_attn.v_proj.weight": "pytorch_model-00023-of-00028.bin",
|
| 288 |
+
"model.layers.34.input_layernorm.weight": "pytorch_model-00024-of-00028.bin",
|
| 289 |
+
"model.layers.34.mlp.down_proj.weight": "pytorch_model-00024-of-00028.bin",
|
| 290 |
+
"model.layers.34.mlp.gate_proj.weight": "pytorch_model-00024-of-00028.bin",
|
| 291 |
+
"model.layers.34.mlp.up_proj.weight": "pytorch_model-00024-of-00028.bin",
|
| 292 |
+
"model.layers.34.post_attention_layernorm.weight": "pytorch_model-00024-of-00028.bin",
|
| 293 |
+
"model.layers.34.self_attn.k_proj.weight": "pytorch_model-00024-of-00028.bin",
|
| 294 |
+
"model.layers.34.self_attn.o_proj.weight": "pytorch_model-00024-of-00028.bin",
|
| 295 |
+
"model.layers.34.self_attn.q_proj.weight": "pytorch_model-00024-of-00028.bin",
|
| 296 |
+
"model.layers.34.self_attn.rotary_emb.inv_freq": "pytorch_model-00024-of-00028.bin",
|
| 297 |
+
"model.layers.34.self_attn.v_proj.weight": "pytorch_model-00024-of-00028.bin",
|
| 298 |
+
"model.layers.35.input_layernorm.weight": "pytorch_model-00025-of-00028.bin",
|
| 299 |
+
"model.layers.35.mlp.down_proj.weight": "pytorch_model-00025-of-00028.bin",
|
| 300 |
+
"model.layers.35.mlp.gate_proj.weight": "pytorch_model-00025-of-00028.bin",
|
| 301 |
+
"model.layers.35.mlp.up_proj.weight": "pytorch_model-00025-of-00028.bin",
|
| 302 |
+
"model.layers.35.post_attention_layernorm.weight": "pytorch_model-00025-of-00028.bin",
|
| 303 |
+
"model.layers.35.self_attn.k_proj.weight": "pytorch_model-00024-of-00028.bin",
|
| 304 |
+
"model.layers.35.self_attn.o_proj.weight": "pytorch_model-00024-of-00028.bin",
|
| 305 |
+
"model.layers.35.self_attn.q_proj.weight": "pytorch_model-00024-of-00028.bin",
|
| 306 |
+
"model.layers.35.self_attn.rotary_emb.inv_freq": "pytorch_model-00024-of-00028.bin",
|
| 307 |
+
"model.layers.35.self_attn.v_proj.weight": "pytorch_model-00024-of-00028.bin",
|
| 308 |
+
"model.layers.36.input_layernorm.weight": "pytorch_model-00026-of-00028.bin",
|
| 309 |
+
"model.layers.36.mlp.down_proj.weight": "pytorch_model-00025-of-00028.bin",
|
| 310 |
+
"model.layers.36.mlp.gate_proj.weight": "pytorch_model-00025-of-00028.bin",
|
| 311 |
+
"model.layers.36.mlp.up_proj.weight": "pytorch_model-00026-of-00028.bin",
|
| 312 |
+
"model.layers.36.post_attention_layernorm.weight": "pytorch_model-00026-of-00028.bin",
|
| 313 |
+
"model.layers.36.self_attn.k_proj.weight": "pytorch_model-00025-of-00028.bin",
|
| 314 |
+
"model.layers.36.self_attn.o_proj.weight": "pytorch_model-00025-of-00028.bin",
|
| 315 |
+
"model.layers.36.self_attn.q_proj.weight": "pytorch_model-00025-of-00028.bin",
|
| 316 |
+
"model.layers.36.self_attn.rotary_emb.inv_freq": "pytorch_model-00025-of-00028.bin",
|
| 317 |
+
"model.layers.36.self_attn.v_proj.weight": "pytorch_model-00025-of-00028.bin",
|
| 318 |
+
"model.layers.37.input_layernorm.weight": "pytorch_model-00026-of-00028.bin",
|
| 319 |
+
"model.layers.37.mlp.down_proj.weight": "pytorch_model-00026-of-00028.bin",
|
| 320 |
+
"model.layers.37.mlp.gate_proj.weight": "pytorch_model-00026-of-00028.bin",
|
| 321 |
+
"model.layers.37.mlp.up_proj.weight": "pytorch_model-00026-of-00028.bin",
|
| 322 |
+
"model.layers.37.post_attention_layernorm.weight": "pytorch_model-00026-of-00028.bin",
|
| 323 |
+
"model.layers.37.self_attn.k_proj.weight": "pytorch_model-00026-of-00028.bin",
|
| 324 |
+
"model.layers.37.self_attn.o_proj.weight": "pytorch_model-00026-of-00028.bin",
|
| 325 |
+
"model.layers.37.self_attn.q_proj.weight": "pytorch_model-00026-of-00028.bin",
|
| 326 |
+
"model.layers.37.self_attn.rotary_emb.inv_freq": "pytorch_model-00026-of-00028.bin",
|
| 327 |
+
"model.layers.37.self_attn.v_proj.weight": "pytorch_model-00026-of-00028.bin",
|
| 328 |
+
"model.layers.38.input_layernorm.weight": "pytorch_model-00027-of-00028.bin",
|
| 329 |
+
"model.layers.38.mlp.down_proj.weight": "pytorch_model-00027-of-00028.bin",
|
| 330 |
+
"model.layers.38.mlp.gate_proj.weight": "pytorch_model-00027-of-00028.bin",
|
| 331 |
+
"model.layers.38.mlp.up_proj.weight": "pytorch_model-00027-of-00028.bin",
|
| 332 |
+
"model.layers.38.post_attention_layernorm.weight": "pytorch_model-00027-of-00028.bin",
|
| 333 |
+
"model.layers.38.self_attn.k_proj.weight": "pytorch_model-00026-of-00028.bin",
|
| 334 |
+
"model.layers.38.self_attn.o_proj.weight": "pytorch_model-00026-of-00028.bin",
|
| 335 |
+
"model.layers.38.self_attn.q_proj.weight": "pytorch_model-00026-of-00028.bin",
|
| 336 |
+
"model.layers.38.self_attn.rotary_emb.inv_freq": "pytorch_model-00026-of-00028.bin",
|
| 337 |
+
"model.layers.38.self_attn.v_proj.weight": "pytorch_model-00026-of-00028.bin",
|
| 338 |
+
"model.layers.39.input_layernorm.weight": "pytorch_model-00028-of-00028.bin",
|
| 339 |
+
"model.layers.39.mlp.down_proj.weight": "pytorch_model-00027-of-00028.bin",
|
| 340 |
+
"model.layers.39.mlp.gate_proj.weight": "pytorch_model-00027-of-00028.bin",
|
| 341 |
+
"model.layers.39.mlp.up_proj.weight": "pytorch_model-00028-of-00028.bin",
|
| 342 |
+
"model.layers.39.post_attention_layernorm.weight": "pytorch_model-00028-of-00028.bin",
|
| 343 |
+
"model.layers.39.self_attn.k_proj.weight": "pytorch_model-00027-of-00028.bin",
|
| 344 |
+
"model.layers.39.self_attn.o_proj.weight": "pytorch_model-00027-of-00028.bin",
|
| 345 |
+
"model.layers.39.self_attn.q_proj.weight": "pytorch_model-00027-of-00028.bin",
|
| 346 |
+
"model.layers.39.self_attn.rotary_emb.inv_freq": "pytorch_model-00027-of-00028.bin",
|
| 347 |
+
"model.layers.39.self_attn.v_proj.weight": "pytorch_model-00027-of-00028.bin",
|
| 348 |
+
"model.layers.4.input_layernorm.weight": "pytorch_model-00004-of-00028.bin",
|
| 349 |
+
"model.layers.4.mlp.down_proj.weight": "pytorch_model-00004-of-00028.bin",
|
| 350 |
+
"model.layers.4.mlp.gate_proj.weight": "pytorch_model-00004-of-00028.bin",
|
| 351 |
+
"model.layers.4.mlp.up_proj.weight": "pytorch_model-00004-of-00028.bin",
|
| 352 |
+
"model.layers.4.post_attention_layernorm.weight": "pytorch_model-00004-of-00028.bin",
|
| 353 |
+
"model.layers.4.self_attn.k_proj.weight": "pytorch_model-00004-of-00028.bin",
|
| 354 |
+
"model.layers.4.self_attn.o_proj.weight": "pytorch_model-00004-of-00028.bin",
|
| 355 |
+
"model.layers.4.self_attn.q_proj.weight": "pytorch_model-00004-of-00028.bin",
|
| 356 |
+
"model.layers.4.self_attn.rotary_emb.inv_freq": "pytorch_model-00004-of-00028.bin",
|
| 357 |
+
"model.layers.4.self_attn.v_proj.weight": "pytorch_model-00004-of-00028.bin",
|
| 358 |
+
"model.layers.5.input_layernorm.weight": "pytorch_model-00005-of-00028.bin",
|
| 359 |
+
"model.layers.5.mlp.down_proj.weight": "pytorch_model-00005-of-00028.bin",
|
| 360 |
+
"model.layers.5.mlp.gate_proj.weight": "pytorch_model-00005-of-00028.bin",
|
| 361 |
+
"model.layers.5.mlp.up_proj.weight": "pytorch_model-00005-of-00028.bin",
|
| 362 |
+
"model.layers.5.post_attention_layernorm.weight": "pytorch_model-00005-of-00028.bin",
|
| 363 |
+
"model.layers.5.self_attn.k_proj.weight": "pytorch_model-00004-of-00028.bin",
|
| 364 |
+
"model.layers.5.self_attn.o_proj.weight": "pytorch_model-00004-of-00028.bin",
|
| 365 |
+
"model.layers.5.self_attn.q_proj.weight": "pytorch_model-00004-of-00028.bin",
|
| 366 |
+
"model.layers.5.self_attn.rotary_emb.inv_freq": "pytorch_model-00004-of-00028.bin",
|
| 367 |
+
"model.layers.5.self_attn.v_proj.weight": "pytorch_model-00004-of-00028.bin",
|
| 368 |
+
"model.layers.6.input_layernorm.weight": "pytorch_model-00006-of-00028.bin",
|
| 369 |
+
"model.layers.6.mlp.down_proj.weight": "pytorch_model-00005-of-00028.bin",
|
| 370 |
+
"model.layers.6.mlp.gate_proj.weight": "pytorch_model-00005-of-00028.bin",
|
| 371 |
+
"model.layers.6.mlp.up_proj.weight": "pytorch_model-00006-of-00028.bin",
|
| 372 |
+
"model.layers.6.post_attention_layernorm.weight": "pytorch_model-00006-of-00028.bin",
|
| 373 |
+
"model.layers.6.self_attn.k_proj.weight": "pytorch_model-00005-of-00028.bin",
|
| 374 |
+
"model.layers.6.self_attn.o_proj.weight": "pytorch_model-00005-of-00028.bin",
|
| 375 |
+
"model.layers.6.self_attn.q_proj.weight": "pytorch_model-00005-of-00028.bin",
|
| 376 |
+
"model.layers.6.self_attn.rotary_emb.inv_freq": "pytorch_model-00005-of-00028.bin",
|
| 377 |
+
"model.layers.6.self_attn.v_proj.weight": "pytorch_model-00005-of-00028.bin",
|
| 378 |
+
"model.layers.7.input_layernorm.weight": "pytorch_model-00006-of-00028.bin",
|
| 379 |
+
"model.layers.7.mlp.down_proj.weight": "pytorch_model-00006-of-00028.bin",
|
| 380 |
+
"model.layers.7.mlp.gate_proj.weight": "pytorch_model-00006-of-00028.bin",
|
| 381 |
+
"model.layers.7.mlp.up_proj.weight": "pytorch_model-00006-of-00028.bin",
|
| 382 |
+
"model.layers.7.post_attention_layernorm.weight": "pytorch_model-00006-of-00028.bin",
|
| 383 |
+
"model.layers.7.self_attn.k_proj.weight": "pytorch_model-00006-of-00028.bin",
|
| 384 |
+
"model.layers.7.self_attn.o_proj.weight": "pytorch_model-00006-of-00028.bin",
|
| 385 |
+
"model.layers.7.self_attn.q_proj.weight": "pytorch_model-00006-of-00028.bin",
|
| 386 |
+
"model.layers.7.self_attn.rotary_emb.inv_freq": "pytorch_model-00006-of-00028.bin",
|
| 387 |
+
"model.layers.7.self_attn.v_proj.weight": "pytorch_model-00006-of-00028.bin",
|
| 388 |
+
"model.layers.8.input_layernorm.weight": "pytorch_model-00007-of-00028.bin",
|
| 389 |
+
"model.layers.8.mlp.down_proj.weight": "pytorch_model-00007-of-00028.bin",
|
| 390 |
+
"model.layers.8.mlp.gate_proj.weight": "pytorch_model-00007-of-00028.bin",
|
| 391 |
+
"model.layers.8.mlp.up_proj.weight": "pytorch_model-00007-of-00028.bin",
|
| 392 |
+
"model.layers.8.post_attention_layernorm.weight": "pytorch_model-00007-of-00028.bin",
|
| 393 |
+
"model.layers.8.self_attn.k_proj.weight": "pytorch_model-00006-of-00028.bin",
|
| 394 |
+
"model.layers.8.self_attn.o_proj.weight": "pytorch_model-00006-of-00028.bin",
|
| 395 |
+
"model.layers.8.self_attn.q_proj.weight": "pytorch_model-00006-of-00028.bin",
|
| 396 |
+
"model.layers.8.self_attn.rotary_emb.inv_freq": "pytorch_model-00006-of-00028.bin",
|
| 397 |
+
"model.layers.8.self_attn.v_proj.weight": "pytorch_model-00006-of-00028.bin",
|
| 398 |
+
"model.layers.9.input_layernorm.weight": "pytorch_model-00008-of-00028.bin",
|
| 399 |
+
"model.layers.9.mlp.down_proj.weight": "pytorch_model-00007-of-00028.bin",
|
| 400 |
+
"model.layers.9.mlp.gate_proj.weight": "pytorch_model-00007-of-00028.bin",
|
| 401 |
+
"model.layers.9.mlp.up_proj.weight": "pytorch_model-00008-of-00028.bin",
|
| 402 |
+
"model.layers.9.post_attention_layernorm.weight": "pytorch_model-00008-of-00028.bin",
|
| 403 |
+
"model.layers.9.self_attn.k_proj.weight": "pytorch_model-00007-of-00028.bin",
|
| 404 |
+
"model.layers.9.self_attn.o_proj.weight": "pytorch_model-00007-of-00028.bin",
|
| 405 |
+
"model.layers.9.self_attn.q_proj.weight": "pytorch_model-00007-of-00028.bin",
|
| 406 |
+
"model.layers.9.self_attn.rotary_emb.inv_freq": "pytorch_model-00007-of-00028.bin",
|
| 407 |
+
"model.layers.9.self_attn.v_proj.weight": "pytorch_model-00007-of-00028.bin",
|
| 408 |
+
"model.norm.weight": "pytorch_model-00028-of-00028.bin"
|
| 409 |
+
}
|
| 410 |
+
}
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,39 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"additional_special_tokens": [
|
| 3 |
+
{
|
| 4 |
+
"content": "<human>",
|
| 5 |
+
"lstrip": false,
|
| 6 |
+
"normalized": true,
|
| 7 |
+
"rstrip": false,
|
| 8 |
+
"single_word": false
|
| 9 |
+
},
|
| 10 |
+
{
|
| 11 |
+
"content": "<bot>",
|
| 12 |
+
"lstrip": false,
|
| 13 |
+
"normalized": true,
|
| 14 |
+
"rstrip": false,
|
| 15 |
+
"single_word": false
|
| 16 |
+
}
|
| 17 |
+
],
|
| 18 |
+
"bos_token": {
|
| 19 |
+
"content": "<s>",
|
| 20 |
+
"lstrip": false,
|
| 21 |
+
"normalized": true,
|
| 22 |
+
"rstrip": false,
|
| 23 |
+
"single_word": false
|
| 24 |
+
},
|
| 25 |
+
"eos_token": {
|
| 26 |
+
"content": "</s>",
|
| 27 |
+
"lstrip": false,
|
| 28 |
+
"normalized": true,
|
| 29 |
+
"rstrip": false,
|
| 30 |
+
"single_word": false
|
| 31 |
+
},
|
| 32 |
+
"unk_token": {
|
| 33 |
+
"content": "<unk>",
|
| 34 |
+
"lstrip": false,
|
| 35 |
+
"normalized": true,
|
| 36 |
+
"rstrip": false,
|
| 37 |
+
"single_word": false
|
| 38 |
+
}
|
| 39 |
+
}
|
tokenizer.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6fd7e445833dd0889206aba242c2a51ecbae2437fd328d1759a35475fd8c0423
|
| 3 |
+
size 588619
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_bos_token": true,
|
| 3 |
+
"add_eos_token": false,
|
| 4 |
+
"bos_token": {
|
| 5 |
+
"__type": "AddedToken",
|
| 6 |
+
"content": "<s>",
|
| 7 |
+
"lstrip": false,
|
| 8 |
+
"normalized": true,
|
| 9 |
+
"rstrip": false,
|
| 10 |
+
"single_word": false
|
| 11 |
+
},
|
| 12 |
+
"clean_up_tokenization_spaces": false,
|
| 13 |
+
"eos_token": {
|
| 14 |
+
"__type": "AddedToken",
|
| 15 |
+
"content": "</s>",
|
| 16 |
+
"lstrip": false,
|
| 17 |
+
"normalized": true,
|
| 18 |
+
"rstrip": false,
|
| 19 |
+
"single_word": false
|
| 20 |
+
},
|
| 21 |
+
"model_max_length": 1000000000000000019884624838656,
|
| 22 |
+
"pad_token": null,
|
| 23 |
+
"sp_model_kwargs": {},
|
| 24 |
+
"tokenizer_class": "LlamaTokenizer",
|
| 25 |
+
"unk_token": {
|
| 26 |
+
"__type": "AddedToken",
|
| 27 |
+
"content": "<unk>",
|
| 28 |
+
"lstrip": false,
|
| 29 |
+
"normalized": true,
|
| 30 |
+
"rstrip": false,
|
| 31 |
+
"single_word": false
|
| 32 |
+
}
|
| 33 |
+
}
|